PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting
Sunghwan Hong* · Jaewoo Jung* · Heeseong Shin · Jisang Han · Jiaolong Yang† · Chong Luo† · Seungryong Kim†
Paper | Project Page
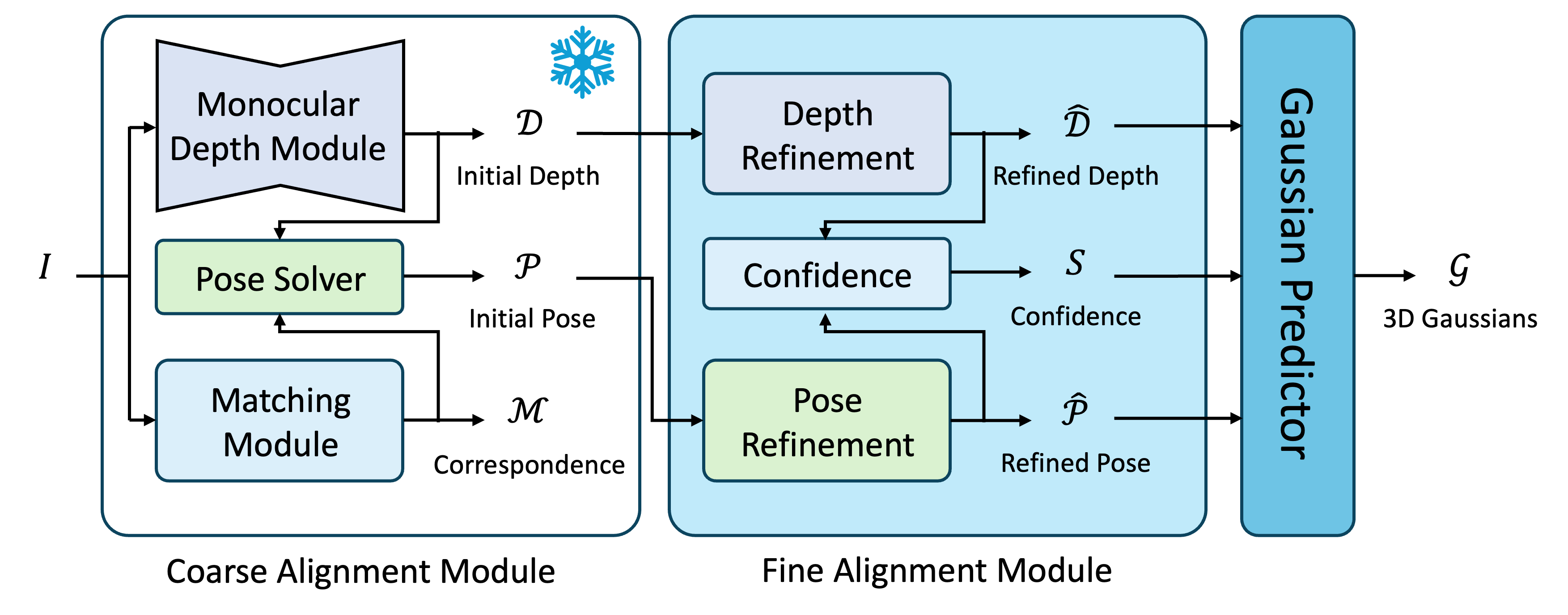
PF3plat enables estimates multi-view consistent depth, accurate camera pose, and photorealistic images from uncalibrated image collections.
What to expect:
- 🛠️ [x] Training and evaluation code & scripts
- 🌍 [] Demo code, taking only RGB images, for an easy use
- ⚡ [] Leveraging more recently released monocular metric depth estimation model, DepthPro or MoGe (Check out Jiaolong's new paper!).
- 🚀 [] Releasing more generalized model (trained on full set of DL3DV and RealEstate10K)
Installation
Our code is developed based on pytorch 2.0.1, CUDA 12.1 and python 3.10.
We recommend using conda for installation:
conda create -n pf3plat python=3.10
conda activate pf3plat
pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 --index-url https://download.pytorch.org/whl/cu118
pip install -r requirements.txtPreparing RealEstate10K, ACID and DL3DV Datasets
Training Dataset
-
For training on RealEstate10K and ACID, we primarily follow pixelSplat and MVSplat to train on 256x256 resolution.
-
Please refer to here for acquiring the processed 360p dataset (360x640 resolution).
-
For DL3DV, please download from here. We include both training and evaluation sets in there.
-
Note that we use the subset of DL3DV for training, so if you want to train and evaluate in your own way, you can prepare the dataset by following the instructions here.
-
By default, we assume all the datasets are placed in datasets directory.
Evaluation Dataset
-
For evaluation on RealEstate10K and ACID, we follow CoPoNeRF and use different evaluation splits. Please download from Re10k and ACID.
-
Note that the evaluation set, which contains 140 scenes for evaluation, is included along with the training set.
-
By default, we assume all the datasets are placed in datasets directory.
Training
We observed that enabling flash attention leads to frequent NaN values. In this codebase, we set flash=False. We thus set the current batch size as 3. We trained our model with A6000.
Note that for evaluation you need to specify the path to the datasets in config/experiment/{re10k,acid,dl3dv}.yaml or simply pass as argument in the command line.
python -m src.main +experiment={re10k, acid, dl3dv} data_loader.train.batch_size=3Evaluation
The pretrained weights can be found here. Note that for evaluation you need to specify the path to the datasets in config/experiment/{re10k,acid,dl3dv}.yaml or simply pass as argument in the command line.
python -m src.main +experiment={re10k, acid}_test checkpointing.load=$PATHTOCKPT$ dataset/view_sampler=evaluation mode=test test.compute_score=true
python -m src.main +experiment=dl3dv_test checkpointing.load=$PATHTPCKPT$ dataset/view_sampler=evaluation mode=test test.compute_scores=true dataset.view_sampler.index_path=assets/evaluation_index_dl3dv_{5, 10}view.jsonCamera Conventions
The camera intrinsic matrices are normalized (the first row is divided by image width, and the second row is divided by image height).
The camera extrinsic matrices are OpenCV-style camera-to-world matrices ( +X right, +Y down, +Z camera looks into the screen).
Citation
@article{hong2024pf3plat,
title = {PF3plat: Pose-Free Feed-Forward 3D Gaussian Splatting},
author = {Sunghwan Hong and Jaewoo Jung and Heeseong Shin and Jisang Han and Jiaolong Yang and Chong Luo and Seungryong Kim},
journal = {arXiv preprint arXiv:2410.22128},
year = {2024}
}Acknowledgements
We thank the following repos for their codes, which were used in our implementation: pixelSplat, MVSplat, UniDepth v2 and LightGlue. We thank the original authors for their excellent work. I also thank Haofei Xu for helping me making this repo.