RagBase - Private Chat with Your Documents
Completely local RAG with chat UI
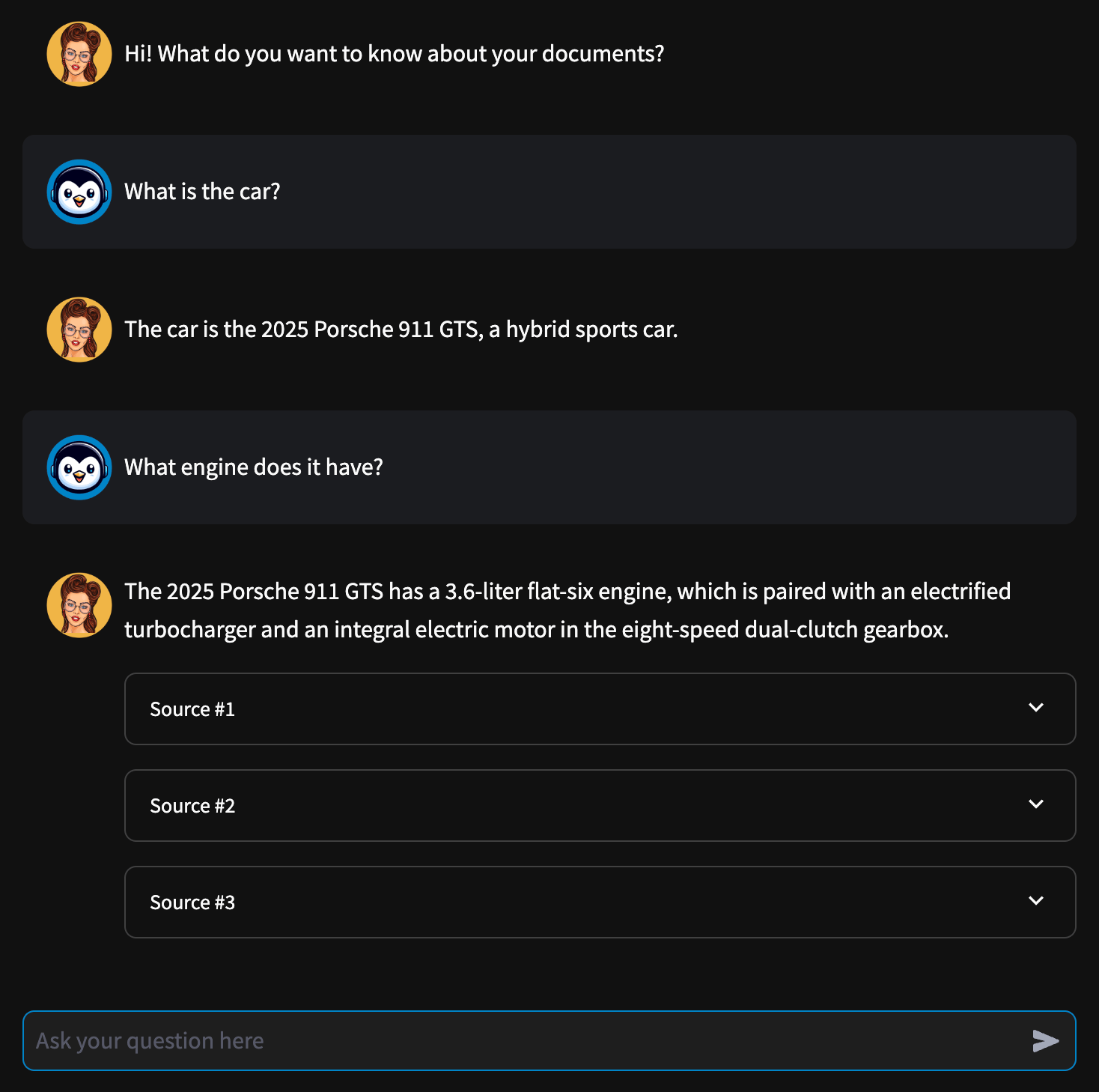
Demo
Check out the RagBase on Streamlit Cloud. Runs with Groq API.
Installation
Clone the repo:
git clone git@github.com:curiousily/ragbase.git
cd ragbaseInstall the dependencies (requires Poetry):
poetry installFetch your LLM (gemma2:9b by default):
ollama pull gemma2:9bRun the Ollama server
ollama serveStart RagBase:
poetry run streamlit run app.pyArchitecture
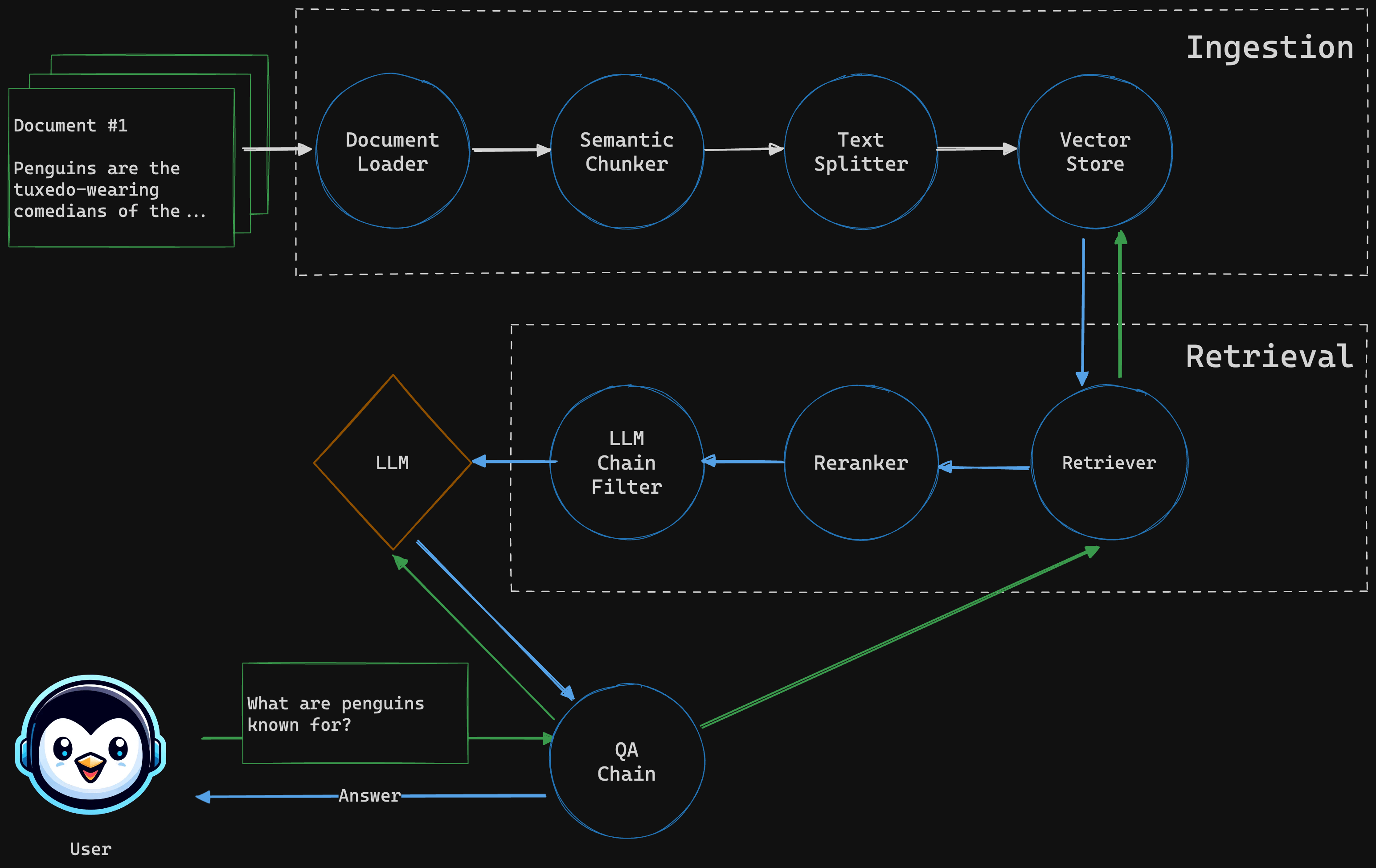
Ingestor
Extracts text from PDF documents and creates chunks (using semantic and character splitter) that are stored in a vector databse
Retriever
Given a query, searches for similar documents, reranks the result and applies LLM chain filter before returning the response.
QA Chain
Combines the LLM with the retriever to answer a given user question
Tech Stack
- Ollama - run local LLM
- Groq API - fast inference for mutliple LLMs
- LangChain - build LLM-powered apps
- Qdrant - vector search/database
- FlashRank - fast reranking
- FastEmbed - lightweight and fast embedding generation
- Streamlit - build UI for data apps
- PDFium - PDF processing and text extraction
Add Groq API Key (Optional)
You can also use the Groq API to replace the local LLM, for that you'll need a .env file with Groq API key:
GROQ_API_KEY=YOUR API KEY