 DeanThompson
commented
10 years ago
DeanThompson
commented
10 years ago 多语言共享数据的场景之前也遇到过,用 json 这种跨平台的数据格式可以完美解决。不知道 node 对 protocol-buffer 的支持如何,如果有成熟的库,pb 也可以考虑。
Open fwon opened 10 years ago
DeanThompson
commented
10 years ago 多语言共享数据的场景之前也遇到过,用 json 这种跨平台的数据格式可以完美解决。不知道 node 对 protocol-buffer 的支持如何,如果有成熟的库,pb 也可以考虑。
 sophister
commented
8 years ago
sophister
commented
8 years ago 我们可以有一个折中的方案,就是将基于java实现的session存储为json格式
请教个问题,最终你们是采用的这种方案么,我们也面临同样的case,但后端都不清楚java的session是怎么存储在redis中的……
谢谢
 hwen
commented
7 years ago
hwen
commented
7 years ago 我们现在的做法是 [Nginx] - [Node集群] - [redis集群] - [MongoDB]
Node 这边不会做太多密集型计算,所以还好
主要还是数据库这一层,好像也只能加大数据库的配置了。。。
hwen
commented
7 years ago Node 集群的话就相当于有多个独立的进程在跑同样的服务。
假设有1w个请求过来,没涉及太多计算(主要是查数据库)
Node集群大多能迅速处理这些请求,然后将这1w任务进行排队,等待数据库查询回调,而不会阻塞进程
如果数据库这边响应太慢了,就有可能导致请求超时
基本运用
用Node.js开发过网站的人想必对session都有一定的了解,最近自己也做了这方面的实践,把在开发中发现的问题记录下来,也提供解决问题的思路。
最基本的session实现方式,需要引入两个中间件
cookie-parser和express-session这样就可以在代码中引用和操作请求中的携带的cookie信息和session信息。
现在比较大型的网站一般都采用了集群系统,通常我们需要在不同的机器上共享session。为了保证不同进程间能够共享session,我们必须采用另外一种方式来保存session。通常会有两种方法:
第一种实现的逻辑一般比较复杂,而且不同服务器间session的复制会带来性能的损耗。目前业界多数采用的是第二种解决方案,实现真正的高可用。而相对于保存数据库,Node.js更普遍的做法是保存在缓存系统中,如memcached和redis。由于这种缓存系统都是直接存储在内存空间的,读取效率比操作数据库都要高出许多,当然没中过方案都有各自的优缺点,就要根据具体项目选择最适合自己的解决方案。这里就不科普这几个方案的具体优缺点了。
下面介绍一下基于memcached的Node.js后端session实现。 我们要使用的是connect-memcached组件,该组件依赖于node-memcached。
当然你必须提前安装好memcached客户端,并开启服务。memcached的安装可以参考这里。
多后台session共存
在某次重构中面对了一个难题,由于后端是用java开发的,针对某些新功能,我们需要用Node重新实现后端,而就功能任然保留java后端,所以就存在两种语言处理session的问题。好在项目之前就是采用memcached来存储session做负载均衡的。我们想到了两种解决方案。
解决方案: 相对来说第一种实现方案优于第二种实现方案,不会对性能造成影响,但是这种session的反序列化还是有一定的实现难度,目前好像还木有可用的组件。考虑到这些点,我们可以有一个折中的方案,就是将基于java实现的session存储为json格式。然后我们再采用第一种方案,从memcached中读取json格式存储的session,再解析json获取对象数据。这是一个比较理想的方案。不官管后端使用什么语言实现,memcached存储的是一种标准化的统一的格式。读取解析的道理都是一样的,不必去实现不同的decode方法。但对于这种session存储方式带来的问题暂时还没做研究。
负载均衡
为什么这里要讲负载均衡呢,本来只是打算讨论session的运用和共享方案。但有后端的同学提出了问题,“听说Node是单线程的,即使实现了登录模拟和session存储,你怎么做负载均衡呢?” 下面就总结一下Node在负载均衡的一些常规的玩法。 将负载均衡前,有必要扯一扯单线程和多线程。下面两幅图能很好说明多线程和单线程服务器请求的区别:
多线程模型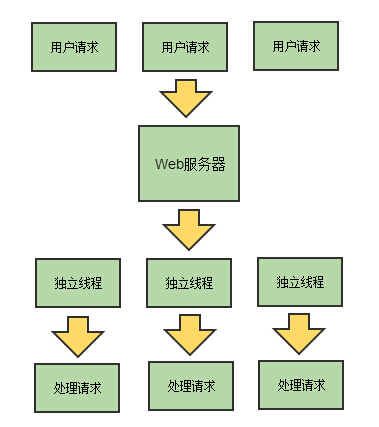 Node.js模型
Node.js模型
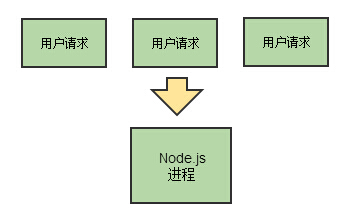
Node.js的单线程让程序猿不必再去烦恼多线程对变量的加锁解锁,也避免了多线程切换造成的开销,同时还减少了内存的暂用,看起来好像更安全了。 但是,在对于cpu密集型的计算时,Node.js就会暴露出其缺点,尽管Node.js使用的是异步的编程范式,也有可能因为大量的计算造成线程阻塞。 那么Node.js是怎样来解决这类问题的呢? 要让Node.js支持多线程,官方的做法就是通过libuv库来实现的。
Node.js核心api中的异步多线程大多是用libuv来实现的。 cluster 除了用libuv实现多线程,还可以通过cluster创建子进程,充分利用多核cpu,脑洞全开。
numCPUS实际上为CPU的核数。当判断cluster.isMaster主进程时,会创建numCPUs个子进程。cluter通过IPC(Inter-Process Communication,进程间通信)实现master进程和子进程间的通信。
Nginx Nginx是一个高性能的HTTP和反向代理服务器。我们可以使用Nginx开处理静态文件和反向代理。如开启多个进程,每个进程绑定不同的端口,用Nginx 做负载均衡以减少Node.js的负载。虽然Node.js也有一些如http-proxy的代理模块可以实现,但这种基础性的工作,更应该交给nginx来做。这里就不讲解ngnix的具体使用了。
本文待深入...