 jart
commented
1 year ago
jart
commented
1 year ago I'm sorry page fault disk i/o on Windows is going slow for you!
The best we can do here is find some trick to coax better performance out of your Windows executive. Could you please try something for me? Take this code:
HANDLE proc;
WIN32_MEMORY_RANGE_ENTRY entry;
proc = GetCurrentProcess();
entry.VirtualAddress = addr;
entry.NumberOfBytes = length;
if (!PrefetchVirtualMemory(proc, 1, &entry, 0)) abort();And put it at the end of the mmap_file() function in llama.cpp. Then compile. Reboot, Try again. If it helps, we'll use that.
Do you have a spinning disk? If you do, then another thing we could try if prefetch doesn't work, is having a loop where we do a volatile poke of each memory page so they're faulting sequentially. That could help the executive to dispatch i/o in a way that minimizes disk head movement. Although it's more of a long shot.
Other than those two things, I'm not sure how we'd help your first case load times. The good news though is that subsequent runs of the LLaMA process will go much faster than they did before!
 anzz1
anzz1 fgdfgfthgr-fox
fgdfgfthgr-fox BadisG
BadisG CoderRC
CoderRC PriNova
PriNova slaren
slaren Piezoid
Piezoid prusnak
prusnak x02Sylvie
x02Sylvie
 patrakov
patrakov danielzgtg
danielzgtg comex
comex github-actions[bot]
github-actions[bot]
Hello,
As of https://github.com/ggerganov/llama.cpp/pull/613 I have experienced significant regression in model loading speed (I'm on windows, compiled msvc llama.cpp, llama.cpp is located on HDD to prevent SSD wear in my case)
It takes roughly 15 minutes for model to load first time after each computer restart/hibernation, during this time my HDD usage is at 100% and my non-llama.cpp read/write operations are slowed down on my pc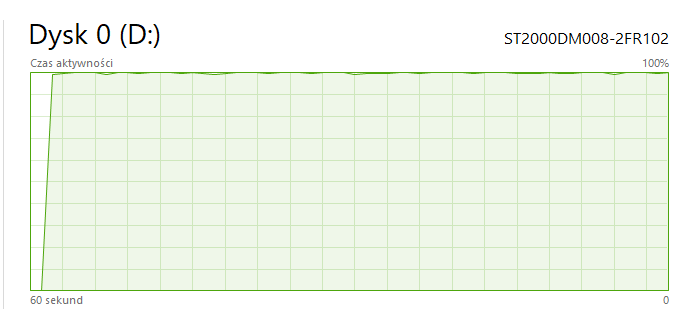
Before that, previous commits took 60 - 180 seconds at worst to load model first time, and after first loading occured, model loaded within 5 - 10 seconds on each program restart until pc reboot/hibernation
Before Commit:
After: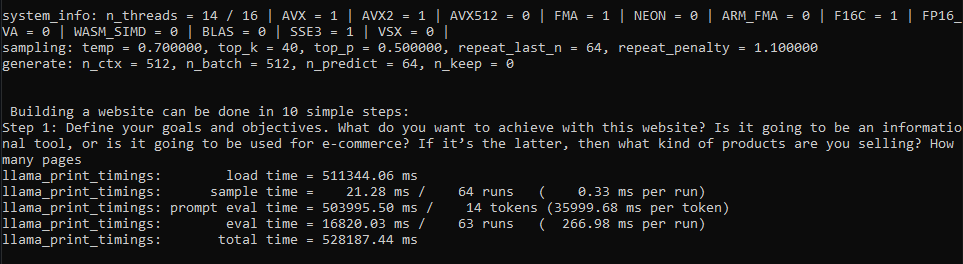
I see reason why model might load faster for some while slower (like my case) for others after recent changes, therefore in my opinion best solution is adding parameter that lets people disable llama.cpp's recent model loading changes if thats possible