High order Moment Models
We propose an alternative to classical attention that scales linearly with the number of tokens and is based on high order moments.
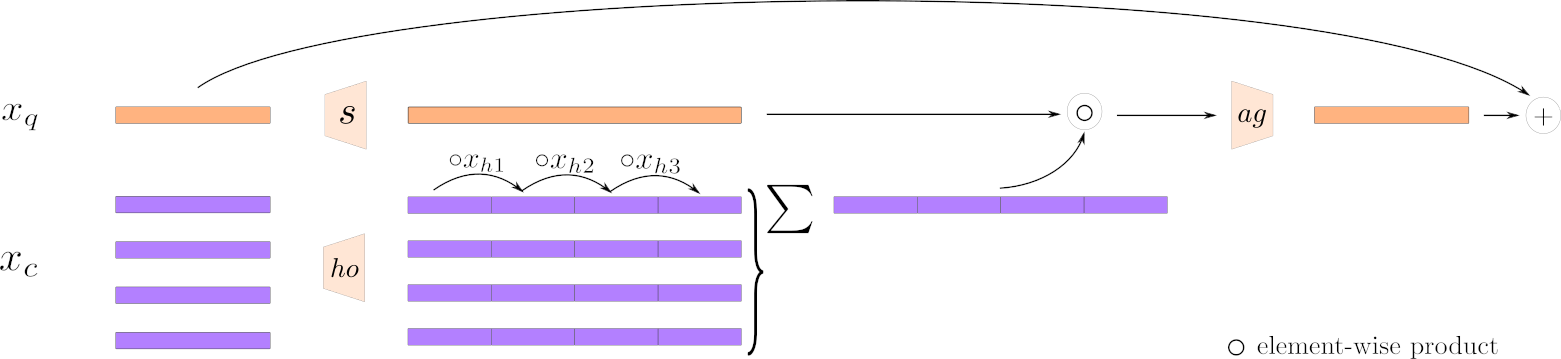
The HoMM scheme is as follows: Having a query token $x_q$ and a set of context tokens $x_c$, we first use a projection $ho$ to map each token $x_c$ to a high dimension space, where the high-order moments are computed recursively (by chunking and performing element-wise product, and then averaging over the tokens). $x_q$ is projected into the same high dimensional space with a projection $s$. The element-wise product of the two corresponds to $x_q$ selecting the information it needs in the high-order moments of $x_c$. The results is then projected back to the same space as $x_q$ and added to the original tokens via a residual connection.
/!\ Help welcome: DM me on twitter (https://twitter.com/david_picard), or submit an issue, or email me!
Changelog
- 20240122: diffusion branch is merged. Imagenet models are still training and improving.
- 20240120: metrics are fixed. Diffusion branch started. imagenet classification progress (53%->60%).
- 20240119: support for lightning and hydra added! Welcome to the multigpu world!
Fix me
Easy targets if you want to contribute
- Fix the MAE training with lightning+hydra
- Make an evaluation script for MAE: it loads the encoder from a MAE checkpoint and trains a classifier on top of it on imagenet. Add the fine-tune all model option
- fix the diffusion samplers, they don't really work.
- Search a good architecture for diffusion, maybe inspired from RIN
- Make a script that leverages a search tool (like https://docs.ray.io) to search for good hyper params (lr, wd, order, order_expand and ffw_expand mainly)
Currently testing on
- Vision: ImageNet classification (best 224x224 model score so far: 61.7% top-1 // 20230122)
- Vision: Masked Auto Encoder pretraining
- Probabilistic Time Series Forecasting: Running comparisons against AutoML Forecasting evaluations
Launching a classification training run
This repo supports hydra for handling configs. Look at src/configs to edit them. Here is an example of a training run:
python src/train.py data.dataset_builder.data_dir=path_to_imagenet seed=3407 model.network.dim=128 data.size=224 model.network.kernel_size=32 model.network.nb_layers=12 model.network.order=2 model.network.order_expand=4 model.network.ffw_expand=4 model.network.dropout=0.0 model.optimizer.optim.weight_decay=0.01 model.optimizer.optim.lr=1e-3 data.full_batch_size=1024 trainer.max_steps=300000 model.lr_scheduler.warmup_steps=10000 computer.num_workers=8 computer.precision=bf16-mixed data/additional_train_transforms=randaugment data.additional_train_transforms.randaugment_p=0.1 data.additional_train_transforms.randaugment_magnitude=6 model.train_batch_preprocess.apply_transform_prob=1.0 checkpoint_dir="./checkpoints/"Launching MAE training run
python src/train.py --config-name train_mae data.dataset_builder.data_dir=path_to_dataset seed=3407 model.network.dim=128 data.size=256 model.network.kernel_size=16 model.network.nb_layers=8 model.network.order=4 model.network.order_expand=8 model.network.ffw_expand=4 model.network.dropout=0.0 model.optimizer.optim.weight_decay=0.01 model.optimizer.optim.lr=1e-3 data.full_batch_size=256 trainer.max_steps=300000 model.lr_scheduler.warmup_steps=10000 computer.num_workers=8 computer.precision=bf16-mixed data/additional_train_transforms=randaugment data.additional_train_transforms.randaugment_p=0.1 data.additional_train_transforms.randaugment_magnitude=6 model.train_batch_preprocess.apply_transform_prob=1.0 checkpoint_dir="./checkpoints/"GAT-HoMM: a Graph Neural Network with HoMM Attention
- Results: accuracy on the 1000 test nodes of the Cora dataset (https://arxiv.org/pdf/1710.10903.pdf) of 0.805
- To reproduce, execute:
-
python src/train_gnn.py
-
- To run hyperparameter optimization, execute:
-
python src/optimize_hps_gnn.py
-
- Illustrative notebook:
src/gnn_homm_nb.ipynb - Default configuration file for train_gnn.py:
src/configs/train_gnn.yml - Default configuration file for optimize_hps_gnn.py:
src/configs/hp_opt_gnn.yml
TODO:
- Vision: diffusion model
- NLP: sentence embedding
- NLP: next token prediction
- Graphs?
Ablation
On imagenet, with the following parameters:
- image size: 160
- patch size: 16
- # of layers: 8
- batch size: 512
- weight decay: 0.01
- # of training steps: 150k
- optimizer: AdamW
- rand-augment + cutmix/mixup
| dim | o | oe | acc | Flops | # params |
|---|---|---|---|---|---|
| 320 | 1 | 8 | 43.6 | 2.6G | 26M |
| 320 | 2 | 4 | 47.6 | 2.6G | 26M |
| 320 | 4 | 2 | 46.1 | 2.6G | 26M |
| 256 | 2 | 8 | 47.9 | 2.9G | 29M |
| 256 | 4 | 4 | 46.1 | 2.9G | 29M |
Clearly, having the second order makes a big difference. Having the fourth order not so much. It's better to have a higher dimension and lower expansion than the contrary.