 davidpicard
commented
8 months ago
davidpicard
commented
8 months ago Indeed, if it would just be RM for approximating the Gaussian kernel, there are better approx (RFF for instance), so it's not exactly that.
The intuition is as follows: remove the keys, they're useless. What we want is, assuming cross attention (self attention being just a special case), that the query gathers information from the context (or values if you will). To that end, we first consider that the context is an empirical distribution ( a sampling of n tokens) and we sum it up by computing an approximation of its high order moments. This is done via a recursive RM-like approach. The sum over the tokens, is because we are computing approximate statistics of the empirical distribution, so the n has to go. In parallel, we map the query into that same space with a different projection, such that the resulting vector can perform a component selection. Notice that the query projection is followed by a sigmoid. thus multiplying the mapped query with the high-order moment will just result in zeroing some of the components of the high-order representation. It selects the relevant information from that representation. Since the selection is component-wise, the multi-head is naturally replaced: even if 2 tokens are mapped to disjointed components, they can still both be selected. The last projection maps this back into the original space.
In terms of cost, you get $nkdD$ for the query mapping, $mkdD + mkD$ for the context high-order representation (map + sum), and $nkDd$ for the last projection. It always avoids $nm$ and typically $k=2$ and $D=4d$, so you get roughly $8(2n+m)d^2$ compared to $3nd^2+ n^2d$ for regular attention. But anyway, models should be compared at equivalent flops, so complexity is not a good comparison until you get scores. I found that this arch has a higher number of params per flops than regular attention, so maybe it's better for scaling to very large models?
As for help, anything is welcomed! Adding new models for different tasks, based on this layer, and reporting results. Testing variations (notice that there is no normalization at any place. I found it was easier to train like this, but my training recipes are not yet good enough, so maybe they need to come back?) and documenting progress, etc. For example, I'm struggling to get a good imagenet score, so tweaking the training recipe might be something (although I'm already tweaking this a lot). Another idea is to train a small language model on next token prediction. The regular causal masking should work.
Hope that clarifies most of it!
 loicmagne
loicmagne
I saw your post on twitter about your new method for attention approximation and I think this is a cool idea! But can you clarify a few things? Approximation Method: Is your method genuinely approximating attention, or is it fundamentally different? From what I gather, if one intends to use the Random Maclaurin (RM) method while retaining the query (q), key (k), and value (v) components, it would seem similar to approaches like the Performer or the RANDOM FEATURE ATTENTION. These methods approximate the RBF kernel as: $\kappa (\mathbf{q}, \mathbf{k}) = \mathbb{E} [\mathbf{Z}(\mathbf{q}),\mathbf{Z}(\mathbf{k})^{T}]$ and $\mathbf{Z}: \mathbb{R}^d \rightarrow \mathbb{R}^D, \mathbf{Z}: \mathbf{x} \mapsto \frac{1}{\sqrt{D}}\left(Z_1(\mathbf{x}), \ldots, Z_D(\mathbf{x})\right)$, which characterizes the RM algorithm. In its final form, it looks like this:
If I understand correctly, methods like these work because they reorganize matrix multiplications, thereby removing the $n^2$ dependency. For the RM method, this results in four sums each with multiplication with dimensions (n Dd), (Dd n), and (n d), assuming 'D' represents what you call 'order_expand.' A high 'D' value is crucial for the RM algorithm is it the case also here?. Query, Key, Value Components: It appears you're not maintaining the traditional query, key, and value framework. How does this approach approximate attention without these components? I initially thought 'h' in your diagram played the role of the queries, but after examining the diagram (linked below), it doesn't seem to be the case. It is more like context. Also why average over the token lengths? Is this how tokens are mixed and communicate with each other?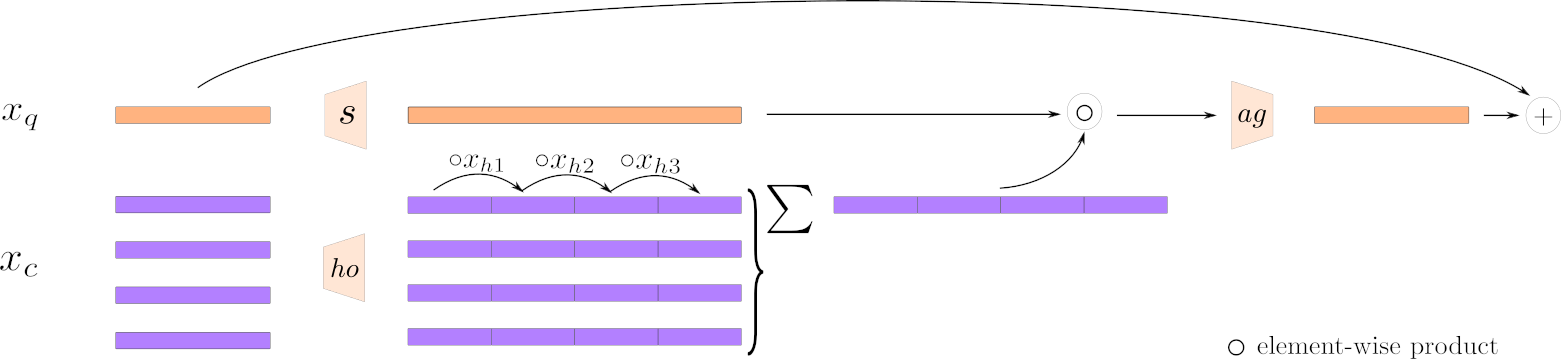 Can you explain more what your algorithm is trying to accomplish? It looks like it's replacing the self-attention mechanism, but does it require additional heads or capacity to become akin to MHA?
Can you explain more what your algorithm is trying to accomplish? It looks like it's replacing the self-attention mechanism, but does it require additional heads or capacity to become akin to MHA?