KEWE Crawler
Crawler service in order to crawl keyword from Google search, user can also preview their crawling information with built-in dashboard
Table of Contents
-
Features
-
Use puppeteer to act like a browser, each keyword will be requested to
https://www.google.com/search?q={keyword}. -
After request successfully, use DOM API to get all needed information from search result: Ads links, first page links, result statistic.
-
To prevent Google marks this service as a bot, I'm using message queue to crawl all keyword sequentially, delay 2s between each keyword.
-
The below diagram will be descript the overall crawler workflow:
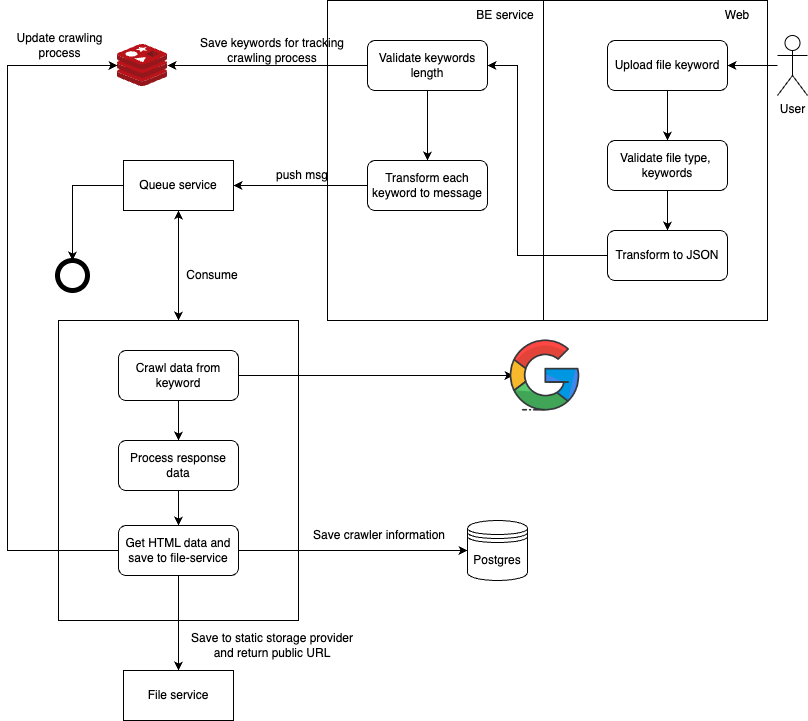
-
How to test
UAT Environment
- Please visit: https://kewecrawling.info/home. Using admin account (admin@gmail.com/abc123) for testing or create your own account.
Local Environment
With native
Prerequisite
Node v18.17.0 RabbitMQ 3.11.8-management Redis 6.2.0 Postgres 16.1Step to install project
Step 1: Clone project from github. Step 2: Init postgres database and seeding by using `init.sql` at root directory. Step 2: Navigate to the root of project. Step 3: Install dependencies and env for backend service: `api-service`, `file-service`, `crawler-service`. Step 3.1: Navigate to backend service folder. Step 3.2: run `npm install`. Step 3.3: run `cp .sample.env .env`. Step 3.3: update .env variables based on your `rabbitmq`, `redis`, `postgres` config. Step 3.4: run `npm run dev`. Step 4: Install dependencies and env for frontend service. Step 4.1: Navigate to `crawler-interface` folder Step 4.2: run `npm install`. Step 4.3: run `cp .sample.env .env`. Step 4.3: update .env variable base on your `api-service` config. Step 4.4: run `npm run start`. Step 5: Access to localhost:3000 and use sample file (keywords.csv at root director) and admin account (admin@gmail.com/abc123)for testing.With Docker
Prerequisite
Docker version 20.10.17 Docker-compose version 1.29.2Step to install project
Step 1: Clone project from github. Step 2: Navigate to the root of project. Step 3: Insert this command to your terminal: `docker-compose up -d`. Step 4: Access to localhost:3000 and use sample file (keywords.csv at root director) and admin account (admin@gmail.com/abc123)for testing.