light-novel-scraper
About
A scraper tool to grab contents of chapters of a light novel and store them as
HTML files to read later. The script utilizes Readability, with a fallback of
grabbing the content-div, to grab relevant text from a website and ebooklib
to generate a ePub if necessary.
Web API utilizes Celery (with Redis) with Flask backend and AngularJS frontend.
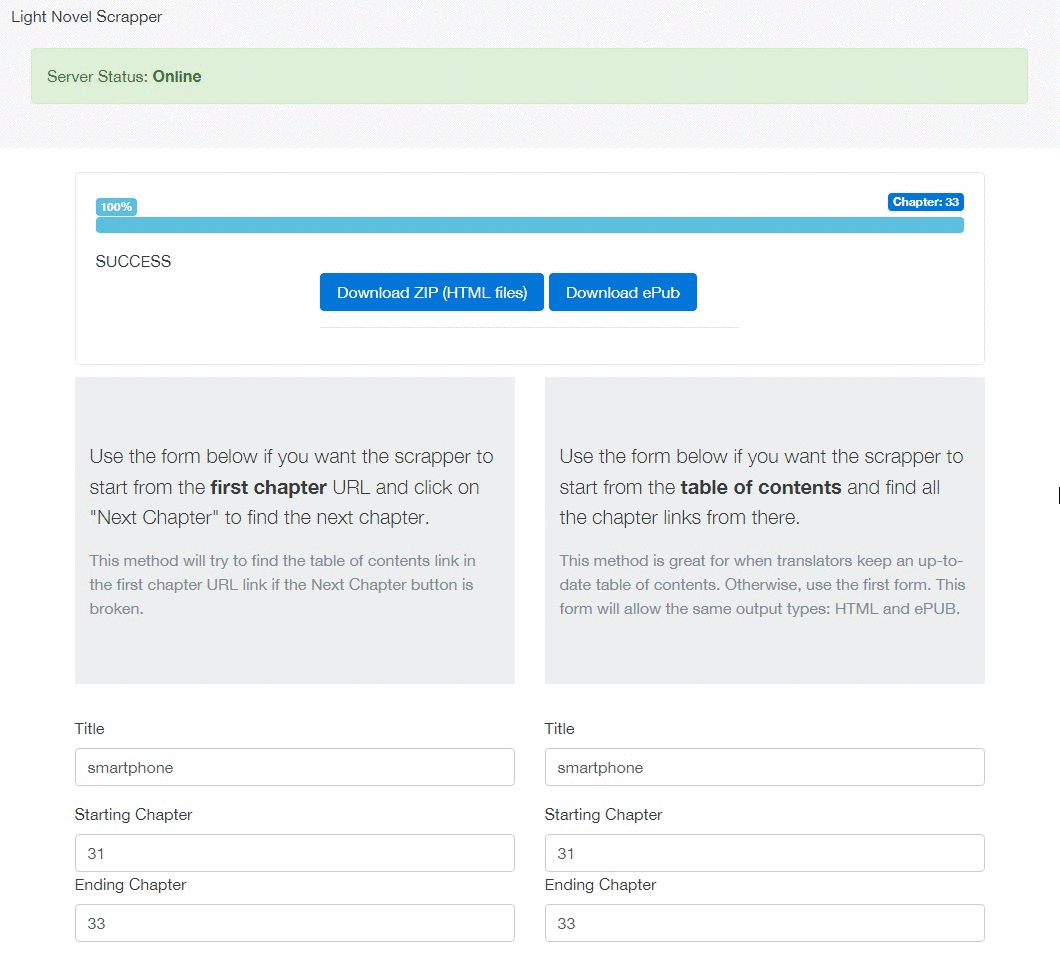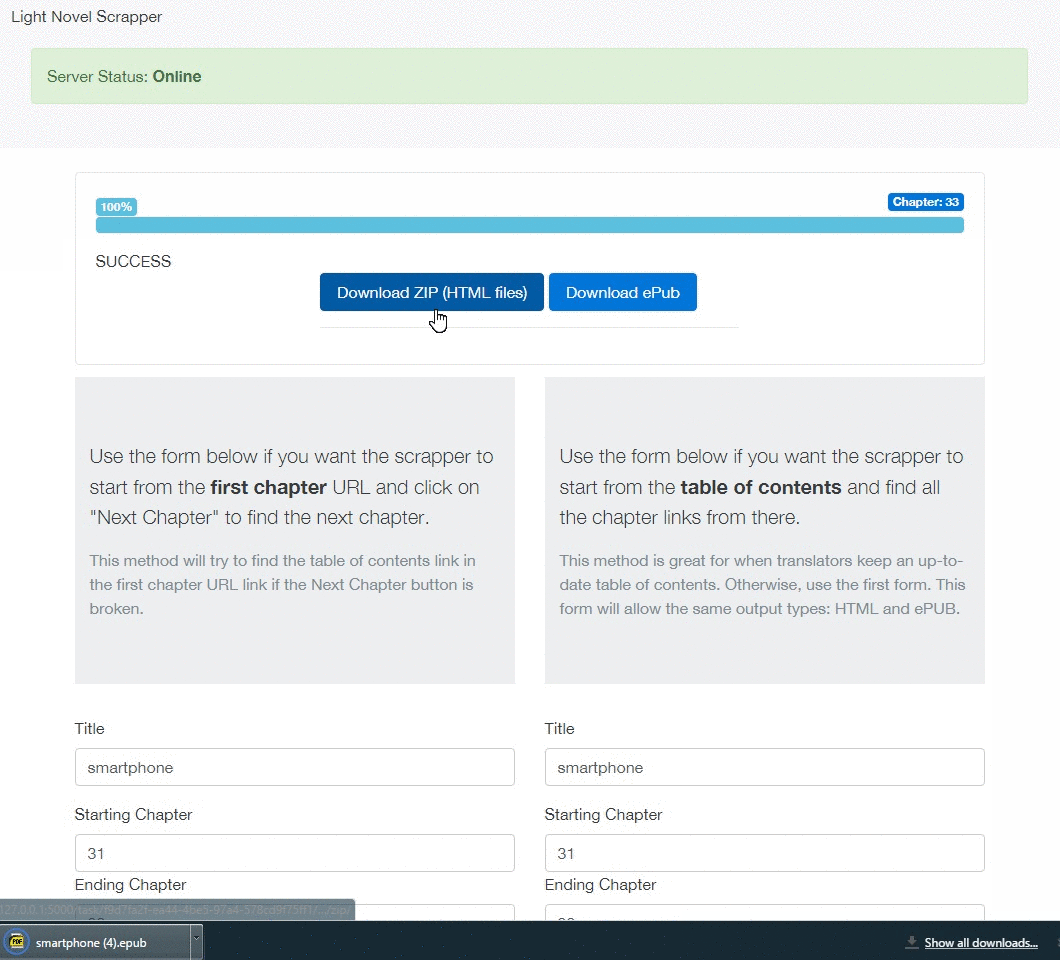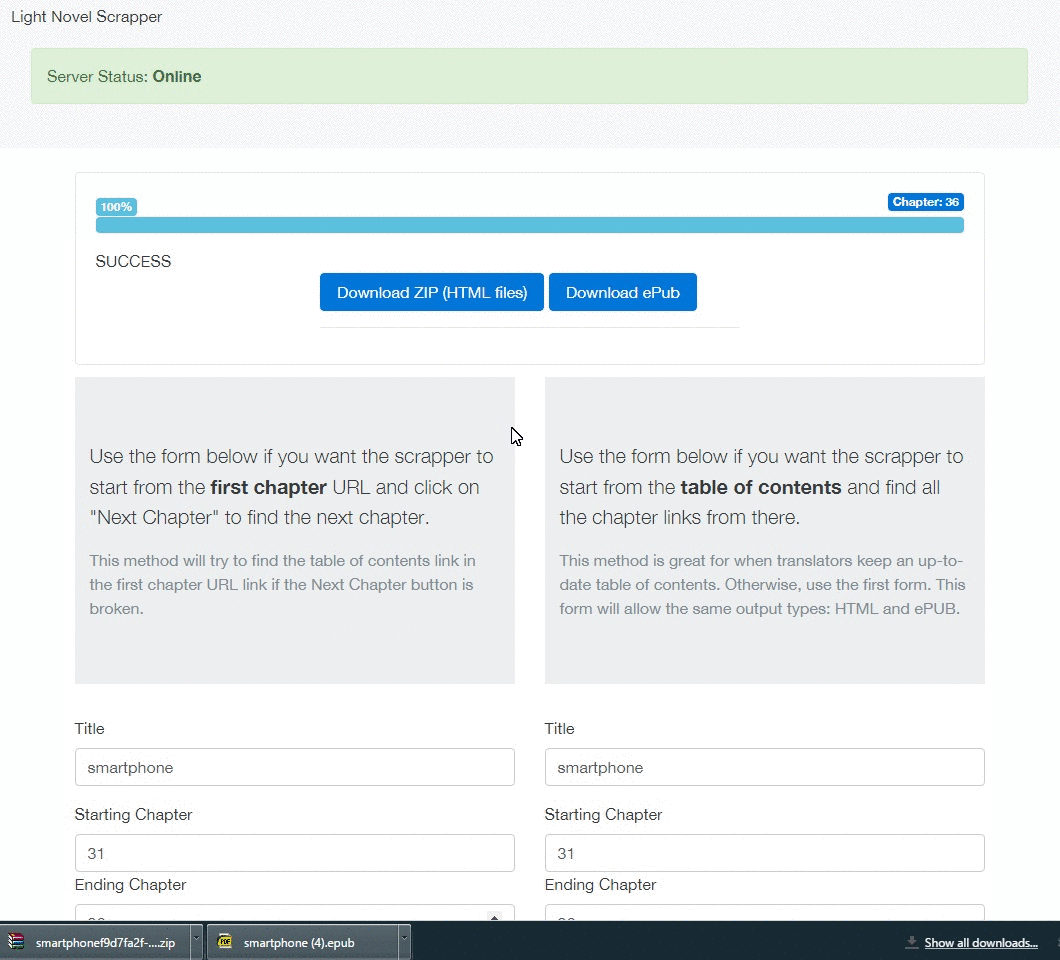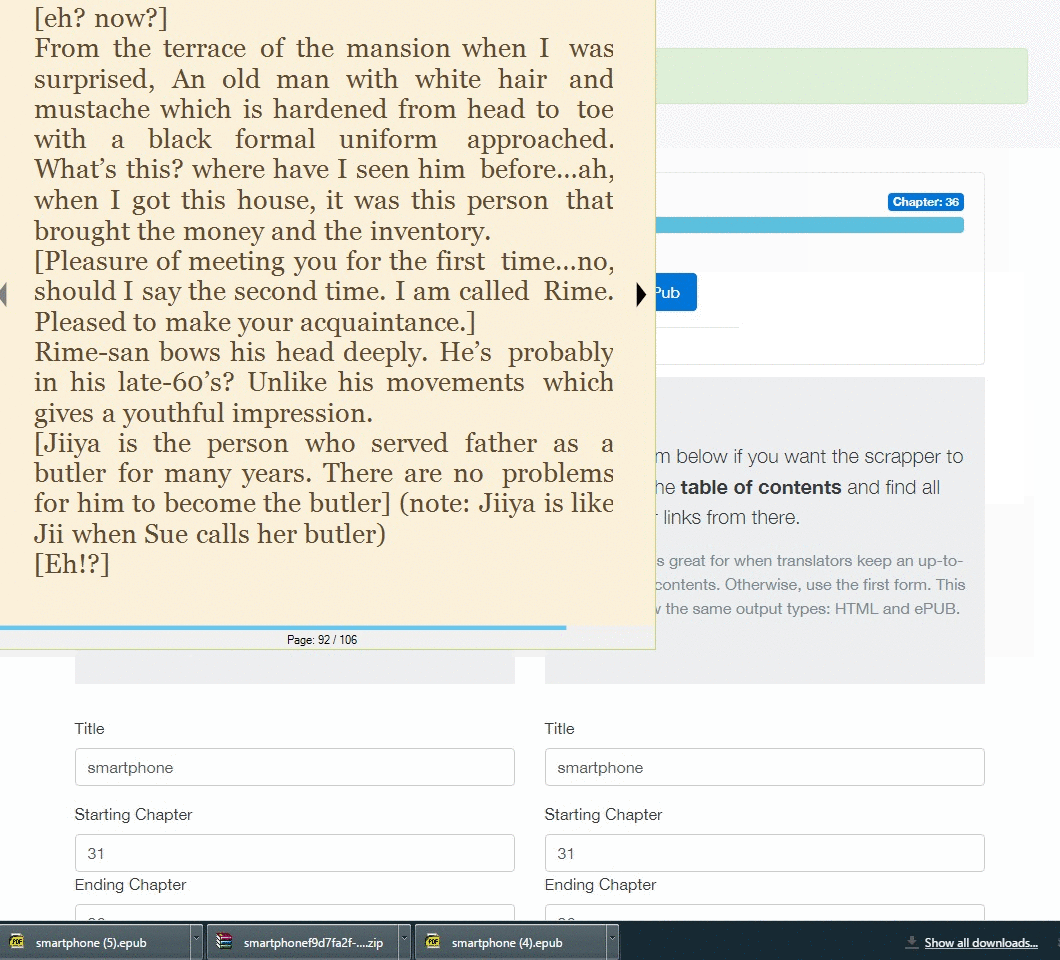
Usage
- Local API
The following will grab all the chapters from 31 to 53:
ls = LightScrap(title='Smartphone',
start_chapter_number=31,
end_chapter_number=53,
url='http://raisingthedead.ninja/2015/10/06/smartphone-chapter-31/')
ls.chapters_walk() # Grab all the HTML files
# Or grab the chapters from the table of contents URL
ls.toc_walk('http://raisingthedead.ninja/current-projects/in-a-different-world-with-a-smartphone/')
ls.make_html_toc() # Make a HTML table of contents file to use with Calibre
ls.generate_epub() # You can generate a ePub, also.- Web API
Use foreman start to start the web server, Redis, and Celery.
GIF example:
Requirements
requirements.txt included.
Not Supported
- Saving images into ePub
- TOC in ePub