 TomAugspurger
commented
5 years ago
TomAugspurger
commented
5 years ago Sorry, I was off last week. Getting back to it this week. But a short status update.
This branch does two things
- Gradually learns the likely net memory usage of completing a task, by observing the memory use of the output less the memory use of all freed dependencies.
- Adjust the Worker scheduling logic to prioritize memory-freeing tasks when we notice that we're under memory pressure.
Part 1 works well enough for now, I think (task annotations may help make things more exact in the future).
I'm struggling with part 2. I'm having trouble finding an acceptable scheduling policy that doesn't totally kill performance in some workloads.
@MikeAlopis if you have additional examples where you're unexpectedly running into worker memory errors, I'd be happy to see them. I think I'll want to test this out on a diverse set of workloads.
 mrocklin
mrocklin dougiesquire
dougiesquire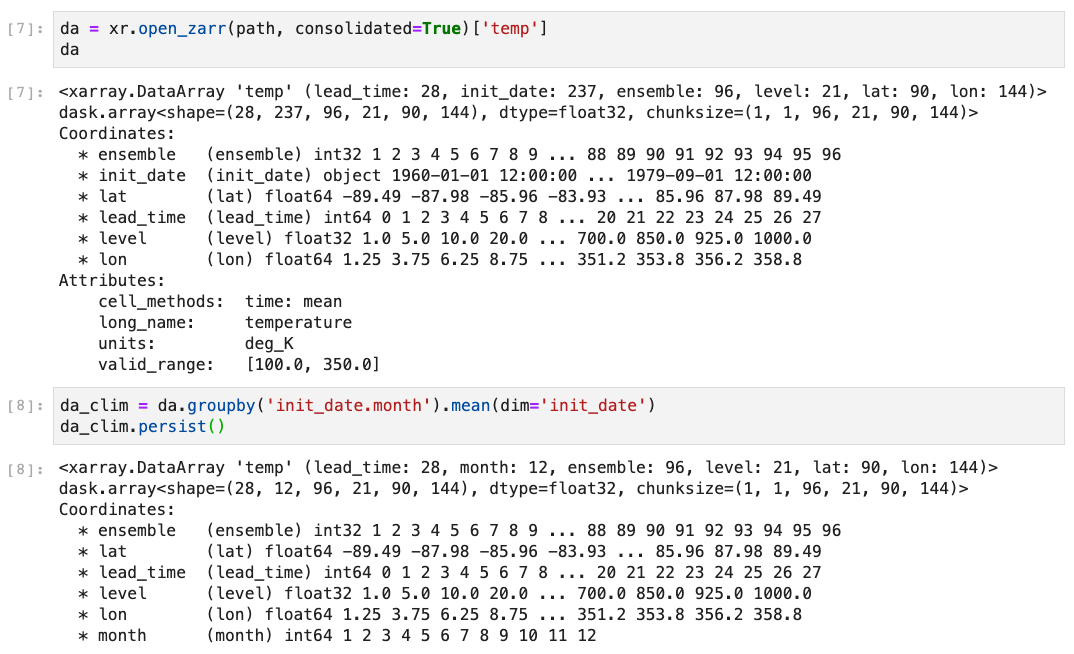
 rabernat
rabernat


 Thomas-Moore-Creative
Thomas-Moore-Creative eriknw
eriknw
 takluyver
takluyver itamarst
itamarst apatlpo
apatlpo gjoseph92
gjoseph92

 RichardScottOZ
RichardScottOZ sjperkins
sjperkins JSKenyon
JSKenyon dcherian
dcherian
In my work with large climate datasets, I often concoct calculations that cause my dask workers to run out of memory, start dumping to disk, and eventually grind my computation to a halt. There are many ways to mitigate this by e.g. using more workers, more memory, better disk-spilling settings, simpler jobs, etc. and these have all been tried over the years with some degree of success. But in this issue, I would like to address what I believe is the root of my problems within the dask scheduler algorithms.
The core problem is that the tasks early in my graph generate data faster than it can be consumed downstream, causing data to pile up, eventually overwhelming my workers. Here is a self contained example:
(Perhaps this could be simplified further, but I have done my best to preserve the basic structure of my real problem.)
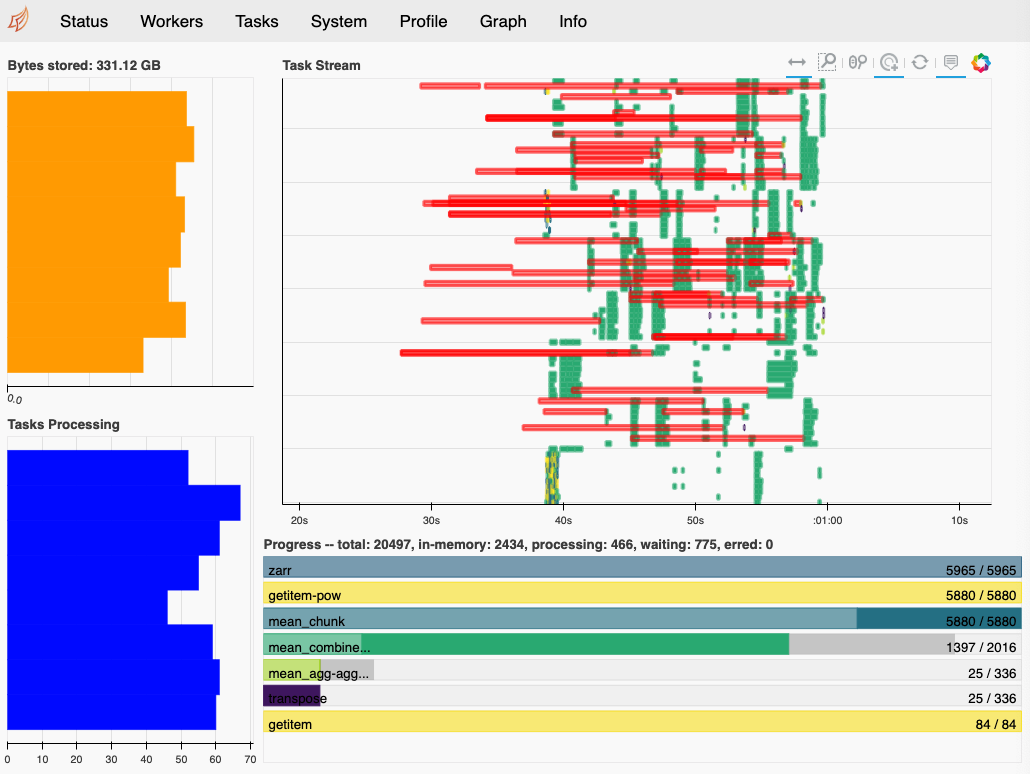
When I watch this execute on my dashboard, I see the workers just keep generating data until they reach their memory thresholds, at which point they start writing data to disk, before
my_custom_functionever gets called to relieve the memory buildup. Depending on the size of the problem and the speed of the disks where they are spilling, sometimes we can recover and manage to finish after a very long time. Usually the workers just stop working.This fail case is frustrating, because often I can achieve a reasonable result by just doing the naive thing:
and evaluating my computation in serial.
I wish the dask scheduler knew to stop generating new data before the downstream data could be consumed. I am not an expert, but I believe the term for this is backpressure. I see this term has come up in https://github.com/dask/distributed/issues/641, and also in this blog post by @mrocklin regarding streaming data.
I have a hunch that resolving this problem would resolve many of the pervasive but hard-to-diagnose problems we have in the xarray / pangeo sphere. But I also suspect it is not easy and requires major changes to core algorithms.
Dask version 1.1.4