Open fwon opened 7 years ago
大家对上一篇文章中提到的UCS编码可能比较陌生。殊不知这就是JavaScript采用的编码方法。
既然Unicode已经统一了天下,为什么JavaScript不采用UTF的编码方法呢?原因很简单,因为JavaScript诞生的时候UTF-8还尚未成熟,UTF-16更是到后面才出现,而此时UCS已经先行一步地完成了UCS-2。所以JavaScript采用了比UTF更早的UCS。也就是UCS-2。(记住只是编码方法,实际上字符集还是Unicode字符集)
从命名上看,我们很容易猜出UCS-2占用2个字节。而UTF-16占用16位,也是2个字节,那他们的编码方式有什么不同呢? 对于2个字节的码点,UCS-2和UTF-16是没有什么区别的。在基本平面上(2^16),UTF-16沿用了UCS-2的编码,另外在辅助平面上,UTF-16还定义了4个字节的表示方法。简单来说,UTF-16可看成是UCS-2的父集。在没有辅助平面字符前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。
由于JavaScript只能处理UCS-2编码,造成所有字符都是2个字节,如果是4个字节的字符,会被当做两个双字节的字符处理。受到这个的影响,JavaScript中的字符操作函数某些情况无法返回正确的结果。
对于两个字节的字符,js能够根据码点直接输出对应字符。例如小写字母'a'的Unicode编码就是U+0061。
U+0000 - U+00FF的码点,还有另外一种表示方法,称为16进制转义序列。用'\x'开头,后面跟两位的16进制符。
大于两个字节的码点,JavaScript就有点力不从心了。例如字符
这个符号的字符码点为 "U+1F4A9", 控制台的输出结果是这样的
这显然不是正确的结果,那么这个符号是怎么产生的呢?
由于UCS-2每次只能读取两个字节,所以 "U+1F4A9"被解读为U+1F4A 和 9, 查阅Unicode映射表U+1F4A 对应的是希腊语的扩展,就是是符号0加一点。
剩下的9则被识别为普通的字符串符号'9'输出了。
既然JavaScript无法处理大于两个字节的符号,那对于互联网上成千上万的复杂字符和表情,岂不是束手无策?
非也!
我们在控制台输出这个码点:”\uD83D\uDCA9″
神奇的事情发生了,”\uD83D\uDCA9″竟然也能输出符号。
如果我们单独输出这两个码点,看会输出什么字符:
两个字符单独输出都是乱码,Unicode无法识别对应的字符。再次查阅映射表。
发现这两个码点分别落在了UTF-16的高半位和低半位。
原来UTF-16碰到第一个双字节码点在D800-DBFF之间时,代码不会直接读取符号,而是将其存储为高半区,再往下读取两个字节的低半区,合在一起再输出符号。而这也是UCS-2的处理方式。
那么 "U+1F4A9"怎么转化为高低位”\uD83D\uDCA9"呢,下面是转换公式:
H = Math.floor((0x1F4A9-0x10000)/0x400)+0xD800 = 0xD83D L = (0x1F4A9-0x10000) % 0x400+0xDC00 = 0xDCA9
既然我们已经能够在JavaScript中输出辅助平面的字符了,那不是万事大吉了吗?
考虑一个常用的前端场景——输入框,通常会规定最大输入字数。尝试输出上面的符号长度, 发现长度是2。
这与我们的认知有点不同,我们通常认为一个表情符号也是一个字符,长度为1。而如果通过"xxx".length 来判断字符串长度显然是不够准确的。这个问题在ES6中能迎刃而解:
ES6中通过Array.from能准确读取字符长度
然而Array.from不是完美的,在某些场景下也无法满足需求,况且还存在ES6的浏览器兼容性问题。
在ES5中,我们通过正则的判断,也能得到Array.from的效果,而且扩展性更高:
var regexAstralSymbols = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g; function countSymbols(string) { return string // 替换掉辅助平面的连字符 .replace(regexAstralSymbols, '_') .length; } countSymbols('\uD835\uDC00'); //1
另外,JavaScript也提供了从码点到字符的转换函数。
//这里直接输入进制数0x0061或97,而不是字符串 String.fromCharCode(0x0061); //a //输出为10进制数 'a'.charCodeAt(0);//97 (16进制0x0061)
而对于附加平面的符号,JavaScript又要跪了, 直接输出低位 U+F4A9的字符,而该字符位于Unicode的私用区,未定义,所以输出''。
String.fromCharCode(0x1F4A9);//''
同样的,我们将符号U+1F4A9变为高地位输入,就能成功输出符号
对于fromCharCode和charCodeAr这两个方法,ES6 也提供了新的接口,对应fromCodePoint和codePointAt,问题得到解决:
在处理字符串逆转,正则的匹配上,附加字符都会有问题,要处理这些问题,只有一条准则,就是要对附加码点做特殊处理。在ES6还没全面支持的情况下,只能通过定义各种hack方法来解决。
关于Unicode跟JavaScript的纠葛就讲到这,乱码问题让人费解,但是只要了解了基本原理,问题往往就能迎刃而解。
参考文章: https://zh.wikipedia.org/wiki https://mathiasbynens.be/notes/javascript-unicode http://www.ruanyifeng.com/blog/2014/12/unicode.html
大家对上一篇文章中提到的UCS编码可能比较陌生。殊不知这就是JavaScript采用的编码方法。
既然Unicode已经统一了天下,为什么JavaScript不采用UTF的编码方法呢?原因很简单,因为JavaScript诞生的时候UTF-8还尚未成熟,UTF-16更是到后面才出现,而此时UCS已经先行一步地完成了UCS-2。所以JavaScript采用了比UTF更早的UCS。也就是UCS-2。(记住只是编码方法,实际上字符集还是Unicode字符集)
UCS-2 与 UTF-16
从命名上看,我们很容易猜出UCS-2占用2个字节。而UTF-16占用16位,也是2个字节,那他们的编码方式有什么不同呢? 对于2个字节的码点,UCS-2和UTF-16是没有什么区别的。在基本平面上(2^16),UTF-16沿用了UCS-2的编码,另外在辅助平面上,UTF-16还定义了4个字节的表示方法。简单来说,UTF-16可看成是UCS-2的父集。在没有辅助平面字符前,UTF-16与UCS-2所指的是同一的意思。但当引入辅助平面字符后,就称为UTF-16了。
由于JavaScript只能处理UCS-2编码,造成所有字符都是2个字节,如果是4个字节的字符,会被当做两个双字节的字符处理。受到这个的影响,JavaScript中的字符操作函数某些情况无法返回正确的结果。
对于两个字节的字符,js能够根据码点直接输出对应字符。例如小写字母'a'的Unicode编码就是U+0061。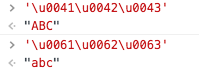
U+0000 - U+00FF的码点,还有另外一种表示方法,称为16进制转义序列。用'\x'开头,后面跟两位的16进制符。
大于两个字节的码点,JavaScript就有点力不从心了。例如字符
这个符号的字符码点为 "U+1F4A9", 控制台的输出结果是这样的
这显然不是正确的结果,那么 这个符号是怎么产生的呢?
这个符号是怎么产生的呢?
由于UCS-2每次只能读取两个字节,所以 "U+1F4A9"被解读为U+1F4A 和 9, 查阅Unicode映射表U+1F4A 对应的是希腊语的扩展,就是是符号0加一点。
剩下的9则被识别为普通的字符串符号'9'输出了。
既然JavaScript无法处理大于两个字节的符号,那对于互联网上成千上万的复杂字符和表情,岂不是束手无策?
非也!
我们在控制台输出这个码点:”\uD83D\uDCA9″
神奇的事情发生了,”\uD83D\uDCA9″竟然也能输出 符号。
符号。
如果我们单独输出这两个码点,看会输出什么字符:
两个字符单独输出都是乱码,Unicode无法识别对应的字符。再次查阅映射表。
发现这两个码点分别落在了UTF-16的高半位和低半位。
原来UTF-16碰到第一个双字节码点在D800-DBFF之间时,代码不会直接读取符号,而是将其存储为高半区,再往下读取两个字节的低半区,合在一起再输出符号。而这也是UCS-2的处理方式。
那么 "U+1F4A9"怎么转化为高低位”\uD83D\uDCA9"呢,下面是转换公式:
既然我们已经能够在JavaScript中输出辅助平面的字符了,那不是万事大吉了吗?
常见问题
考虑一个常用的前端场景——输入框,通常会规定最大输入字数。尝试输出上面的符号长度, 发现长度是2。
这与我们的认知有点不同,我们通常认为一个表情符号也是一个字符,长度为1。而如果通过"xxx".length 来判断字符串长度显然是不够准确的。这个问题在ES6中能迎刃而解:
ES6中通过Array.from能准确读取字符长度
然而Array.from不是完美的,在某些场景下也无法满足需求,况且还存在ES6的浏览器兼容性问题。
在ES5中,我们通过正则的判断,也能得到Array.from的效果,而且扩展性更高:
另外,JavaScript也提供了从码点到字符的转换函数。
而对于附加平面的符号,JavaScript又要跪了, 直接输出低位 U+F4A9的字符,而该字符位于Unicode的私用区,未定义,所以输出''。
同样的,我们将符号U+1F4A9变为高地位输入,就能成功输出 符号
符号
对于fromCharCode和charCodeAr这两个方法,ES6 也提供了新的接口,对应fromCodePoint和codePointAt,问题得到解决:
在处理字符串逆转,正则的匹配上,附加字符都会有问题,要处理这些问题,只有一条准则,就是要对附加码点做特殊处理。在ES6还没全面支持的情况下,只能通过定义各种hack方法来解决。
关于Unicode跟JavaScript的纠葛就讲到这,乱码问题让人费解,但是只要了解了基本原理,问题往往就能迎刃而解。
参考文章: https://zh.wikipedia.org/wiki https://mathiasbynens.be/notes/javascript-unicode http://www.ruanyifeng.com/blog/2014/12/unicode.html