Parquet Extension for Mule 4.x
Mule SDK connector that provides the ability to read Parquet files into JSON or write Parquet files from Avro data.
Overview
Apache Parquet is a columnar data storage format, which provides a way to store tabular data column wise. Columns of same date-time are stored together as rows in Parquet format, so as to offer better storage, compression and data retrieval.
Using Parquet format has two advantages
- Reduced storage
- Query performance
Installation Instructions
- Clone the repo
- Deploy the connector to your local Maven repo
mvn clean install - Add the connector dependency to your project
pom.xmlfile
<dependency>
<groupId>com.dejim</groupId>
<artifactId>parquet</artifactId>
<version>1.0.24-SNAPSHOT</version>
<classifier>mule-plugin</classifier>
</dependency>Reporting Issues
You can report new issues at this link https://github.com/djuang1/parquet/issues.
Operations
Read Parquet - Stream
This operation allows you to read a parquet file from an InputStream (e.g. #[payload]) Data can be coming from S3 or other connector that provides Streaming instead of needing to read it from the file system. It returns the data back in JSON format.
Write Avro to Parquet - Stream
This operation allows you to write a parquet file to an InputStream (e.g. #[payload]). Instead of writing to disk, you can output the data directly to S3 or other connector that provides Streaming capabilities.
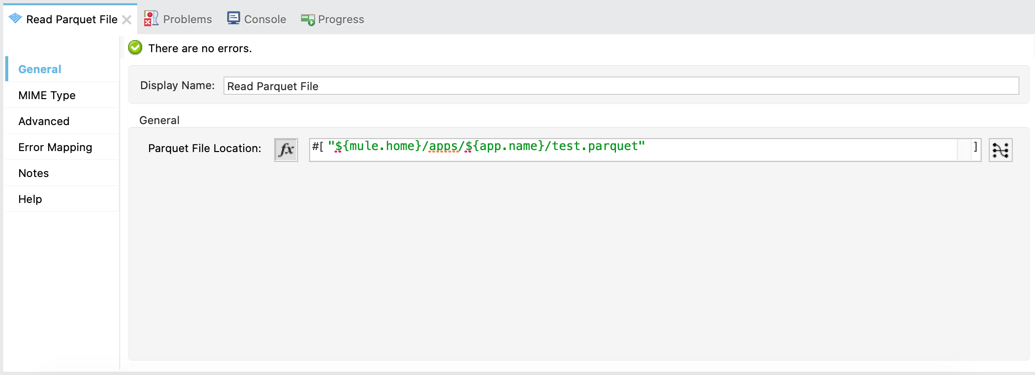
Read Parquet - File
This operation allows you to read a parquet file from a local file system. It returns the data back in JSON format.
- Parquet File Location - This is the location on the local file system where the operation will grab the parquet file.
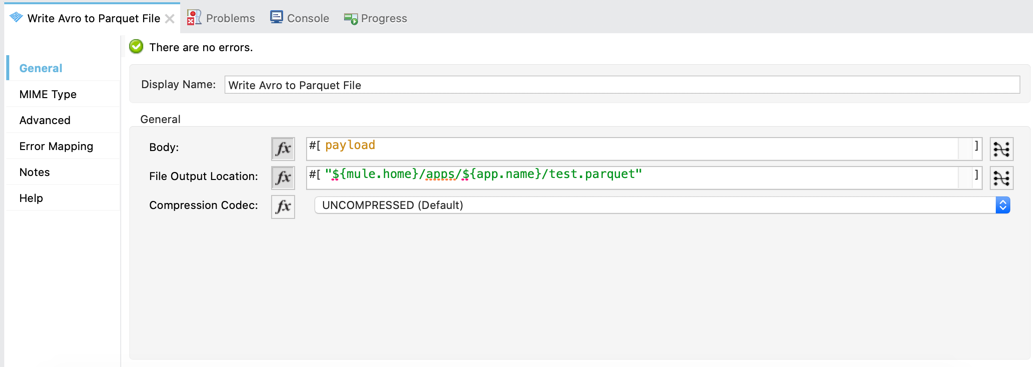
Write Avro to Parquet - File
Writing data to a parquet file isn't a straightforward process. It requires a schema that needs to be defined around the data. This operation allows you leverage Avro format support in MuleSoft to format the data using DataWeave before writing it to a parquet file.
- Body - This is the output from DataWeave component with data set with the MIME type of
application/avro - File Output Location - This is the location to write the parquet file on the local file system.
- Compression Codec - You can select the compression technique when configuring the operation. The GZip compression rate is higher than Snappy, and creates smaller files. However, Snappy generally provides better performance.
Author: Dejim Juang - dejimj@gmail.com
Last Update: October 22, 2022