 mrocklin
commented
5 years ago
mrocklin
commented
5 years ago Thanks for the writeup and the motivation @rabernat . In general I agree with everything that you've written.
I'll try to lay out the challenge from a scheduling perspective. The worker notices that it is running low on memory. The things that it can do are:
- Run one of the many tasks it has sitting around
- Stop running those tasks
- Write data to disk
- Kick tasks back to the scheduler for rescheduling
Probably it should run some task, but it doesn't know which tasks generate data, and which tasks allow it to eventually release data. In principle we know that operations like from_hdf5 are probably bad for memory and operations like sum are probably good, but we probably can't pin these names into the worker itself.
One option that I ran into recently is that we could slowly try to learn which tasks cause memory to arrive and which tasks cause memory to be released. This learning would happen on the worker. This isn't straightforward because there are many tasks running concurrently and their results on the system will be confused (there is no way to tie a system metric like CPU time or memory use to a particular Python function). Some simple model might give a decent idea over time though.
We do something similar (though simpler) with runtime. We maintain an exponentially weighted moving average of task run time, grouped by task prefix name (like from-hdf5), and use this for scheduling heuristics.
This approach would also be useful for other resource constraints, like network use (it'd be good to have a small number of network-heavy tasks like from-s3 running at once), and the use of accelerators like GPUs (the primary cause of my recent interest).
If someone wanted to try out the approach above my suggestion would be to ...
- Create a periodic callback on the worker that checked the memory usage of the process with some frequency
- Look at the tasks running (self.executing) and the memory growth since the last time and adjust some model for each of those tasks' prefixes (see
key_split) - That model might be very simple, like the number of times that memory has increased while seeing that function run. Greater than 0 means that memory increased more often than decreased and vice versa.
- Look at the policies in
Worker.memory_monitorand maybe make a new one- Maybe we go through
self.readyand reprioritize? - Maybe we set a flag so when we pop tasks from
self.readywe only accept those that we think reduce memory use? - ...
- Maybe we go through
There are likely other solutions to this whole problem. But this might be one.
 martindurant
martindurant rabernat
rabernat guillaumeeb
guillaumeeb sjperkins
sjperkins abergou
abergou TomAugspurger
TomAugspurger



 MikeAlopis
MikeAlopis
In my work with large climate datasets, I often concoct calculations that cause my dask workers to run out of memory, start dumping to disk, and eventually grind my computation to a halt. There are many ways to mitigate this by e.g. using more workers, more memory, better disk-spilling settings, simpler jobs, etc. and these have all been tried over the years with some degree of success. But in this issue, I would like to address what I believe is the root of my problems within the dask scheduler algorithms.
The core problem is that the tasks early in my graph generate data faster than it can be consumed downstream, causing data to pile up, eventually overwhelming my workers. Here is a self contained example:
(Perhaps this could be simplified further, but I have done my best to preserve the basic structure of my real problem.)
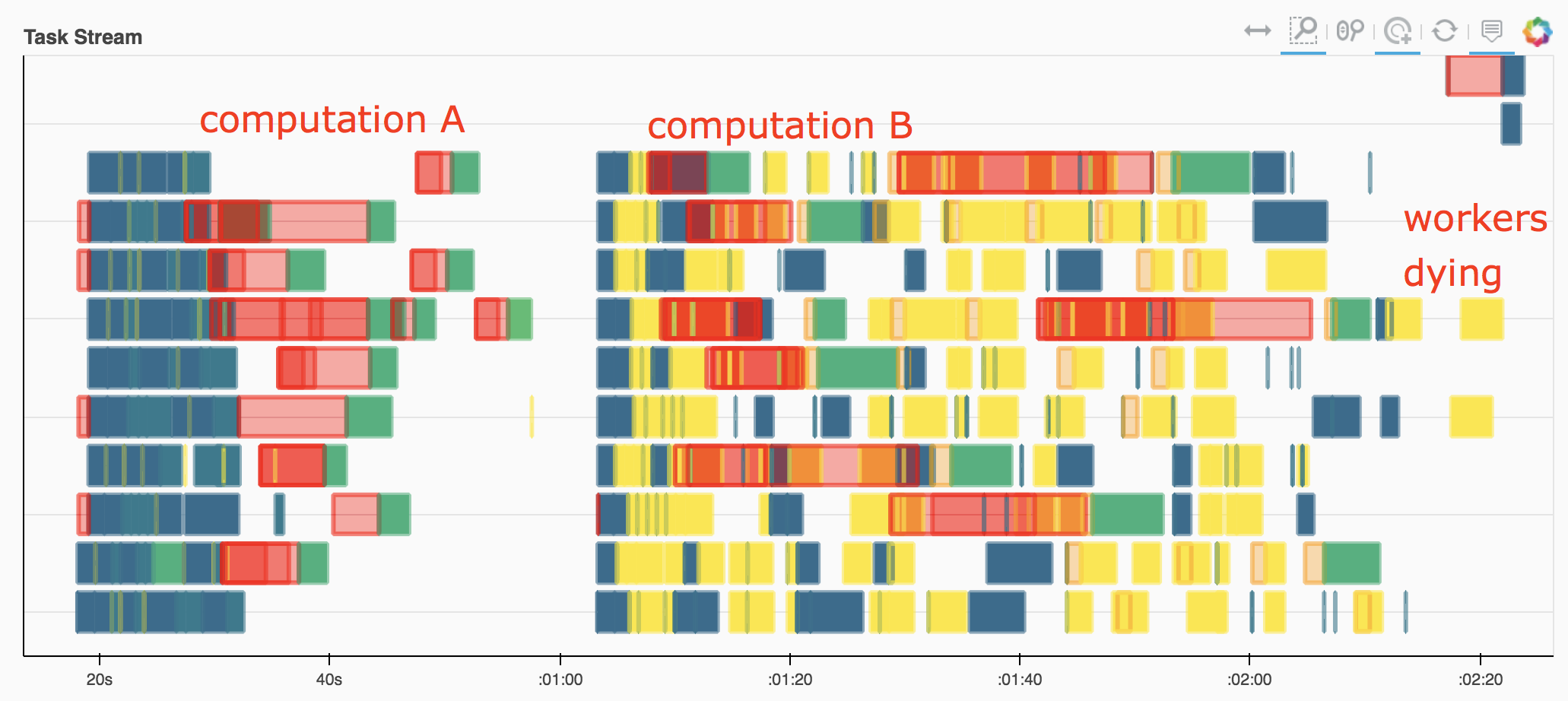
When I watch this execute on my dashboard, I see the workers just keep generating data until they reach their memory thresholds, at which point they start writing data to disk, before
my_custom_functionever gets called to relieve the memory buildup. Depending on the size of the problem and the speed of the disks where they are spilling, sometimes we can recover and manage to finish after a very long time. Usually the workers just stop working.This fail case is frustrating, because often I can achieve a reasonable result by just doing the naive thing:
and evaluating my computation in serial.
I wish the dask scheduler knew to stop generating new data before the downstream data could be consumed. I am not an expert, but I believe the term for this is backpressure. I see this term has come up in https://github.com/dask/distributed/issues/641, and also in this blog post by @mrocklin regarding streaming data.
I have a hunch that resolving this problem would resolve many of the pervasive but hard-to-diagnose problems we have in the xarray / pangeo sphere. But I also suspect it is not easy and requires major changes to core algorithms.
Dask version 1.1.4