
Model Download | Evaluation Results | Model Architecture | API Platform | License | Citation
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
1. Introduction
Today, we’re introducing DeepSeek-V2, a strong Mixture-of-Experts (MoE) language model characterized by economical training and efficient inference. It comprises 236B total parameters, of which 21B are activated for each token. Compared with DeepSeek 67B, DeepSeek-V2 achieves stronger performance, and meanwhile saves 42.5% of training costs, reduces the KV cache by 93.3%, and boosts the maximum generation throughput to 5.76 times.


We pretrained DeepSeek-V2 on a diverse and high-quality corpus comprising 8.1 trillion tokens. This comprehensive pretraining was followed by a process of Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) to fully unleash the model's capabilities. The evaluation results validate the effectiveness of our approach as DeepSeek-V2 achieves remarkable performance on both standard benchmarks and open-ended generation evaluation.
2. News
- 2024.05.16: We released the DeepSeek-V2-Lite.
- 2024.05.06: We released the DeepSeek-V2.
3. Model Downloads
Due to the constraints of HuggingFace, the open-source code currently experiences slower performance than our internal codebase when running on GPUs with Huggingface. To facilitate the efficient execution of our model, we offer a dedicated vllm solution that optimizes performance for running our model effectively.
4. Evaluation Results
Base Model
Standard Benchmark (Models larger than 67B)
Standard Benchmark (Models smaller than 16B)
For more evaluation details, such as few-shot settings and prompts, please check our paper.
Context Window
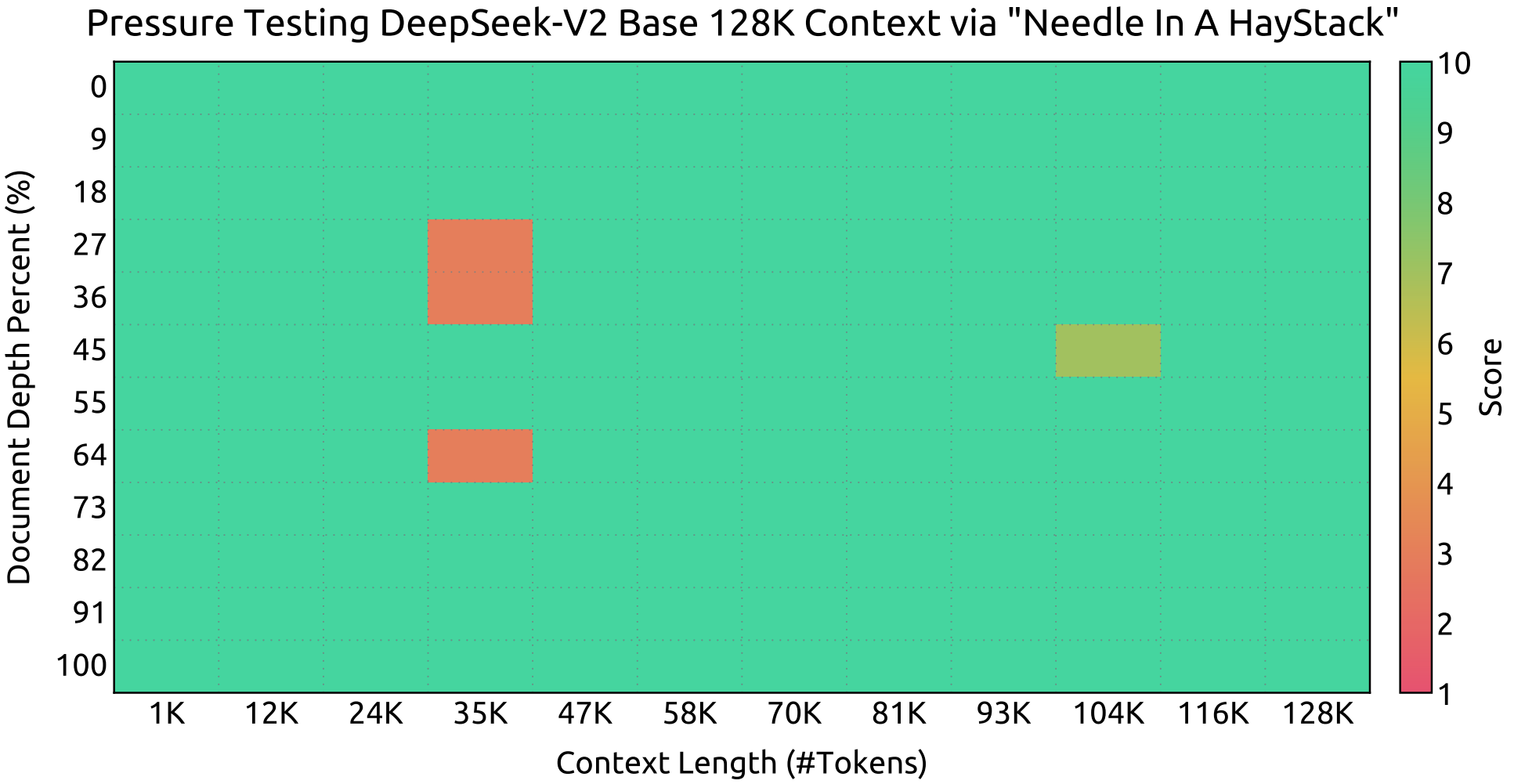
Evaluation results on the Needle In A Haystack (NIAH) tests. DeepSeek-V2 performs well across all context window lengths up to 128K.
Chat Model
Standard Benchmark (Models larger than 67B)
Standard Benchmark (Models smaller than 16B)
English Open Ended Generation Evaluation
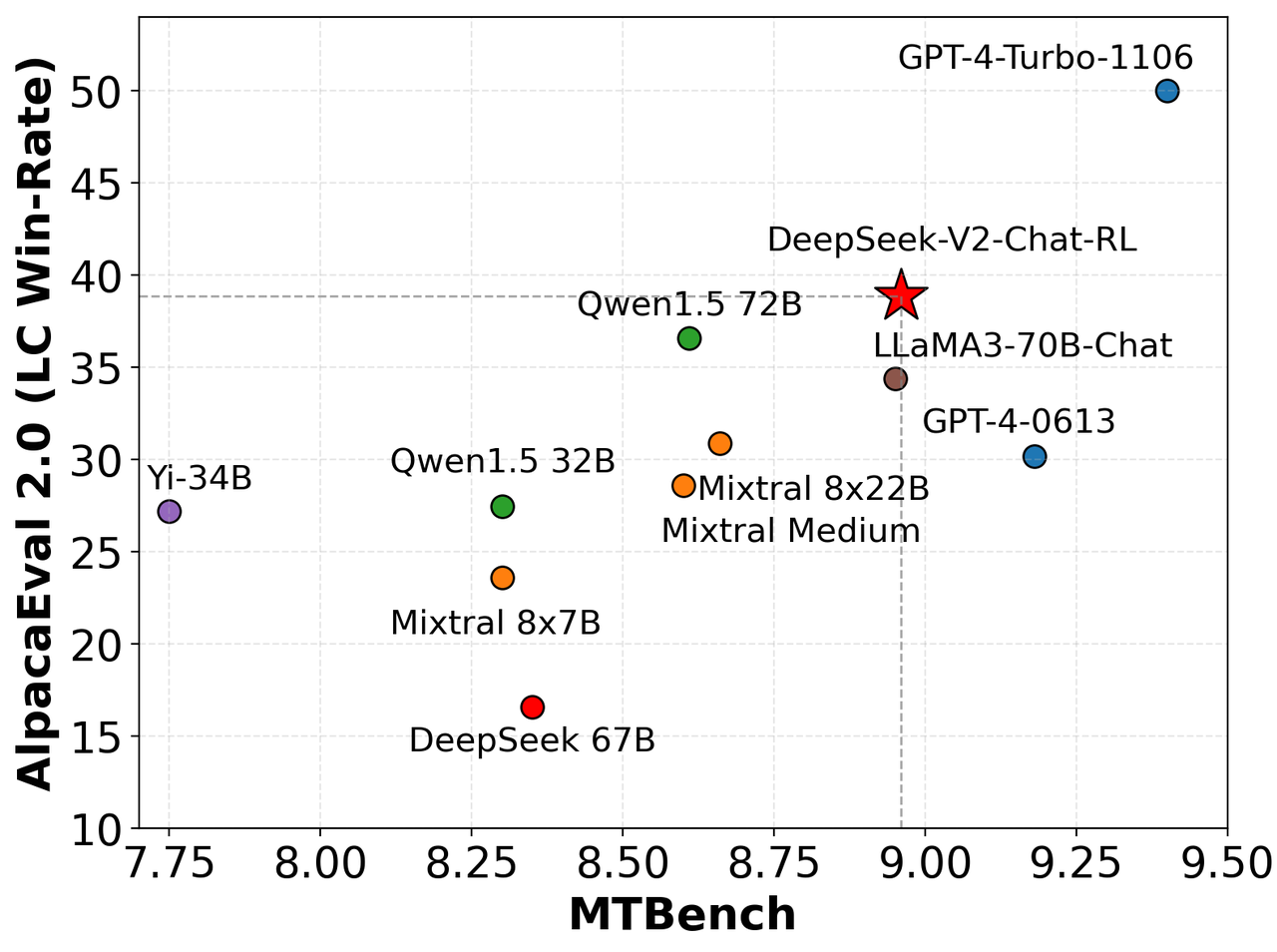
We evaluate our model on AlpacaEval 2.0 and MTBench, showing the competitive performance of DeepSeek-V2-Chat-RL on English conversation generation.
Chinese Open Ended Generation Evaluation
Alignbench (https://arxiv.org/abs/2311.18743)
Coding Benchmarks
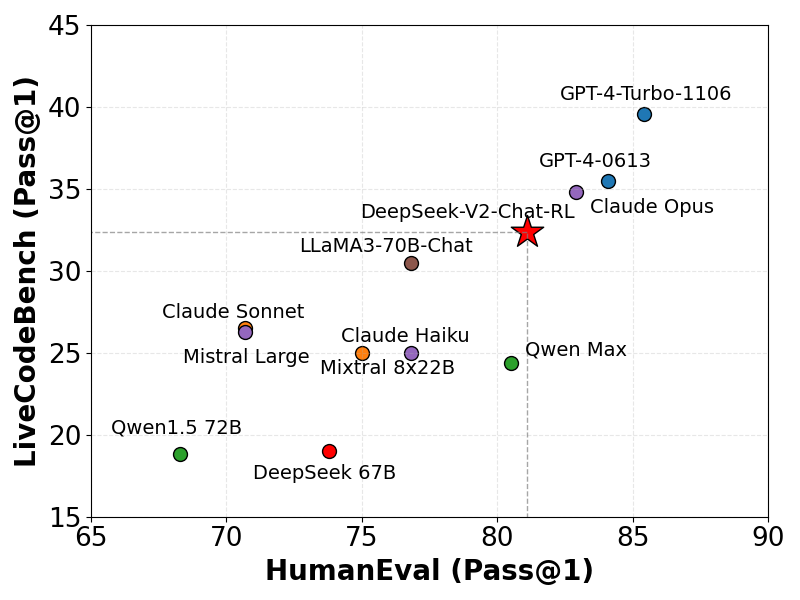
We evaluate our model on LiveCodeBench (0901-0401), a benchmark designed for live coding challenges. As illustrated, DeepSeek-V2 demonstrates considerable proficiency in LiveCodeBench, achieving a Pass@1 score that surpasses several other sophisticated models. This performance highlights the model's effectiveness in tackling live coding tasks.
5. Model Architecture
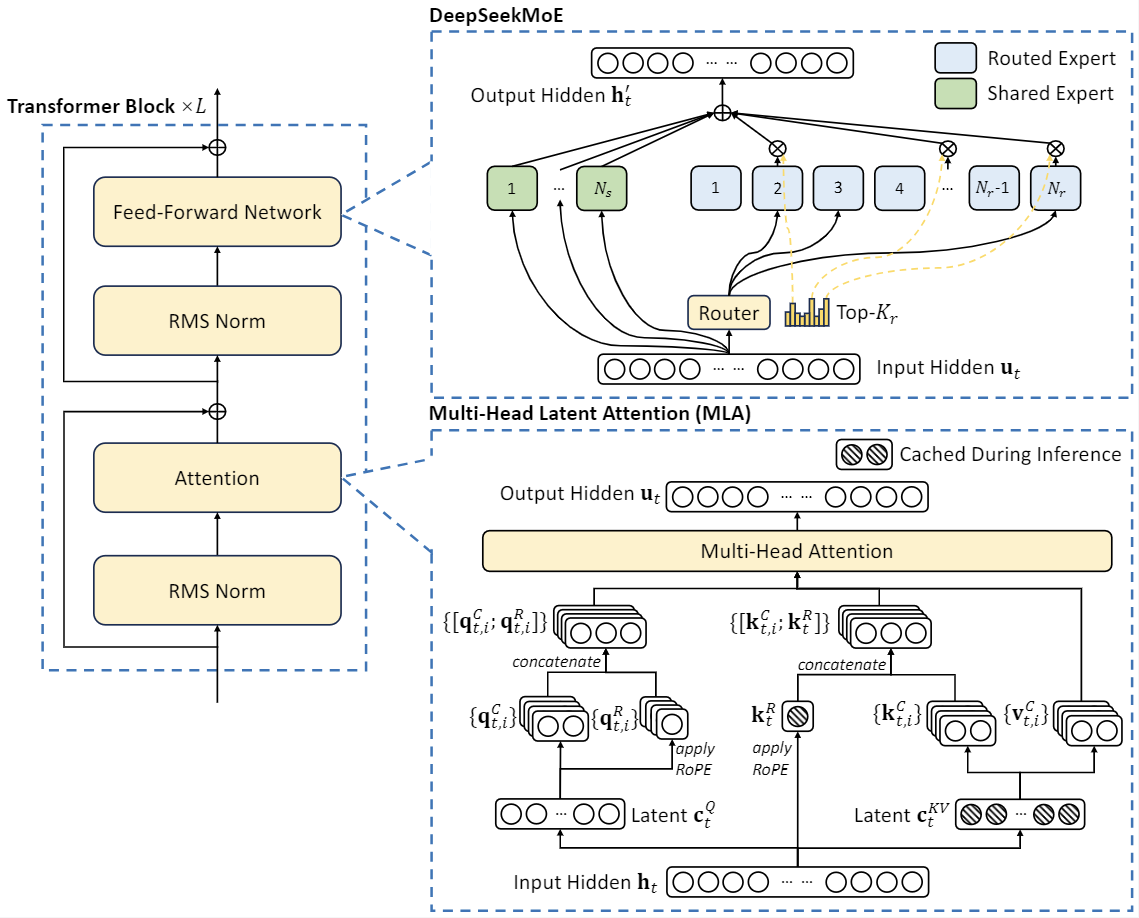
DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference:
- For attention, we design MLA (Multi-head Latent Attention), which utilizes low-rank key-value union compression to eliminate the bottleneck of inference-time key-value cache, thus supporting efficient inference.
- For Feed-Forward Networks (FFNs), we adopt DeepSeekMoE architecture, a high-performance MoE architecture that enables training stronger models at lower costs.
6. Chat Website
You can chat with the DeepSeek-V2 on DeepSeek's official website: chat.deepseek.com
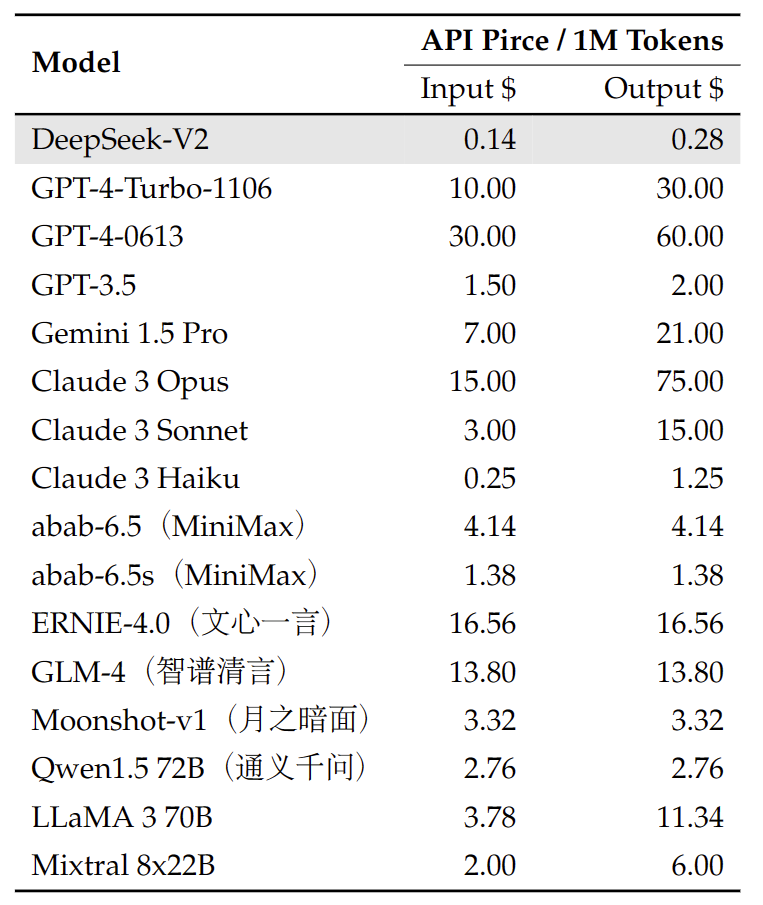
7. API Platform
We also provide OpenAI-Compatible API at DeepSeek Platform: platform.deepseek.com. Sign up for over millions of free tokens. And you can also pay-as-you-go at an unbeatable price.
8. How to run locally
*To utilize DeepSeek-V2 in BF16 format for inference, 80GB8 GPUs are required.**
Inference with Huggingface's Transformers
You can directly employ Huggingface's Transformers for model inference.
Text Completion
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# `max_memory` should be set based on your devices
max_memory = {i: "75GB" for i in range(8)}
# `device_map` cannot be set to `auto`
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)Chat Completion
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/DeepSeek-V2-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# `max_memory` should be set based on your devices
max_memory = {i: "75GB" for i in range(8)}
# `device_map` cannot be set to `auto`
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True, device_map="sequential", torch_dtype=torch.bfloat16, max_memory=max_memory, attn_implementation="eager")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Write a piece of quicksort code in C++"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)The complete chat template can be found within tokenizer_config.json located in the huggingface model repository.
An example of chat template is as belows:
<|begin▁of▁sentence|>User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:You can also add an optional system message:
<|begin▁of▁sentence|>{system_message}
User: {user_message_1}
Assistant: {assistant_message_1}<|end▁of▁sentence|>User: {user_message_2}
Assistant:Inference with vLLM (recommended)
To utilize vLLM for model inference, please merge this Pull Request into your vLLM codebase: https://github.com/vllm-project/vllm/pull/4650.
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
max_model_len, tp_size = 8192, 8
model_name = "deepseek-ai/DeepSeek-V2-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, tensor_parallel_size=tp_size, max_model_len=max_model_len, trust_remote_code=True, enforce_eager=True)
sampling_params = SamplingParams(temperature=0.3, max_tokens=256, stop_token_ids=[tokenizer.eos_token_id])
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "Translate the following content into Chinese directly: DeepSeek-V2 adopts innovative architectures to guarantee economical training and efficient inference."}],
[{"role": "user", "content": "Write a piece of quicksort code in C++."}],
]
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)LangChain Support
Since our API is compatible with OpenAI, you can easily use it in langchain. Here is an example:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model='deepseek-chat',
openai_api_key=<your-deepseek-api-key>,
openai_api_base='https://api.deepseek.com/v1',
temperature=0.85,
max_tokens=8000)9. License
This code repository is licensed under the MIT License. The use of DeepSeek-V2 Base/Chat models is subject to the Model License. DeepSeek-V2 series (including Base and Chat) supports commercial use.
10. Citation
@misc{deepseekv2,
title={DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model},
author={DeepSeek-AI},
year={2024},
eprint={2405.04434},
archivePrefix={arXiv},
primaryClass={cs.CL}
}11. Contact
If you have any questions, please raise an issue or contact us at service@deepseek.com.