:honeybee: Buzz Rust :honeybee:
![]()
![]()
![]()
Warning This project is a POC and is not actively maintained. It's dependencies are outdated, which might introduce security vulnerabilities.
Buzz is best defined by the following key concepts:
- Interactive analytics query engine, it quickly computes statistics or performs searches on huge amounts of data.
- Cloud serverless, it does not use any resource when idle, but can scale instantly (and massively) to respond to incoming requests.
Functionally, it can be compared to the managed analytics query services offered by all major cloud providers, but differs in that it is open source and uses lower-level components such as cloud functions and cloud storage.
The current implementation is in Rust and is based on Apache Arrow with the DataFusion engine.
Architecture
Buzz is composed of three systems:
- :honeybee: the HBees: cloud function workers that fetch data from the cloud storage and pre-aggregate it. They perform perform a highly scalable map operation on the data.
- :honey_pot: the HCombs: container based reducers that collect the intermediate state from the hbees and finialize the aggregation. They perform a low latency reduce operation on the data.
- :sparkler: the Fuse: a cloud function entrypoint that acts as scheduler and resource manager for a given query.
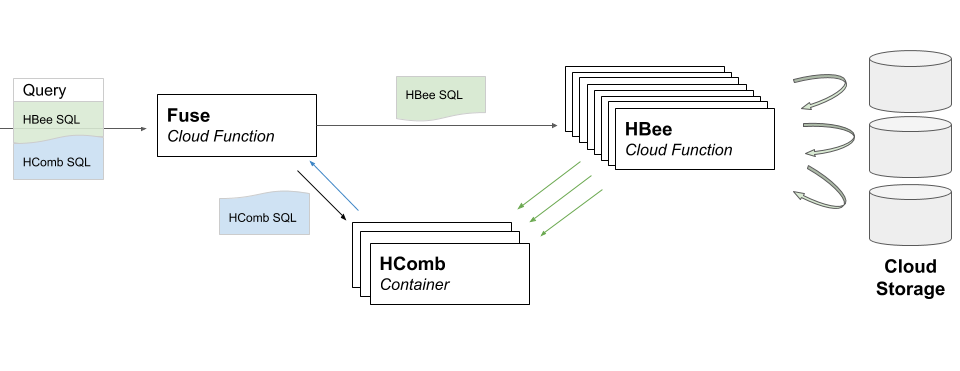
Buzz analytics queries are defined with SQL. The query is composed of different statements for the different stages (see example here). This is different from most distributed engines that have a scheduler that takes care of splitting a unique SQL query into multiple stages to be executed on different executors. The reason is that in Buzz, our executors (HBees and HCombs) have very different behaviors and capabilities. This is unusual and designing a query planner that understands this is not obvious. We prefer leaving it to our dear users, who are notoriously known to be smart, to decide what part of the query should be executed where. Further down the road, we might come up with a scheduler that is able to figure this out automatically.
Note: the h in hbee and hcomb stands for honey, of course ! :smiley:
Tooling
The Makefile contains all the usefull commands to build, deploy and test-run Buzz, so you will likely need make to be installed.
Because Buzz is a cloud native query engine, many commands require an AWS account to be run. The Makefile uses the credentials stored in your ~/.aws/credentials file (cf. doc) to access your cloud accounts on your behalf.
When running commands from the Makefile, you will be prompted to specify the profiles (from the AWS creds file), region and stage you whish to use. If you don't want to specify these each time you run a make command, you can specify defaults by creating a file named default.env at the root of the project with the following content:
REGION:=eu-west-1|us-east-1|...
DEPLOY_PROFILE:=profile-where-buzz-will-be-deployed
BACKEND_PROFILE:=profile-that-has-access-to-the-s3-terraform-backend
STAGE:=dev|prod|...Build
Build commands can be found in the Makefile.
The AWS Lambda runtime runs a custom version of linux. To keep ourselves out of trouble we use musl instead of libc to make a static build. For reproducibility reasons, this build is done through docker.
Note: docker builds require BuildKit (included in docker 18.09+) and the Docker Engine API 1.40+ with experimental features activated.
Deploy
The code can be deployed to AWS through terraform:
- you need to configure your
~/.aws/credentials - terraform is configured to use the S3 backend, so your backend AWS profile (
BACKEND_PROFILE) should have access to a bucket where you will store your state. This bucket needs to be setup manually - you can customize properties (like networking or tags) relative to each stage in the
infra/env/conf.tffiles. Default settings should be sufficient in most cases. - you first need to init your terraform workspace. You will be prompted for:
- the
STAGE(dev/prod/...) so the associated terraform workspace can be created and the associated configs loaded. - the
BACKEND_PROFILE
- the
- you also need to login docker to your ECR repository with
make docker-login. For this to work, you need the AWS cli v2+ to be installed. - you can then deploy the Buzz resources. You will be prompted for
- the
STAGE - the
DEPLOY_PROFILEcorresponding to the creds of the account where you want to deploy - the
BACKEND_PROFILE
- the
- if you want to cleanup you AWS account, you can run the destroy command. Buzz is a serverless query engine, so it should not consume many paying resources when it is not used. But there might be some residual costs (that we aim to reduce to 0) as long as the stack is kept in place.
Notes:
- remember that you can specify the
default.envfile to avoid being prompted at each command - backend and deploy profiles can be the same. In this case both the terraform backend and the buzz stack will reside in the same AWS account
- Some resources might not be completely initialized after the terraform script completes. It generates errors such as
(AccessDeniedException) when calling the Invoke operation. In that case wait a few minutes and try again.
Running queries
To run queries using the Makefile, you need the AWS cli v2+ to be installed.
Example query (cf. code/examples/query-delta-taxi.json):
{
"steps": [
{
"sql": "SELECT payment_type, COUNT(payment_type) as payment_type_count FROM nyc_taxi GROUP BY payment_type",
"name": "nyc_taxi_map",
"step_type": "HBee",
"partition_filter": "pickup_date<='2009-01-05'"
},
{
"sql": "SELECT payment_type, SUM(payment_type_count) FROM nyc_taxi_map GROUP BY payment_type",
"name": "nyc_taxi_reduce",
"step_type": "HComb"
}
],
"capacity": {
"zones": 1
},
"catalogs": [
{
"name": "nyc_taxi",
"type": "DeltaLake",
"uri": "s3://cloudfuse-taxi-data/delta-tables/nyc-taxi-daily"
}
]
}A query is a succession of steps. The HBee step type means that this part of the query runs in cloud functions (e.g AWS Lambda). The HComb step type means the associated query part runs on the container reducers (e.g AWS Fargate). The output of one step should be used as input (FROM statement) of the next step by refering to it by the step's name.
A query takes the target list of file from a catalog. Supported catalogs are Static (file list compiled into the binary) and DeltaLake.
The capacity.zone field indicates the number of availability zones (and thus containers) used for HComb steps. This can be used to improve reducing capability and minimize cross-AZ data exchanges (both slower and more expensive).
In the HBee step, you can specify a partition_filter field with an SQL filtering expression on partitioning dimensions. Currently partition values can only be strings.
Current limitations:
- only SQL supported by DataFusion is supported by Buzz
- only single zone capacity is supported
- only two-step queries are supported (
HBeethenHComb) - only single datasource queries can be run (no join)
- a Buzz stack can only read S3 in its own region (because of S3 Gateway Endpoint)
Note that the first query is slow (and might even timeout!) because it first needs to start a container for the HComb, which typically takes 15-25s on Fargate. Subsequent queries are much faster because they reuse the HComb container. The HComb is stopped after a configurable duration of inactivity (typically 5 minutes).