The Open Source Survey
We've run one of the largest surveys of the open source community with open datasets for us all to use and learn from. Our latest survey conducted in 2024 updates the dataset and offers fresh insights into the open source ecosystem. We hope these datasets inform some of the most pressing questions about open source software, the people that create it, their experience, and their relationship to the industry that depends on it.
Learn more about the survey design and the topics we're studying.
Why is GitHub doing this?
At GitHub our goal is to help everyone build better software. We believe open source code, communities, and principles create better software. As an industry, we know a lot about how open source software is created but very little about the people who create and use it. Are they professional developers, students, or hobbyists?
To build better software, then we need a software community where anyone, regardless of what they look like or where they come from, can participate. This survey will help us see how we, as a community, are doing.
Open data
Open source is bigger than any company or community. The dataset is released under CC0-1.0 for anyone to use and learn from.
Contributors
GitHub Open Source Survey 2024
Thank you Kenyatta Forbes, Kevin Xu, Jeffrey Luszcz, Margaret Tucker, Eva Maxfield Brown, Peter Cihon, Mike Linksvayer, Ashley Wolf, Lukas Spieß, Kevin Crosby, Jason Meridth.
GitHub Open Source Survey 2017
This survey is primarily designed and implemented by GitHub:
- @franniez - Data and social scientist at GitHub. New to open source but not to studying people or movements, she's done extensive survey research in Washington D.C, from inside the ivory tower, and within the technology sector.
- @arfon - Program Manager for Open Source Data at GitHub. A lapsed academic with a passion for new models of scientific collaboration, he's used big telescopes to study dust in space, built sequencing technologies in Cambridge, and has engaged millions of people in online citizen science by co-founding the Zooniverse.
- @mlinksva - Open Source Maven at GitHub. A lapsed engineer and non-lawyer with a passion for increasing the efficacy and scope of open production and policy, he is an advisor/director/volunteer for various open initiatives and was previously a manager and technologist at Creative Commons.
This isn't a solo effort for us, these awesome individuals and organizations have helped us design this survey:
- @annafil - Postdoctoral researcher at Carnegie Mellon University, Institute for Software Research
- Open Source Initiative
Check out the contributing guidelines if you want to get involved.
License
The material in this repo is open data released under CC0-1.0. This means you need no copyright or database right (if any) permissions to make use of this data and survey questions. However:
- Survey participants have not waived their privacy rights; read our Privacy Statement regarding Public Information on GitHub. In particular, do not attempt to reidentify survey participants.
- If you use this dataset in a publication, a link to or citation of this repository would be appreciated.
- If you extend this dataset, sharing your additions as open data would also be appreciated.
- CC0-1.0 does not grant any trademark permissions. GitHub® and its stylized versions and the Invertocat mark are GitHub's Trademarks or registered Trademarks. When using GitHub's logos, be sure to follow the GitHub logo guidelines.
Citation info
GitHub Open Source Survey 2024
The data is additionally published on Zenodo, which provides a DOI as well as an easy way to generate citations in a number of formats. We suggest modifying autogenerated citations to reflect the original publication source, e.g as below.
@misc{GitHub_GitHub_Open_Source,
author = {{GitHub, Inc.} and Forbes, Kenyatta and Xu, Kevin and Luszcz, Jeffrey and Tucker, Margaret and Brown, Eva Maxfield and Cihon, Peter and Linksvayer, Mike and Wolf, Ashley and Speiß, Lukas and Crosby, Kevin and Meridth, Jason},
title = {{GitHub Open Source Survey 2024}},
month = oct,
year = 2024,
doi = {10.5281/zenodo.13989018},
publisher = {GitHub, Inc.},
url = {https://github.com/github/open-source-survey}
}GitHub Open Source Survey 2017
The data is additionally published on Zenodo, which provides a DOI as well as an easy way to generate citations in a number of formats. We suggest modifying autogenerated citations to reflect the original publication source, e.g as below.
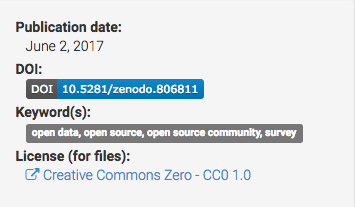
@misc{GitHubOpenSourceSurvey2017,
author = {Zlotnick, Frances},
title = {GitHub Open Source Survey 2017},
month = jun,
year = 2017,
doi = {10.5281/zenodo.806811},
publisher = {GitHub, Inc.},
howpublished = {\url{http://opensourcesurvey.org/2017/}}
}Citations and Reuse
- R. Stuart Geiger Summary Analysis of the 2017 GitHub Open Source Survey "presenting frequency counts, proportions, and frequency or proportion bar plots for every question asked in the survey."
- The LibreOffice Design Team asked users what aspects of open source are important, using questions from the Open Source Survey. Their summary includes a comparison with Open Source Survey responses, and their data is also released under CC0-1.0.
Acknowledgement
This survey was designed by GitHub with valuable input from the research and open source communities. We especially thank: Anna Filippova (Carnegie Mellon University), Andrea Forte (Drexel University), Edward Galvez (Wikimedia Foundation), Rebecca Weiss (Mozilla), and Laura Dabbish (Carnegie Mellon University) for conversations, research questions, and prior art that informed the questionnaire design; the Open Source Initiative for offsite sampling recruitment, the many members of the community who assisted with translations and suggestions for improving questions; and everyone who participated in the survey.