 gilbertchen
commented
6 years ago
gilbertchen
commented
6 years ago The new files like Image.xmp and Image2.xmp usually do not affect existing chunks for Image1.raw and Image2.raw. Rather, new files are bundled together and then split into new chunks. However, when you use the -hash option, then Duplicacy will repack all files in order and then split them. This could create tons of new chunks and make previously created chunks obsolete, especially if the average file size isn't much larger than the average chunk size. The same happens when you selectively move a few files from one folder to another.
If you suspect this is the case, then reducing the chunk size is the first option. A chunk size of 1M (instead of the default 4M) has been shown to be able to significantly improve the deduplication efficiency: https://duplicacy.com/issue?id=5740615169998848 and https://duplicacy.com/issue?id=5747610597982208. Unfortunately, you can't change the chunk size after you initialize the storage. You will need to start a new one.
The technique mentioned in #248 (which @fracai actually implemented on his branch) is another possibility. By introducing artificial chunk boundaries at large files, it can be guaranteed that moving larges files to a new location won't lead to any new chunks. However, this technique could potentially create many chunks that are too small and I'm unsure it would be better than just reducing the average chunk size.
It is possible to retrospectively check the effect of different chunk sizes on the deduplication efficiency. First, create a duplicate of your original repository in a disposable directory, pointing to the same storage:
mkdir /tmp/repository
cd /tmp/repository
duplicacy init repository_id storage_urlAdd two storages (ideally local disks for speed) with different chunk sizes:
duplicacy add -c 1M test1 test1 local_storage1
duplicacy add -c 4M test2 test2 local_storage2Then check out each revision and back up to both local storages:
duplicacy restore -overwrite -delete -r 1
duplicacy backup -storage test1
duplicacy backup -storage test2
duplicacy restore -overwrite -delete -r 2
duplicacy backup -storage test1
duplicacy backup -storage test2Finally check the storage efficiency using the check command:
duplicacy check -tabular -storage test1
duplicacy check -tabular -storage test2 jonreeves
jonreeves fracai
fracai kairisku
kairisku TowerBR
TowerBR TheBestPessimist
TheBestPessimist thrnz
thrnz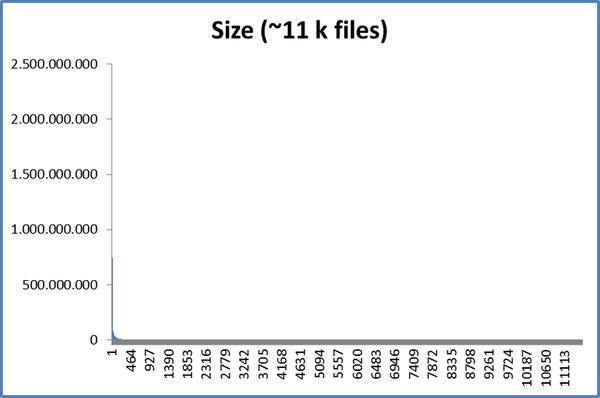
I think this may be related to issue #248 .
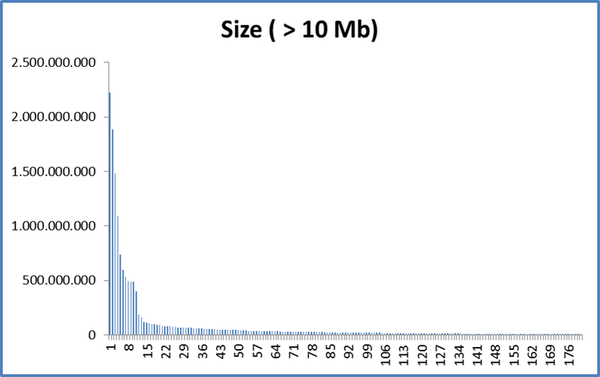
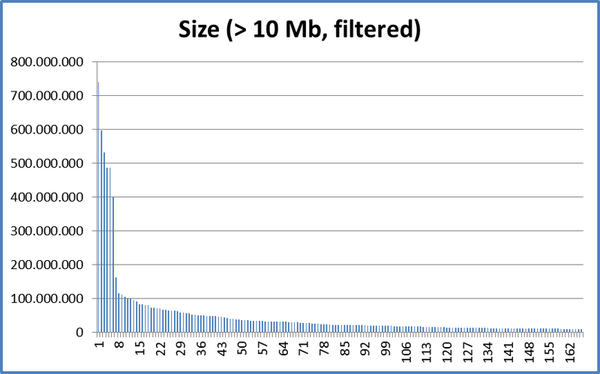
I noticed that backups of my active folders were growing in size significantly where I expected them to change very little. The best example I can give is my "Photos" folder/snapshot...
I regularly download my sd cards to a temporary named project folder under a "Backlog" subfolder. It can be days or months before I work on these images, but usually this will involve Renaming ALL the files and separating them into subfolders by Scene/Location or Purpose (print, portfolio, etc...). The project folder gets renamed too and the whole thing is then moved from out of "Backlog" to "Catalogued". None of the content of any of the files have physically changed during all this, file hashes should be the same.
The renaming and moving alone appears to be enough to make the backup double in size. Any image edits in theory shouldn't have an impact as typically the original file is untouched... The good thing about modern photo processing is edits are non destructive to the original image file. Instead and XML sidecar file is saved along side the image file with meta about the edits applied.
I'm yet to test the impact of making image edits but I suspect it may make things worse because each file gets another file added after it, and it seemed like file order made a difference to how the rolling hash was calculated.
Becomes...
This should be perfect for an incremental backup system, but it seems like duplicacy struggles under these circumstances. I figured the
-hashoption might help, but it didn't seem to.Am I doing something wrong or missing an option?
Is this a bug, or just a design decision?
Is there any possible way to improve this?
Although the above example may sound unique I find this happens in almost all my everyday folders. Design projects, website coding projects, Files and Folders are just often reorganized.
I'm guessing the only way to reclaim this space would be to prune the older snapshots where the files were named differently?