 sharon-fdm
commented
2 weeks ago
sharon-fdm
commented
2 weeks ago API draft PR: https://github.com/fleetdm/fleet/pull/18680
Open sharon-fdm opened 2 weeks ago
sharon-fdm
commented
2 weeks ago API draft PR: https://github.com/fleetdm/fleet/pull/18680
Goal
Context
Initial dev estimation: 0.5 - 1
person x sprintBackground:
EDR analyzing all events on a platform
EDR systems typically collect a lot of events and process them on the backend platform/server to create insights and alerts. This has many advantages but also comes with a tag of big cost to upload and analyze massive amounts of events. Can FleetDM do it (collect the events)? Yes. See below the method of real-time collection using scheduled queries routing the logs to a third-party mechanism for analysis.
Detection on the host
An alternative to the above can be creating custom rules for detection directly on the host. This is a powerful way to detect potential events while filtering non-relevant events and saving costs. A good example is creating an SQL query that will only send information if something "wrong" happens, such as:
c:\), or running with more command-line params then expected.Flexibility advantage: OSQuery has a huge advantage of harnessing SQL-based queries to configure specific data collection by filtering it directly on the host. Other typical agents will require a round of development to configure a specific rule.
It's already there...
osquery has an existing way to collect events. There are several event-based tables and there is a lot of material out there to learn about it. TODO Sharon: Add links to articles. As an example, see FIM collection video.
We can collect events without any additional effort
Fleet does not have an integrated way to alert on threats quickly. But we could use two existing mechanisms to collect them: 1 - Policies could show problems on specific hosts but they are collected and updated every ~1 hour which is very slow in case a customer needs events based quick alerts. 2 - Scheduled queries could reroute logs to a third party (as we do in automation) and then run a Python script to identify specific results and warn about them somehow (outside of fleet).
Proposed "Alerts" mechanism
The proposed "Alerts" mechanism here is simple to implement and would allow customers to see threats in "real time". The customer will write high-frequency scheduled queries that should only return a result if something is wrong. e.g.
SELECT * FROM file_events WHERE file_path = some_os_critical_file AND action = "UPDATED";(Run every 30 sec)Changes
Proposed UI change: 1 - Add a checkbox to scheduled-queries named "Alert on any result". If this checkbox is set, all results coming from this query will be kept and presented under the existing cached results area. 2A - Option A: Have an area similar to the cached results that will present all alerts. 2B - Option B: Have the necessary screen to configure a webhook. 3 - TODO: design an option to discard all alerts for a specific query.
Backend: 1 - In DB add a field to scheduled queries called "alert". 2 - In API:
TODO: Replace with a proper Figma file: (Se Alert checkbox at the bottom)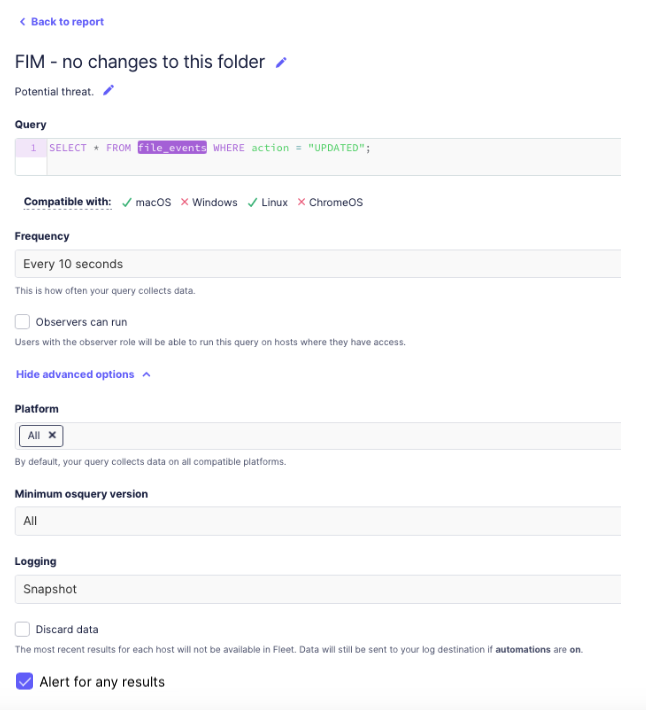
Product
Engineering
QA
Risk assessment
Manual testing steps
Testing notes
Confirmation