 gcp
commented
6 years ago
gcp
commented
6 years ago Thinking about it, the value head coming from a single 1 x 8 x 8 means it can only represent 64 evaluations. This would already be little for Go, where ahead or behind can be represented in stones. But for chess, where we often talk about centipawns, it's even worse.
 Error323
Error323 kiudee
kiudee glinscott
glinscott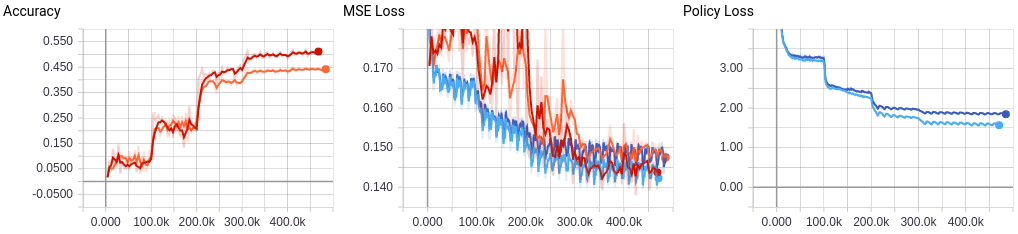

 Zeta36
Zeta36 And yes, the network basically plays "random".
And yes, the network basically plays "random". The new network (red) was forked from the orange and the loss weight on the value head set to 1. Learning rate is set to 0.001 until the 600K'th step, after which it will decay to 0.0001. We are now dropping well below the statistical mean response on the MSE.
The new network (red) was forked from the orange and the loss weight on the value head set to 1. Learning rate is set to 0.001 until the 600K'th step, after which it will decay to 0.0001. We are now dropping well below the statistical mean response on the MSE. jkiliani
jkiliani Furthermore this is using the KingBase dataset of 1.5M games, but I changed the testset to a randomly sampled 5% of the entire dataset (disjoint set of games though). Therefore the accuracy bounces around a lot at the start.
Furthermore this is using the KingBase dataset of 1.5M games, but I changed the testset to a randomly sampled 5% of the entire dataset (disjoint set of games though). Therefore the accuracy bounces around a lot at the start.
 It's very agressive as you can see. But I'm pleased :-) I think we can really start transitioning to self play.
It's very agressive as you can see. But I'm pleased :-) I think we can really start transitioning to self play. lp--
lp-- In order to see if training for so long helped, I did some quick experiments with various networks against gnuchess tc=30/1:
In order to see if training for so long helped, I did some quick experiments with various networks against gnuchess tc=30/1:
https://github.com/glinscott/leela-chess/blob/09eb87f76ce85a9a6f9ac697f3abec921e93df0a/training/tf/tfprocess.py#L366
The structure of these heads matches Leela Zero and the AlphaGo Zero paper, not the Alpha Zero paper.
The policy head convolves the last residual output (say 64 x 8 x 8) with a 1 x 1 into a 2 x 8 x 8 outputs, and then converts that with an FC layer into 1924 discrete outputs.
Given that 2 x 8 x 8 only has 128 possible elements that can fire, this seems like a catastrophic loss of information. I think it can actually only represent one from and one to square, so only the best move will be correct (and accuracy will look good, but not loss, and it can't reasonably represent MC probabilities over many moves).
In the AGZ paper they say: "We represent the policy π(a|s) by a 8 × 8 × 73 stack of planes encoding a probability distribution over 4,672 possible moves." Which is quite different.
They also say: "We also tried using a flat distribution over moves for chess and shogi; the final result was almost identical although training was slightly slower."
But note that for the above-mentioned reason it is almost certainly very suboptimal to construct the flat output from only 2 x 8 x 8 inputs. This works fine for Go because moves only have a to-square, but chess also has from-squares. 64 x 8 x 8 may be reasonable, if we forget about underpromotion (we probably can).
The value head has a similar problem: it convolves to a single 8 x 8 output, and then uses an FC layer to transform 64 outputs into...256 outputs. This does not really work either.
The value head isn't precisely described in the AZ paper, and a single 1 x 8 x 8 is probably good enough, but the 256 in the FC layer make no sense then. The problems the value layer has right now might have a lot to do with the fact that the input to the policy head is broken, so the residual stack must try to compensate this.