![]()
balance: a python package for balancing biased data samples
balance is currently in beta and under active development. Follow us on github!
What is balance?
balance is a Python package offering a simple workflow and methods for dealing with biased data samples when looking to infer from them to some population of interest.
Biased samples often occur in survey statistics when respondents present non-response bias or survey suffers from sampling bias (that are not missing completely at random). A similar issue arises in observational studies when comparing the treated vs untreated groups, and in any data that suffers from selection bias.
Under the missing at random assumption (MAR), bias in samples could sometimes be (at least partially) mitigated by relying on auxiliary information (a.k.a.: “covariates” or “features”) that is present for all items in the sample, as well as present in a sample of items from the population. For example, if we want to infer from a sample of respondents to some survey, we may wish to adjust for non-response using demographic information such as age, gender, education, etc. This can be done by weighing the sample to the population using auxiliary information.
The package is intended for researchers who are interested in balancing biased samples, such as the ones coming from surveys, using a Python package. This need may arise by survey methodologists, demographers, UX researchers, market researchers, and generally data scientists, statisticians, and machine learners.
More about the methodological background can be found in Sarig, T., Galili, T., & Eilat, R. (2023). balance – a Python package for balancing biased data samples.
Installation
Requirements
You need Python 3.8 or later to run balance. balance can be built and run from Linux, OSX, and Windows (NOTE: method="ipw" is currently not supported on Windows).
The required Python dependencies are:
REQUIRES = [
"numpy",
"pandas<=1.4.3",
"ipython",
"scipy<=1.9.2",
"patsy",
"seaborn<=0.11.1",
"plotly",
"matplotlib",
"statsmodels",
"scikit-learn",
"ipfn",
"session-info",
]Note that glmnet_python must be installed from the Github source
See setup.py for more details.
Installing balance
As a prerequisite, you must install glmnet_python from source:
python -m pip install git+https://github.com/bbalasub1/glmnet_python.git@1.0Installing via PyPi
We recommend installing balance from PyPi via pip for the latest stable version:
python -m pip install balanceInstallation will use Python wheels from PyPI, available for OSX, Linux, and Windows.
Installing from Source/Git
You can install the latest (bleeding edge) version from Git:
python -m pip install git+https://github.com/facebookresearch/balance.gitAlternatively, if you have a local clone of the repo:
cd balance
python -m pip install .Getting started
balance’s workflow in high-level
The core workflow in balance deals with fitting and evaluating weights to a sample. For each unit in the sample (such as a respondent to a survey), balance fits a weight that can be (loosely) interpreted as the number of people from the target population that this respondent represents. This aims to help mitigate the coverage and non-response biases, as illustrated in the following figure.
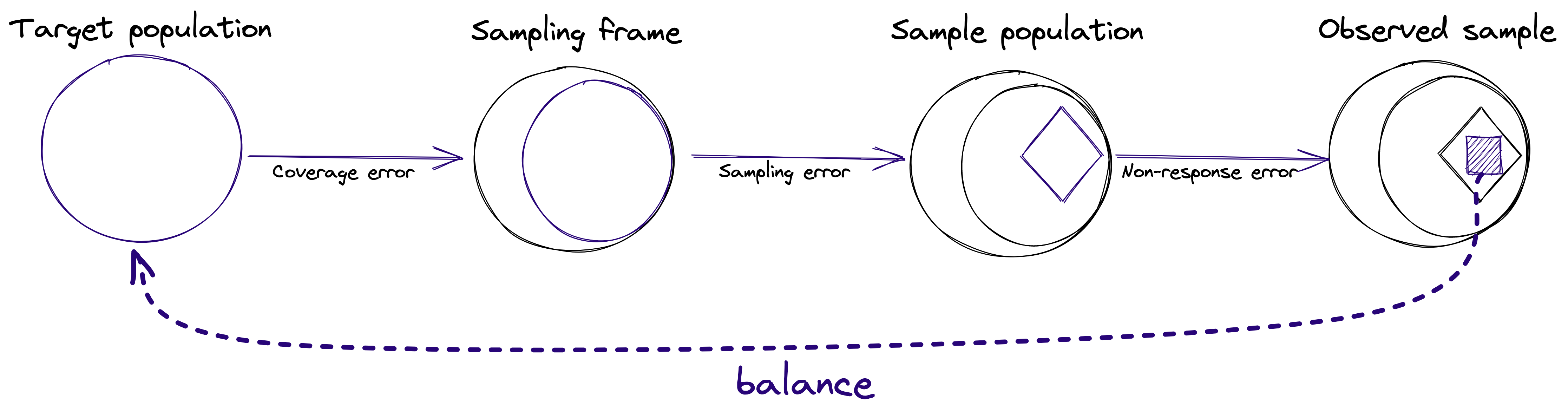
The weighting of survey data through balance is done in the following main steps:
- Loading data of the respondents of the survey.
- Loading data about the target population we would like to correct for.
- Diagnostics of the sample covariates so to evaluate whether weighting is needed.
- Adjusting the sample to the target.
- Evaluation of the results.
- Use the weights for producing population level estimations.
- Saving the output weights.
You can see a step-by-step description (with code) of the above steps in the General Framework page.
Code example of using balance
You may run the following code to play with balance's basic workflow (these are snippets taken from the quickstart tutorial):
We start by loading data, and adjusting it:
from balance import load_data, Sample
# load simulated example data
target_df, sample_df = load_data()
# Import sample and target data into a Sample object
sample = Sample.from_frame(sample_df, outcome_columns=["happiness"])
target = Sample.from_frame(target_df)
# Set the target to be the target of sample
sample_with_target = sample.set_target(target)
# Check basic diagnostics of sample vs target before adjusting:
# sample_with_target.covars().plot()
You can read more on evaluation of the pre-adjusted data in the Pre-Adjustment Diagnostics page.
Next, we adjust the sample to the population by fitting balancing survey weights:
# Using ipw to fit survey weights
adjusted = sample_with_target.adjust()You can read more on adjustment process in the Adjusting Sample to Population page.
The above code gets us an adjusted object with weights. We can evaluate the benefit of the weights to the covariate balance, for example by running:
print(adjusted.summary())
# Covar ASMD reduction: 62.3%, design effect: 2.249
# Covar ASMD (7 variables):0.335 -> 0.126
# Model performance: Model proportion deviance explained: 0.174
adjusted.covars().plot(library = "seaborn", dist_type = "kde")And get:
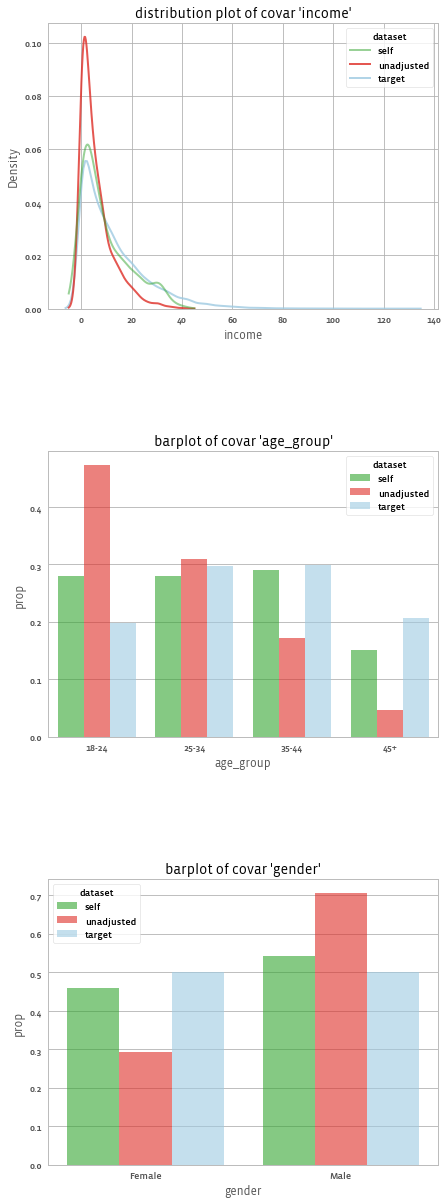
We can also check the impact of the weights on the outcome using:
# For the outcome:
print(adjusted.outcomes().summary())
# 1 outcomes: ['happiness']
# Mean outcomes:
# happiness
# source
# self 54.221388
# unadjusted 48.392784
#
# Response rates (relative to number of respondents in sample):
# happiness
# n 1000.0
# % 100.0
adjusted.outcomes().plot()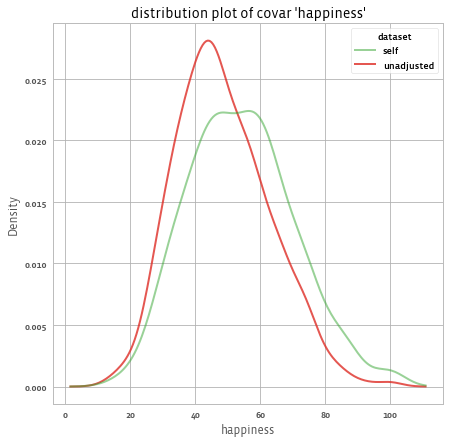
You can read more on evaluation of the post-adjusted data in the Evaluating and using the adjustment weights page.
Finally, the adjusted data can be downloaded using:
adjusted.to_download() # Or:
# adjusted.to_csv()To see a more detailed step-by-step code example with code output prints and plots (both static and interactive), please go over to the tutorials section.
Implemented methods for adjustments
balance currently implements various adjustment methods. Click the links to learn more about each:
- Logistic regression using L1 (LASSO) penalization.
- Covariate Balancing Propensity Score (CBPS).
- Post-stratification.
- Raking.
Implemented methods for diagnostics/evaluation
For diagnostics the main tools (comparing before, after applying weights, and the target population) are:
- Plots
- barplots
- density plots (for weights and covariances)
- qq-plots
- Statistical summaries
- Weights distributions
- Kish’s design effect
- Main summaries (mean, median, variances, quantiles)
- Covariate distributions
- Absolute Standardized Mean Difference (ASMD). For continuous variables, it is Cohen's d. Categorical variables are one-hot encoded, Cohen's d is calculated for each category and ASMD for a categorical variable is defined as Cohen's d, average across all categories.
- Weights distributions
You can read more on evaluation of the post-adjusted data in the Evaluating and using the adjustment weights page.
Other resources
- Presentation: "Balancing biased data samples with the 'balance' Python package" - presented in the Israeli Statistical Association (ISA) conference on June 1st 2023.
More details
Getting help, submitting bug reports and contributing code
You are welcome to:
- Learn more in the balance website.
- Ask for help on: https://stats.stackexchange.com/questions/tagged/balance
- Submit bug-reports and features' suggestions at: https://github.com/facebookresearch/balance/issues
- Send a pull request on: https://github.com/facebookresearch/balance. See the CONTRIBUTING file for how to help out. And our CODE OF CONDUCT for our expectations from contributors.
Citing balance
Sarig, T., Galili, T., & Eilat, R. (2023). balance – a Python package for balancing biased data samples. https://arxiv.org/abs/2307.06024
BibTeX: @misc{sarig2023balance, title={balance - a Python package for balancing biased data samples}, author={Tal Sarig and Tal Galili and Roee Eilat}, year={2023}, eprint={2307.06024}, archivePrefix={arXiv}, primaryClass={stat.CO} }
License
The balance package is licensed under the GPLv2 license, and all the documentation on the site is under CC-BY.
News
You can follow updates on our:
Acknowledgements / People
The balance package is actively maintained by people from the Core Data Science team (in Tel Aviv and Boston), by Tal Sarig, Tal Galili and Steve Mandala.
The balance package was (and is) developed by many people, including: Roee Eilat, Tal Galili, Daniel Haimovich, Kevin Liou, Steve Mandala, Adam Obeng (author of the initial internal Meta version), Tal Sarig, Luke Sonnet, Sean Taylor, Barak Yair Reif, and others. If you worked on balance in the past, please email us to be added to this list.
The balance package was open-sourced by Tal Sarig, Tal Galili and Steve Mandala in late 2022.
Branding created by Dana Beaty, from the Meta AI Design and Marketing Team. For logo files, see here.