spider_world
自己实现的爬虫记录,现已实现的爬虫有
- scrapy 电影天堂爬虫
- scrapy 站酷爬虫
- scrapy 通用爬虫
- 抖音视频爬虫
其中,Aburame 文件夹下实现的是通用爬虫,如果是不需要登录的全站爬虫,用它实现可以说非常简单,只需要进行简单的配置即可。实现全站爬虫的逻辑主要在页面解析和分析,非常方便
有什么问题,小伙伴们欢迎在我issues提,一起进步
该爬虫模块长期有效,后续会增加更多有趣的爬虫,如果对小伙伴们有帮助的话,请给我star鼓励,先谢过了
备注:抖音的爬虫我限制了爬取的频率,每日只提供几十次调用,如果你发现爬虫爬不了了,第二天可以过来再次提取,或者你通过多几个微信,关注公众号回复抖音关键词,每个号都有固定的额度。小撸怡情你懂得
如何使用抖音爬虫
python3下运行这个项目
step 1: 拷贝项目到本地
$ git clone https://github.com/hacksman/spider_world.git
$ cd spider_world/www_douyin_com/step 2: 关注公众号【鸡仔说】回复关键字【抖音】获取你的 token 值
获得 token 值后,你需要将 www_douyin_com/config.py 文件下的 TOKEN 值替换成你的 token 值
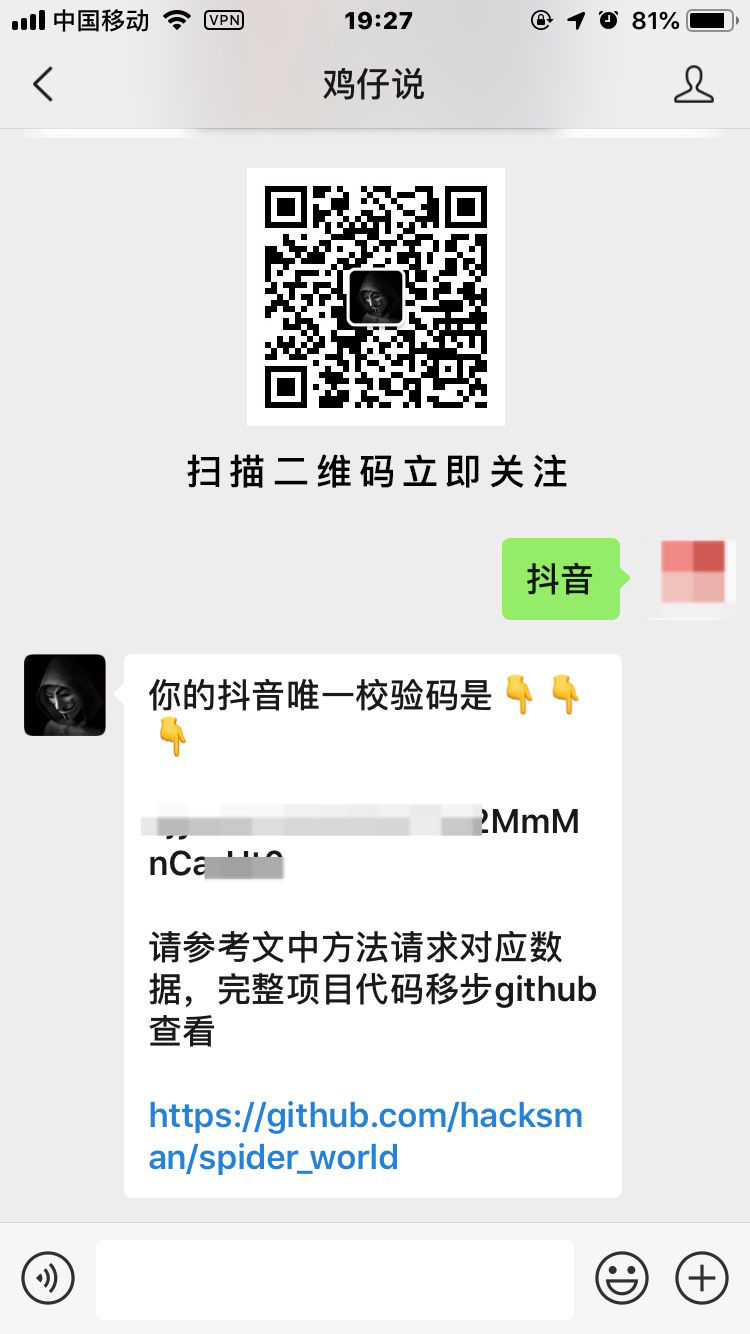
step 3:根据你的需求修改爬取参数
你可以通过以下方式获取用户id
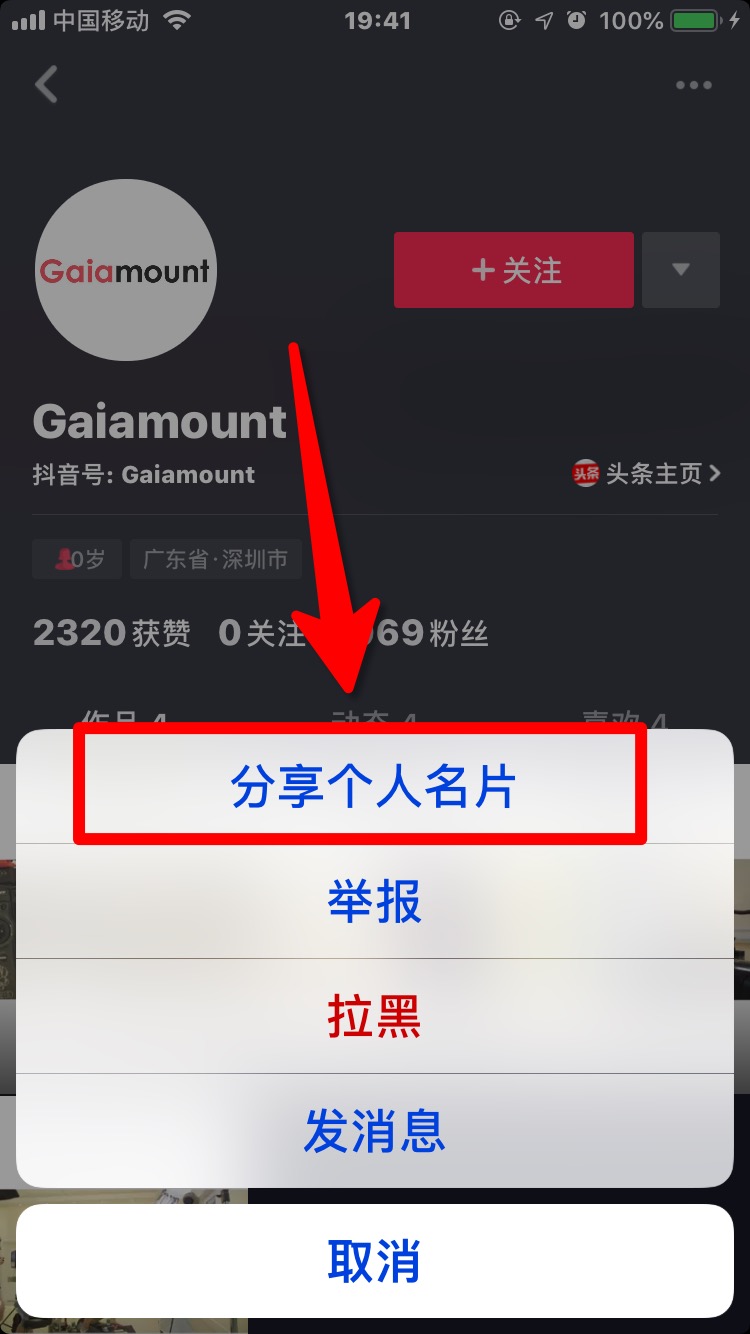

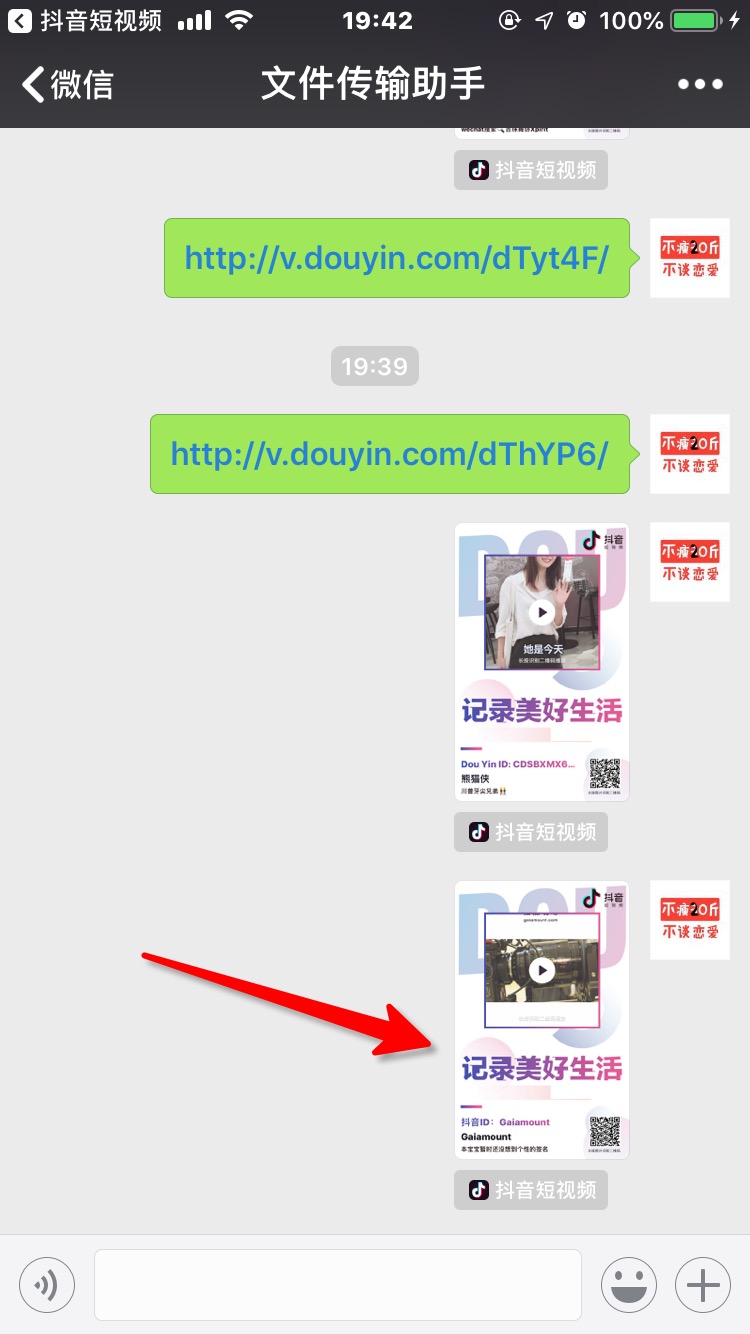

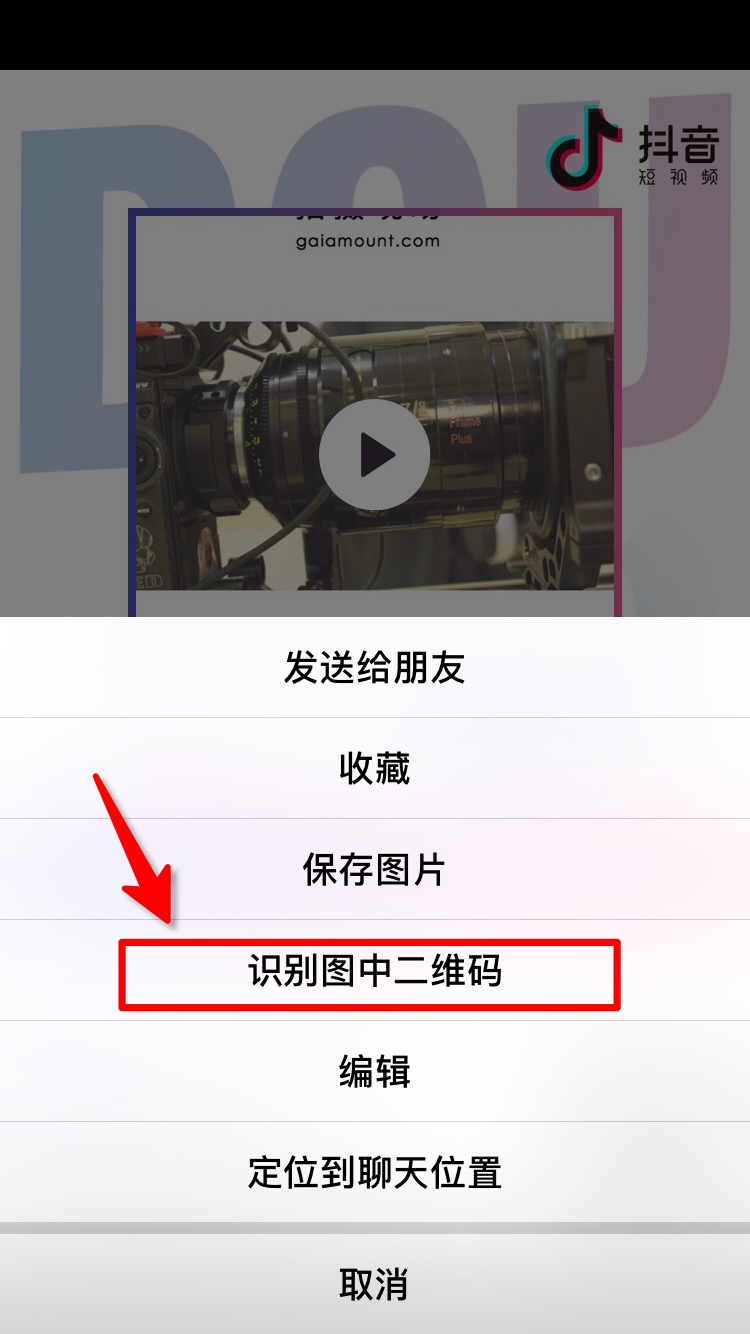

用户id就是图中最后一步链接user后的数字,比如此处url为https://www.douyin.com/share/user/93515402600,用户id就是93515402600
你可以通过以下方式获取视频id
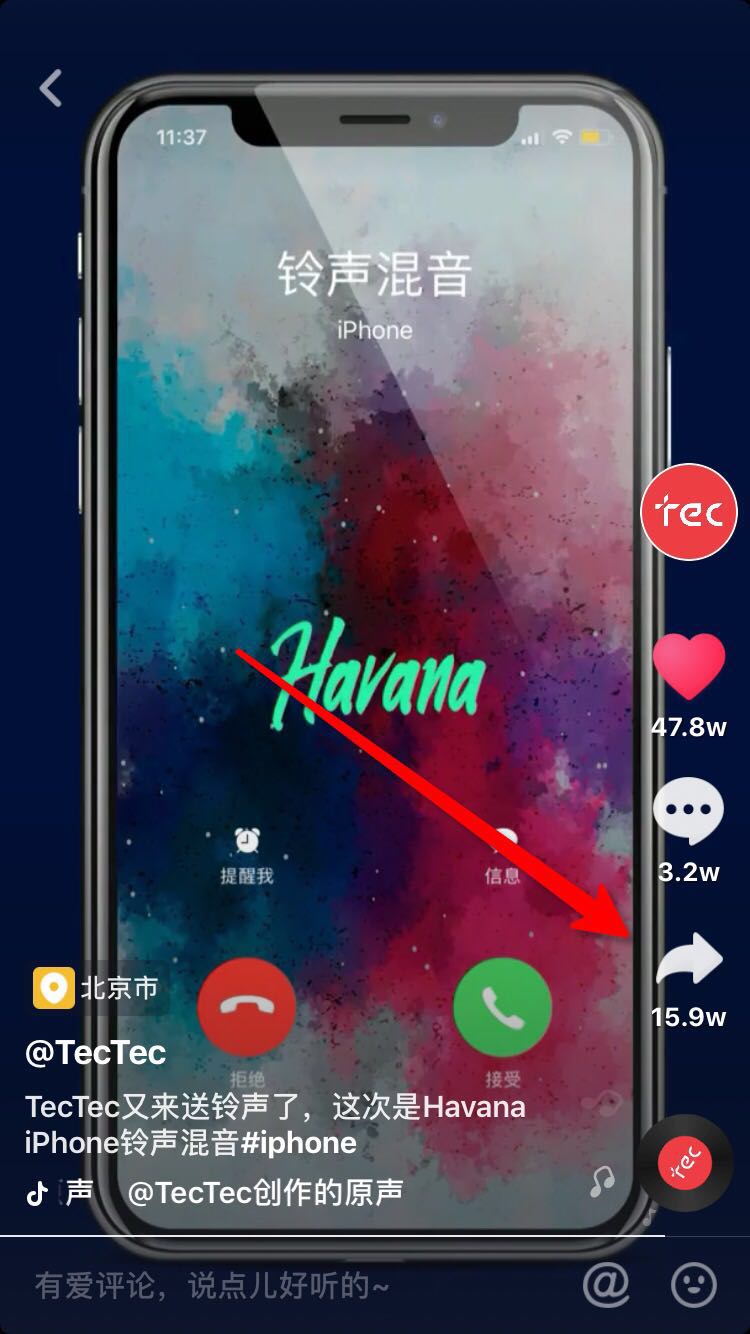
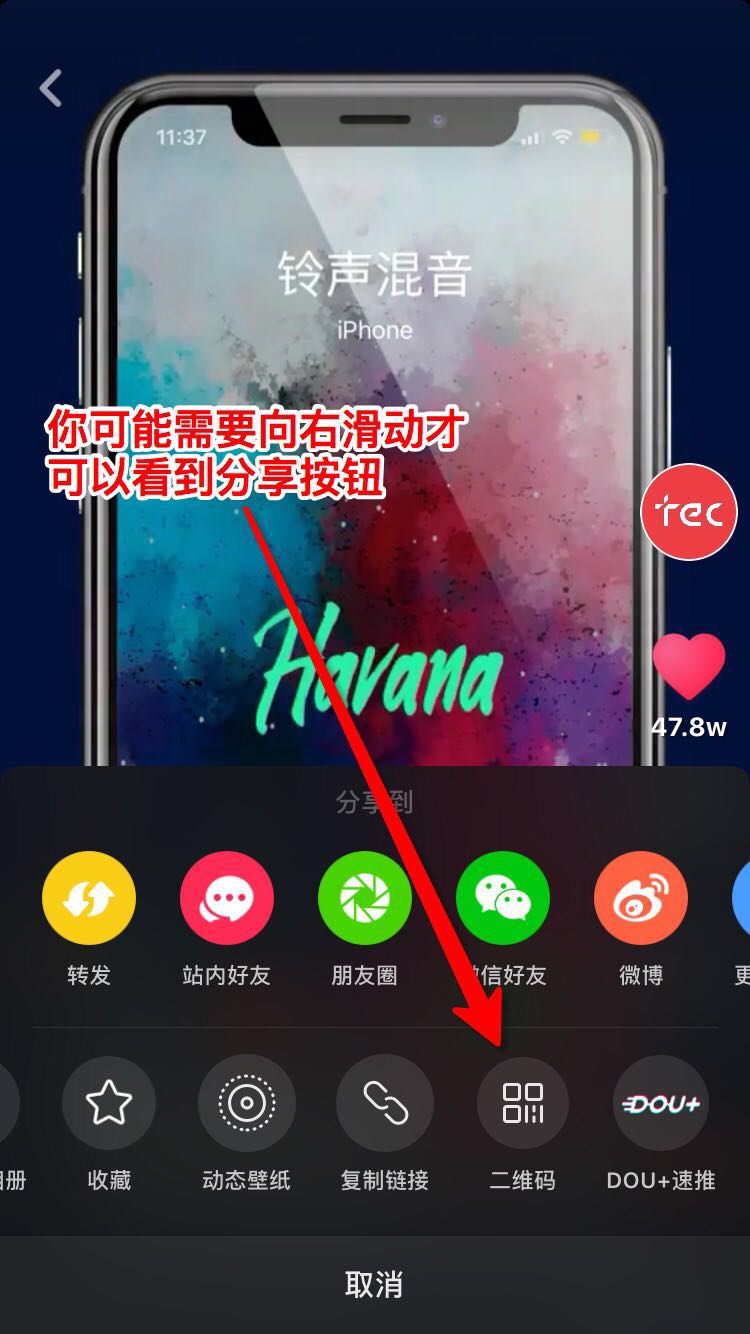
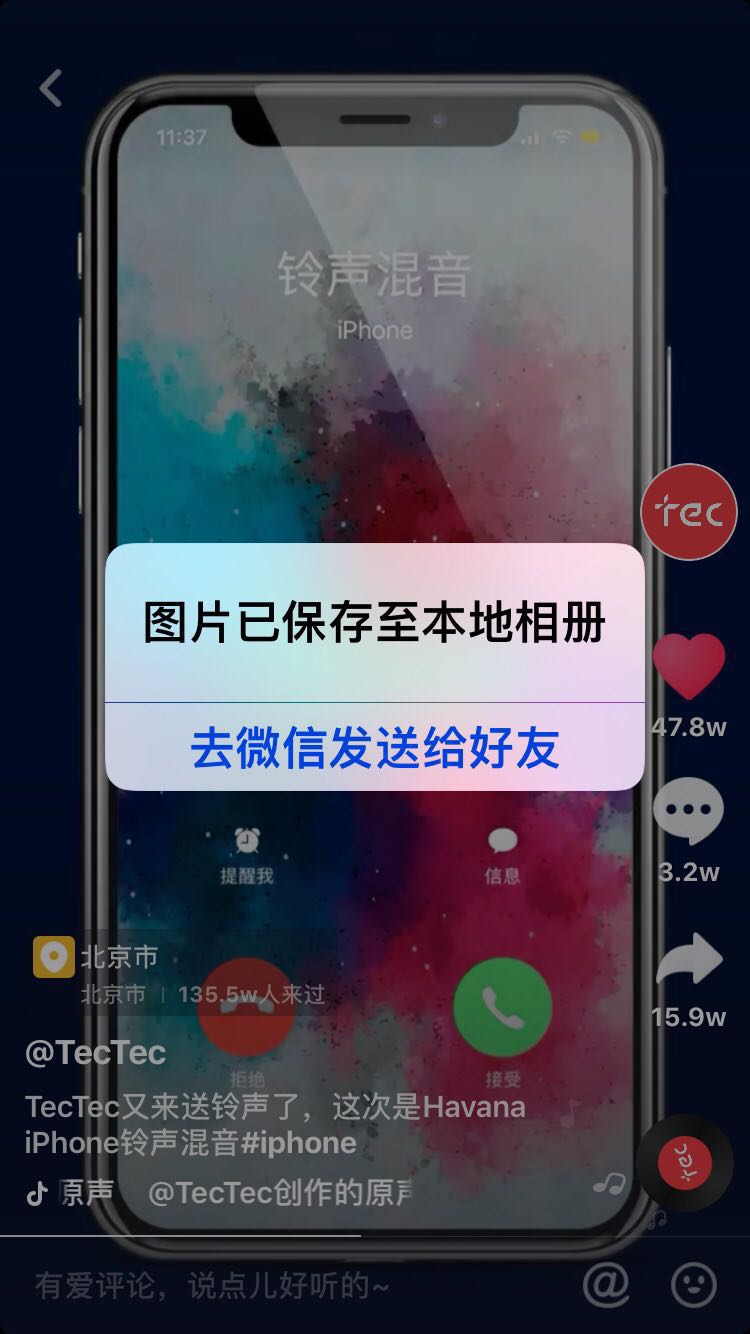
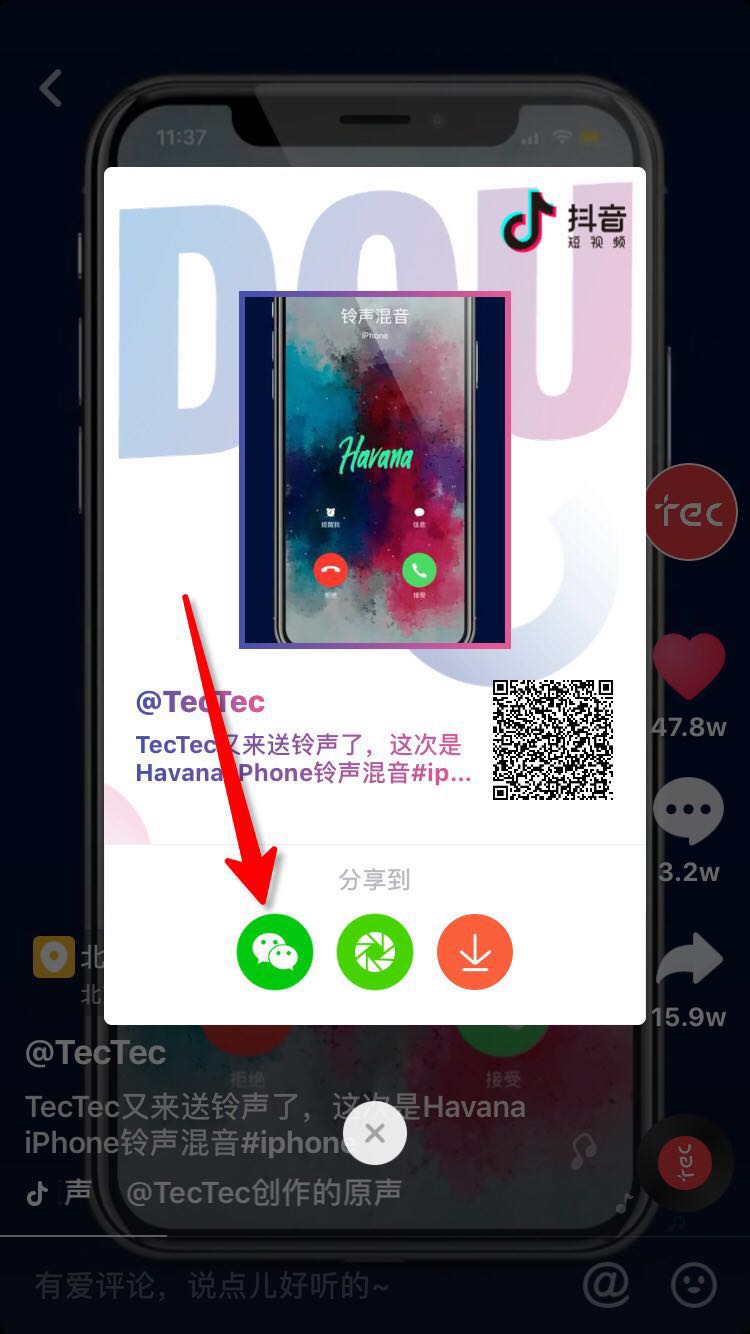


视频id就是就是图中最后一步链接video后的数字,比如此处url为
https://www.iesdouyin.com/share/video/6610679501925911815/?u_code=hjdm8k44®ion=CN&mid=6610679524466101005&schema_type=1&object_id=6610679501925911815&utm_campaign=client_scan_share&app=aweme&utm_medium=ios&tt_from=scan_share&iid=45561030398&utm_source=scan_share
视频id就是6610679501925911815
step 4:运行爬虫
你有两种方式运行这个项目:
①. 找到 spiders/douyin_crawl.py 文件,修改对应参数运行,然后直接运行即可(推荐)
$ cd ./spider_world/www_douyin_com/spiders
$ python douyin_crawl.py②. 找到 examples/fetch_video_test.py 文件,修改对应的 user_id,然后直接运行项目即可
正常运行命令, 将会得到类似如下的log日志
2019-05-07 20:06:15,310 - douyin_crawl.py[line:107] INFO - 当前正在爬取 user id 为 58958068057 的第 👉 1 👈 页内容...
2019-05-07 20:06:17,074 - douyin_crawl.py[line:231] INFO - download_favorite_video 正在下载视频 冯提莫_58958068057_终于等到冯提莫首场个人演唱会,就要实现啦~我们一起期待吧!
2019-05-07 20:06:22,617 - douyin_crawl.py[line:231] INFO - download_favorite_video 正在下载视频 冯提莫_58958068057_周一啦!的视频送给你们!@抖音小助手
2019-05-07 20:06:28,241 - douyin_crawl.py[line:231] INFO - download_favorite_video 正在下载视频 冯提莫_58958068057_写了一封抖音小助手
2019-05-07 20:06:36,235 - douyin_crawl.py[line:231] INFO - download_favorite_video 正在下载视频 冯提莫_58958068057_一首好听给你听~还想听什么评论告诉我哦~
2019-05-07 20:06:41,796 - douyin_crawl.py[line:231] INFO - download_favorite_video 正在下载视频 冯提莫_58958068057_准备进军留我的嘛?人称地表最强一米五🤨@抖音小助手
2019-05-07 20:06:47,170 - douyin_crawl.py[line:231] INFO - download_favorite_video 正在下载视频 冯提莫_58958068057_突然想通音小助手
2019-05-07 20:06:52,657 - douyin_crawl.py[line:231] INFO - download_favorite_video 正在下载视频 冯提莫_58958068057_很多人说是想起了自己的故事吧~Afterlove《看到风》MV即将上线~ 在 /www_douyin_com/videos/ 下你将会看到一个以作者昵称命名的文件夹,里面就是对应的你需要下载的视频啦。
备注
为了避免滥用接口,鸡仔对接口的请求次数做了限制,如果你在使用的过程中,遇到了诸如一下的提示,说明你今日的次数调用得有点多啦,你可以拿更多的微信关注公众号获取次数,或者明日再来请求吧
您当日的 api 次数已经使用完毕, 请明日再来爬取吧...
-------此处省略了部分错误日志-------
requests.exceptions.MissingSchema: Invalid URL 'None': No schema supplied. Perhaps you meant http://None?
TODO LIST
-
[X] 下载该用户所有视频
-
[X] 下载该用户所有视频和音频
-
[X] 下载单个视频
-
[ ] 下载单个视频的音频
-
[X] 用户的评论信息