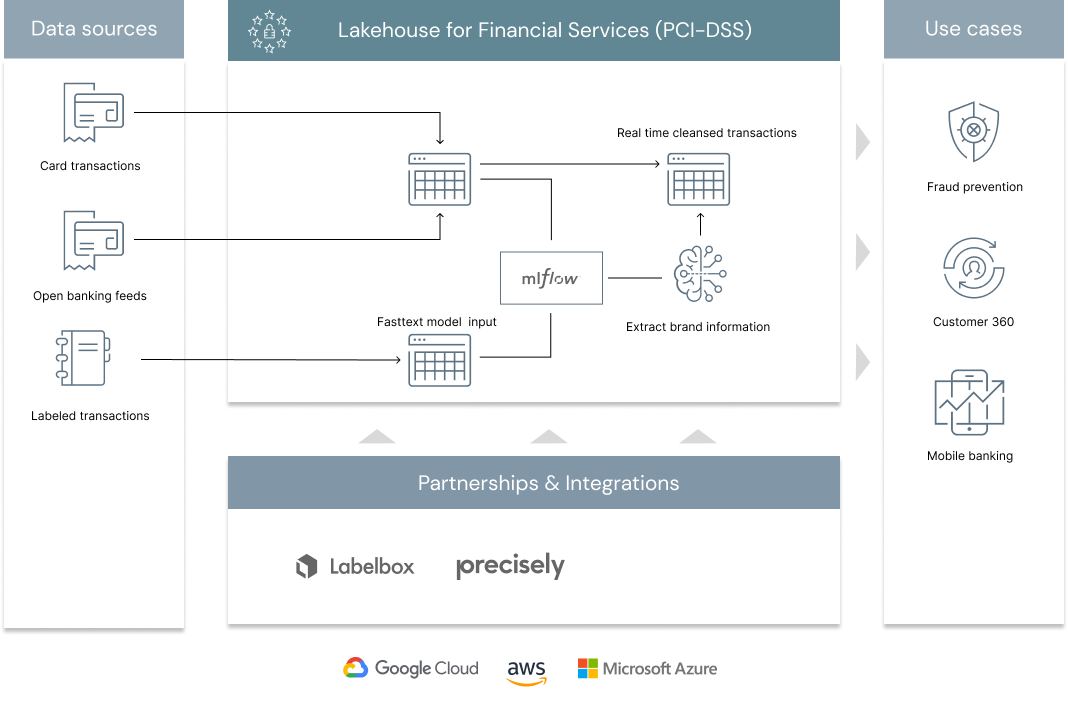
According to 2020 research from the Nilson Report, roughly 1 billion card transactions occur every day around the world (100 million transactions in the US alone). That is 1 billion data points that can be exploited every day by retail banks and payment processor companies to better understand customers spending behaviours, improve customer experience through their mobile banking applications, drive significant cross sell opportunities in the context of customer 360 or leverage these personalized insights to reduce fraud. With many entities involved in the authorization and settlement of a card transaction, the contextual information carried forward from a merchant to a retail bank is complicated, sometimes misleading and requires the use of advanced analytics techniques to extract clear brand and merchant information. In this solution accelerator, we demonstrate how the lakehouse architecture enables banks, open banking aggregators and payment processors to address the core challenge of retail banking: merchant classification.
© 2021 Databricks, Inc. All rights reserved. The source in this notebook is provided subject to the Databricks License. All included or referenced third party libraries are subject to the licenses set forth below.
| library | description | license | source |
|---|---|---|---|
| fasttext | NLP library | BSD License | https://fasttext.cc/ |
| PyYAML | Reading Yaml files | MIT | https://github.com/yaml/pyyaml |
Instruction
To run this accelerator, clone this repo into a Databricks workspace. Switch to the web-sync branch if you would like to run the version of notebooks currently published on the Databricks website. Attach the RUNME notebook to any cluster running a DBR 11.0 or later runtime, and execute the notebook via Run-All. A multi-step-job describing the accelerator pipeline will be created, and the link will be provided. Execute the multi-step-job to see how the pipeline runs. The job configuration is written in the RUNME notebook in json format. The cost associated with running the accelerator is the user's responsibility.