Voxel-MAE - Masked Autoencoders for Self-Supervised Learning on Automotive Point Clouds
This is the official implementation of the WACV 2023 PVL workshop paper Masked Autoencoders for Self-Supervised Learning on Automotive Point Clouds.
Usage
Environment
PyTorch >= 1.9 is recommended for a better support of the checkpoint technique. (or you can manually replace the interface of checkpoint in torch < 1.9 with the one in torch >= 1.9.)
The implementation builds upon code from SST, which in turn is based on MMDetection3D. Please refer to their getting_started for getting the environment up and running.
Training models
The training procedure is the same as the one in SST. Please refer to ./tools/train.py or ./tools/dist_train.sh for details.
Pre-training models
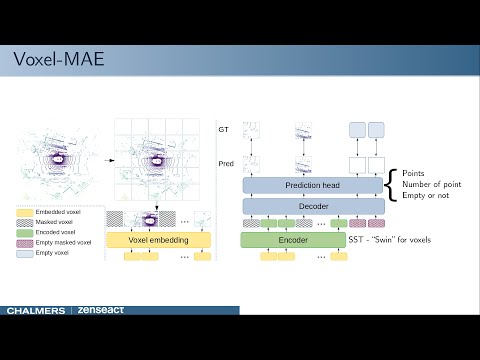
In ./configs/sst_masked/, we provide the configs used for pre-training. For instance, sst_nuscenes_2sweeps-remove_close-cpf-scaled_masked_200e_ED8.py is the config used for pre-training the two sweep model, and sst_nuscenes_10sweeps-remove_close-cpf-scaled_masked_200e.py is the config used for pre-training the ten sweep model. The config with suffix intensity.py use intensity information. remove-close refers to removal of points hitting the ego-vehicle. cpf refers to using the three pre-training tasks (Chamfer, #points and "fake"/empty voxels). 200e refers to the number of epochs used for pre-training.
For pre-training on varying fractions of the dataset, use configs with suffix fifths.py. For instance, sst_nuscenes_2sweeps-remove_close-cpf-scaled_masked_200e_ED8_1fifths.py is the config used for pre-training the two sweep model on the first fifth of the dataset.
For pre-training with a subset of the pre-training tasks, use variations of cpf, e.g. cf refers to using Chamfer and fake voxels, pf refers to using #points and fake voxels, etc.
Fine-tuning models
After pre-training, we can use the pre-trained checkpoints to initialize the 3D OD model. Again, training is started with tools/train.py or tools/dist_train.sh. However, to load the pre-trained weights, we need to use the --cfg-options option with load_from. For instance, tools/dist_train.sh $CONFIG $GPUS --cfg-options load_from=$PATH_TO_PRETRAINED_CHECKPOINT. For training models from scratch, simply disregards the load_from. For evaluation every 12th epoch one can use --cfg-options evaluation.metric=nuscenes.
Configs for fine-tuning can be found in ./configs/sst_refactor. We use sst_2sweeps_VS0.5_WS16_ED8_epochs288.py and sst_10sweeps_VS0.5_WS16_ED8_epochs288.py for training the two and ten sweep models. The config with suffix intensity.py use intensity information. VS0.5 refers to voxel size of 0.5. WS16 refers to window size 16. ED8 refers to the encoder depth of 8.
Similar to pre-training configs, we provide versions for different dataset sizes, e.g. 1fiths, 1twentieth and 1hundreth use 20%, 5% and 1% of the available data.
How to use Docker
We provide a Dockerfile to build an image.
# build an image with PyTorch 1.9, CUDA 10.2
cd docker
bash build.sh
bash run.sh ENTER_YOUR_VOLUME_PASSAcknowledgments
This project is based on the following codebases.