Pycorels

Welcome to the python binding of the Certifiably Optimal RulE ListS (CORELS) algorithm!
Overview
CORELS (Certifiably Optimal RulE ListS) is a custom discrete optimization technique for building rule lists over a categorical feature space. Using algorithmic bounds and efficient data structures, our approach produces optimal rule lists on practical problems in seconds.
The CORELS pipeline is simple. Given a dataset matrix of size n_samples x n_features and a labels vector of size n_samples, it will compute a rulelist (similar to a series of if-then statements) to predict the labels with the highest accuracy.
Here's an example:
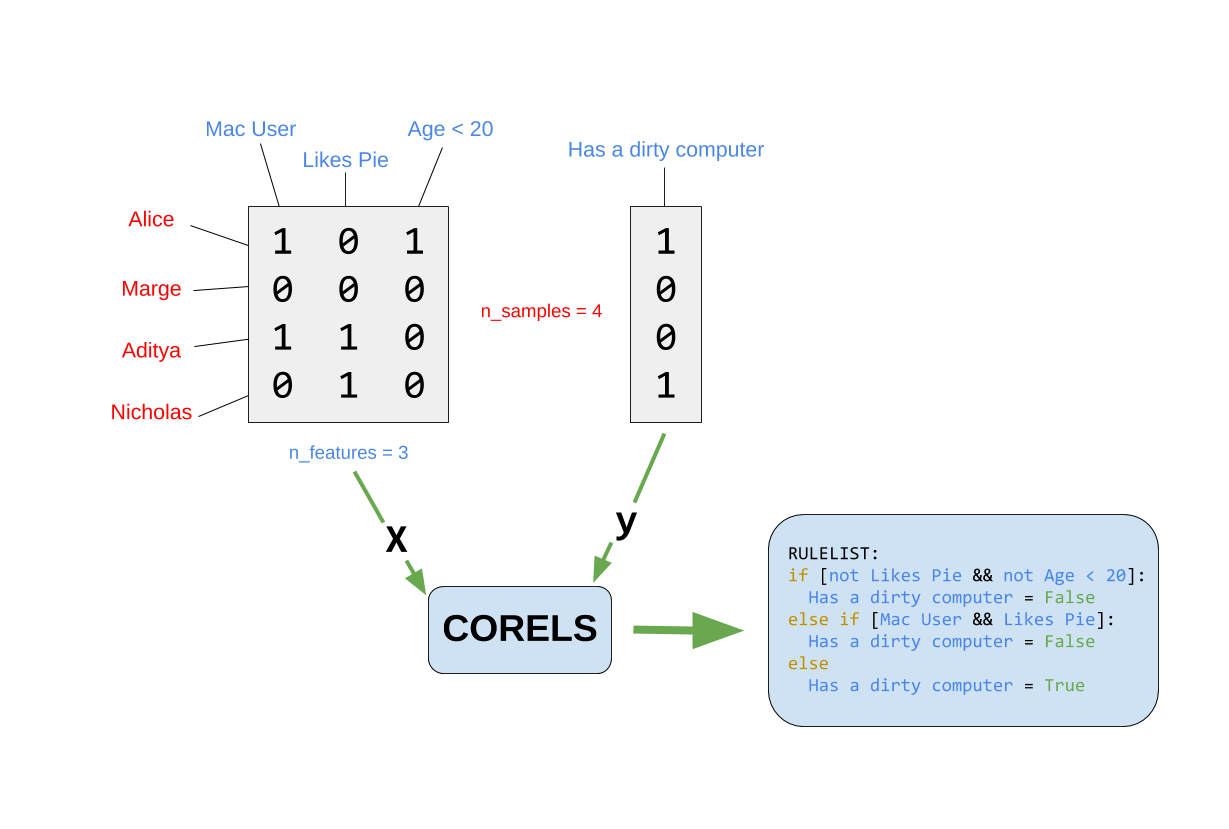
More information about the algorithm can be found here
Dependencies
CORELS uses Python, Numpy, GMP. GMP (GNU Multiple Precision library) is not required, but it is highly recommended, as it improves performance. If it is not installed, CORELS will run slower.
Installation
CORELS exists on PyPI, and can be downloaded with
pip install corels
To install from this repo, simply run pip install . or python setup.py install from the corels/ directory.
Here are some detailed examples of how to install all the dependencies needed, followed by corels itself:
Ubuntu
sudo apt install libgmp-dev
pip install corelsMac
# Install g++ and gmp
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
brew install g++ gmp
pip install corelsWindows
Note: Python 2 is currently NOT supported on Windows.
pip install corelsTroubleshooting
- If you come across an error saying Python version >=3.5 is required, try running
pip install numpybefore again runningpip install corels. - If
pipdoes not successfully install corels, try usingpip3
Documentation
The docs for this package are hosted on here: https://pycorels.readthedocs.io/
Tests
After installing corels, run pytest (you may have to install it with pip install pytest first) from the tests/ folder, where the tests are located.
Examples
Large dataset, loaded from this file
from corels import *
# Load the dataset
X, y, _, _ = load_from_csv("data/compas.csv")
# Create the model, with 10000 as the maximum number of iterations
c = CorelsClassifier(n_iter=10000)
# Fit, and score the model on the training set
a = c.fit(X, y).score(X, y)
# Print the model's accuracy on the training set
print(a)Toy dataset (See picture example above)
from corels import CorelsClassifier
# ["loud", "samples"] is the most verbose setting possible
C = CorelsClassifier(max_card=2, c=0.0, verbosity=["loud", "samples"])
# 4 samples, 3 features
X = [[1, 0, 1], [0, 0, 0], [1, 1, 0], [0, 1, 0]]
y = [1, 0, 0, 1]
# Feature names
features = ["Mac User", "Likes Pie", "Age < 20"]
# Fit the model
C.fit(X, y, features=features, prediction_name="Has a dirty computer")
# Print the resulting rulelist
print(C.rl())
# Predict on the training set
print(C.predict(X))More examples are in the examples/ directory
Questions?
Email the maintainer at: vassilioskaxiras@gmail.com