Latent Scope

Quickly embed, project, cluster and explore a dataset. This project is a new kind of workflow + tool for visualizing and exploring datasets through the lens of latent spaces.
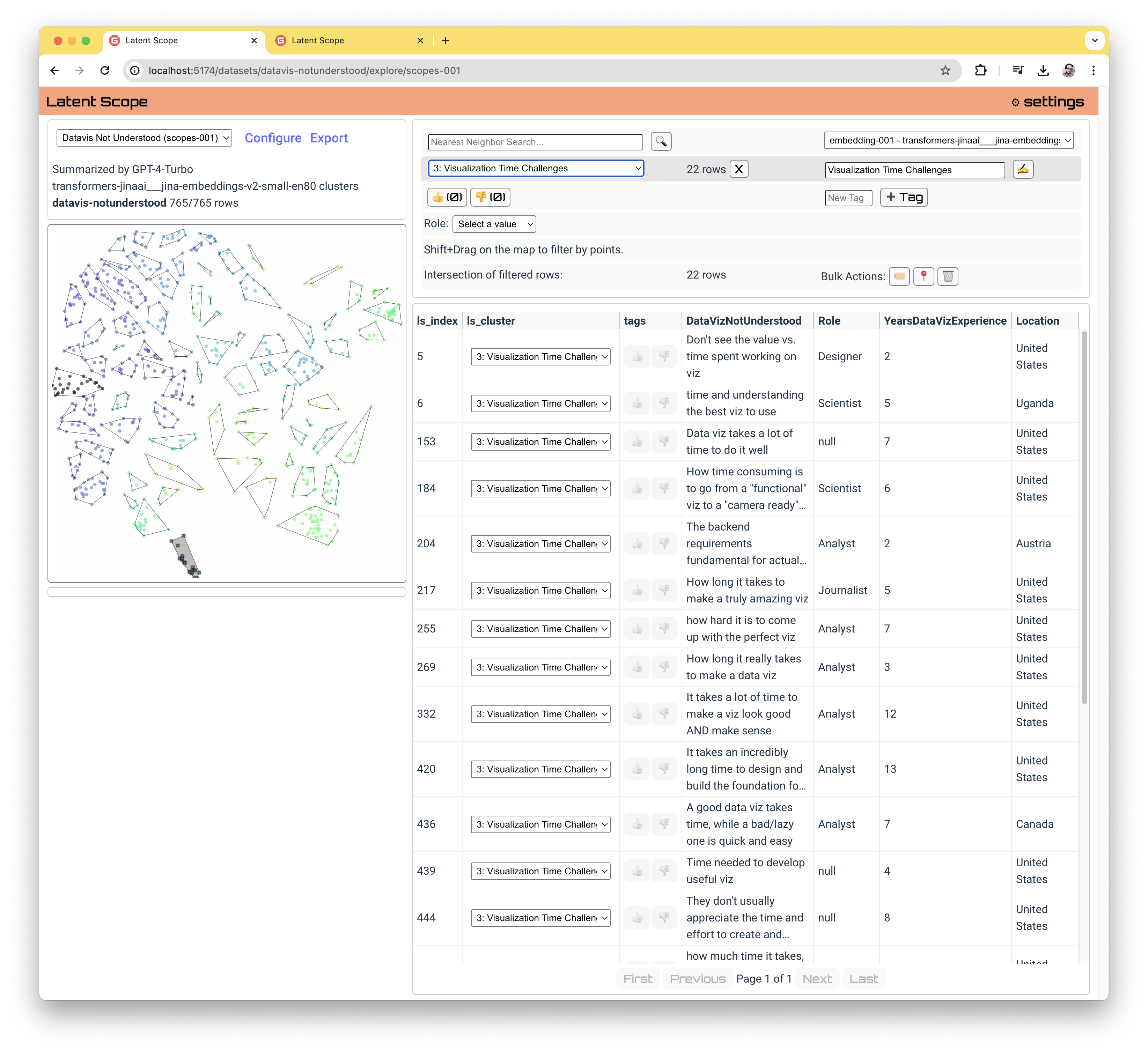
The power of machine learning models to encode unstructured data into high-dimensional embeddings is relatively under-explored. Retrieval Augmented Generation has taken off as a popular usecase for embeddings, but do you feel confident in your understanding of why certain data is being retrieved? Do you have a clear picture of what all is in your dataset? Latentscope is like a microscope that allows you to get a new perspective on what's happening to your data when it's embedded. You can try similarity search with different embeddings, peruse automatically labeled clusters and zoom in on individual data points all while keeping the context of your entire dataset.

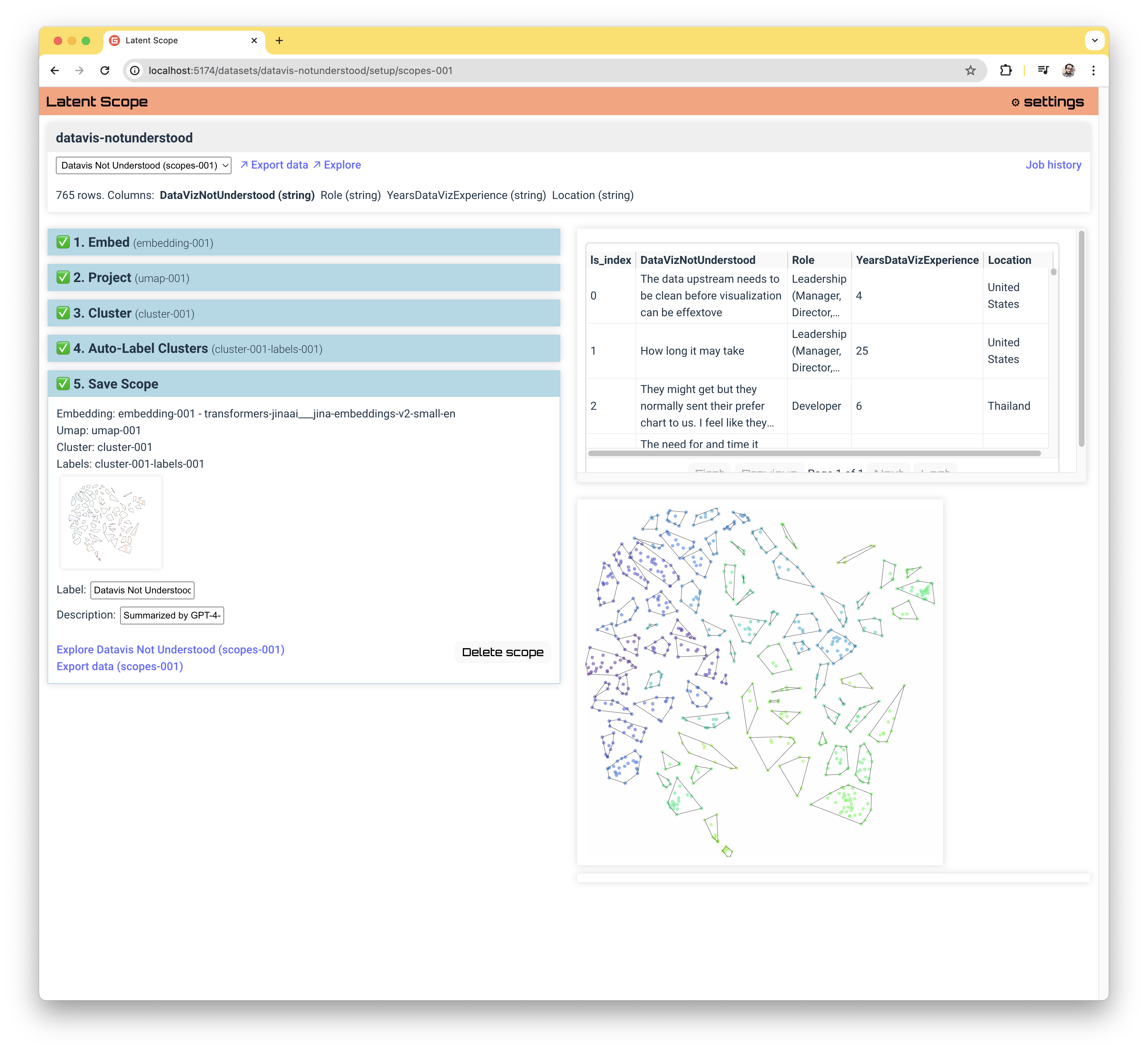
Latent Scope is a tool that encodes a process, taking your input data and running it through the steps of Embedding, Projecting, Clustering and Labeling resulting in a nicely structured annotation useful as input to further analysis. You can also explore the annotated data within the web UI to get a better understanding of your dataset and curate it to get a better quality dataset.
Getting started
Follow the documentation guides to get started:
Example Analysis
What can you do with Latent Scope? The following examples demonstrate the kinds of perspective and insights you can gain from your unstructured text data.
- Explore free-responses from surveys in this datavis survey analysis
- Cluster thousands of GitHub issues and PRs
- Explore 50,000 US Federal laws spanning two hundred years.
Quick Start
Latent Scope works on Mac, Linux and Windows. Python 3.12 is the recommended python version.
To get started, install the latent-scope python module and run the server via the Command Line:
python -m venv venv
source venv/bin/activate
pip install latentscope
ls-init ~/latent-scope-data --openai_key=XXX --mistral_key=YYY # optional api keys to enable API models
ls-serve Then open your browser to http://localhost:5001 and start processing your first dataset!
See the Your First Scope guide for a detailed walk-through of the process.
Python interface
You can also ingest data from a Pandas dataframe using the Python interface:
import latentscope as ls
df = pd.read_parquet("...")
ls.init("~/latent-scope-data") # you can also pass in openai_key="XXX", mistral_key="XXX" etc.)
ls.ingest("dadabase", df, text_column="joke")
ls.serve()See these notebooks for detailed examples of using the Python interface to prepare and load data.
- dvs-survey - A small test dataset of 700 rows to quickly illustrate the process. This notebook shows how you can do every step of the process with the Python interface.
- dadabase - A more interesting (and funny) dataset of 50k rows. This notebook shows how you can preprocess a dataset, ingest it into latentscope and then use the web interface to complete the process.
- dolly15k - Grab data from HuggingFace datasets and ingest into the process.
- emotion - 400k rows of emotional tweets.
Command line quick start
When latent-scope is installed, it creates a suite of command line scripts that can be used to setup the scopes for exploring in the web application. The output of each step in the process is flat files stored in the data directory specified at init. These files are in standard formats that were designed to be ported into other pipelines or interfaces.
# like above, we make sure to install latent-scope
python -m venv venv
source venv/bin/activate
pip install latent-scope
# prepare some data
wget "https://storage.googleapis.com/fun-data/latent-scope/examples/dvs-survey/datavis-misunderstood.csv" > ~/Downloads/datavis-misunderstood.csv
ls-init "~/latent-scope-data"
# ls-ingest dataset_id csv_path
ls-ingest-csv "datavis-misunderstood" "~/Downloads/datavis-misunderstood.csv"
# get a list of model ids available (lists both embedding and chat models available)
ls-list-models
# ls-embed dataset_id text_column model_id prefix
ls-embed datavis-misunderstood "answer" transformers-intfloat___e5-small-v2 ""
# ls-umap dataset_id embedding_id n_neighbors min_dist
ls-umap datavis-misunderstood embedding-001 25 .1
# ls-cluster dataset_id umap_id samples min_samples
ls-cluster datavis-misunderstood umap-001 5 5
# ls-label dataset_id text_column cluster_id model_id context
ls-label datavis-misunderstood "answer" cluster-001 transformers-HuggingFaceH4___zephyr-7b-beta ""
# ls-scope dataset_id embedding_id umap_id cluster_id cluster_labels_id label description
ls-scope datavis-misunderstood cluster-001-labels-001 "E5 demo" "E5 embeddings summarized by Zephyr 7B"
# start the server to explore your scope
ls-serveRepository overview
This repository is currently meant to run locally, with a React frontend that communicates with a python server backend. We support several popular open source embedding models that can run locally as well as proprietary API embedding services. Adding new models and services should be quick and easy.
To learn more about contributing and the project roadmap see CONTRIBUTION.md, for technical details see DEVELOPMENT.md.
Design principles
This tool is meant to be a part of a larger process. Something that hopefully helps you see things in your data that you wouldn't otherwise have. That means it needs to be easy to get data in, and easily get useful data out.
- Flat files
- All of the data that drives the app is stored in flat files. This is so that both final and intermediate outputs can easily be exported for other uses. It also makes it easy to see the status of any part of the process.
- Remember everything
- This tool is intended to aid in research, the purpose is experimentation and exploration. I developed it because far too often I try a lot of things and then I forget what parameters lead me down a promising path in the first place. All choices you make in the process are recorded in metadata files along with the output of the process.
- It's all about the indices
- We consider an input dataset the source of truth, a list of rows that can be indexed into. So all downstream operations, whether its embeddings, pointing to nearest neighbors or assigning data points to clusters, all use indices into the input dataset.
Command Line Scripts: Detailed description
If you want to use the CLI instead of the web UI you can use the following scripts.
The scripts should be run in order once you have an input.csv file in your folder. Alternatively the Setup page in the web UI will run these scripts via API calls to the server for you.
These scripts expect at the least a LATENT_SCOPE_DATA environment variable with a path to where you want to store your data. If you run ls-serve it will set the variable and put it in a .env file. You can add API keys to the .env file to enable usage of the various API services, see .env.example for the structure.
0. ingest
This script turns the input.csv into input.parquet and sets up the directories and meta.json which run the app.
# ls-ingest <dataset_name>
ls-ingest database-curated1. embed
Take the text from the input and embed it. Default is to use BAAI/bge-small-en-v1.5 locally via HuggingFace transformers. API services are supported as well, see latentscope/models/embedding_models.json for model ids.
# you can get a list of models available with:
ls-list-models
# ls-embed <dataset_name> <text_column> <model_id>
ls-embed dadabase joke transformers-intfloat___e5-small-v22. umap
Map the embeddings from high-dimensional space to 2D with UMAP. Will generate a thumbnail of the scatterplot.
# ls-umap <dataset_name> <embedding_id> <neighbors> <min_dist>
ls-umap dadabase embedding-001 50 0.13. cluster
Cluster the UMAP points using HDBSCAN. This will label each point with a cluster label
# ls-cluster <dataset_name> <umap_id> <samples> <min-samples>
ls-cluster dadabase umap-001 5 34. label
We support auto-labeling clusters by summarizing them with an LLM. Supported models and APIs are listed in latentscope/models/chat_models.json. You can pass context that will be injected into the system prompt for your dataset.
# ls-label <dataset_id> <cluster_id> <chat_model_id> <context>
ls-label dadabase "joke" cluster-001 openai-gpt-3.5-turbo ""5. scope
The scope command ties together each step of the process to create an explorable configuration. You can have several scopes to view different choices, for example using different embeddings or even different parameters for UMAP and clustering. Switching between scopes in the UI is instant.
# ls-scope <dataset_id> <embedding_id> <umap_id> <cluster_id> <cluster_labels_id> <label> <description>
ls-scope datavis-misunderstood cluster-001-labels-001 "E5 demo" "E5 embeddings summarized by GPT3.5-Turbo"6. serve
To start the web UI we run a small server. This also enables nearest neighbor similarity search and interactively querying subsets of the input data while exploring the scopes.
ls-serve ~/latent-scope-dataDataset directory structure
Each dataset will have its own directory in data/ created when you ingest your CSV. All subsequent steps of setting up a dataset write their data and metadata to this directory. There are no databases in this tool, just flat files that are easy to copy and edit.
├── data/ | ├── dataset1/ | | ├── input.parquet # from ingest.py, the dataset | | ├── meta.json # from ingest.py, metadata for dataset, #rows, columns, text_column | | ├── embeddings/ | | | ├── embedding-001.h5 # from embed.py, embedding vectors | | | ├── embedding-001.json # from embed.py, parameters used to embed | | | ├── embedding-002... | | ├── umaps/ | | | ├── umap-001.parquet # from umap.py, x,y coordinates | | | ├── umap-001.json # from umap.py, params used | | | ├── umap-001.png # from umap.py, thumbnail of plot | | | ├── umap-002.... | | ├── clusters/ | | | ├── clusters-001.parquet # from cluster.py, cluster indices | | | ├── clusters-001-labels-default.parquet # from cluster.py, default labels | | | ├── clusters-001-labels-001.parquet # from label_clusters.py, LLM generated labels | | | ├── clusters-001.json # from cluster.py, params used | | | ├── clusters-001.png # from cluster.py, thumbnail of plot | | | ├── clusters-002... | | ├── scopes/ | | | ├── scopes-001.json # from scope.py, combination of embed, umap, clusters and label choice | | | ├── scopes-... | | ├── tags/ | | | ├── ❤️.indices # tagged by UI, powered by tags.py | | | ├── ... # can have arbitrary named tags | | ├── jobs/ | | | ├── 8980️-12345...json # created when job is run via web UI