PEPP - PYLON Exporter++
V2.3.0 Changelog
PEPP is a utility for exporting data from DataSift's PYLON product in either JSON or CSV format, optionally saving the data to local file. PEPP also supports the ability to automatically generate Tableau workbooks and comes equipped with a number of use case driven examples out of the box.
It is the goal of this utility to support any type of analysis requests using a config (not code) approach.
Features:
- Simplified JSON config "recipe" approach
- Export as JSON or CSV
- Support for
analyzeandtaskapi resources - Multi-index query
- Result set merging
- Result set to query inheritance
- Request queue with concurrency limit
- Retry logic to handle API errors
- Automated Tableau workbook generation
DISCLAIMER: This library is in no way associated with or supported by DataSift and hence any questions or issues issues should be logged here.
Table of Contents
- Installation
- Sync New Changes
- Quick Start
- User Guide
- Config File Structure
- Single Task
- Native Nested Tasks
- Custom Nested
- Mixing Nested Task Types
- Merged Tasks
- Analysis Tags
- Config File Selection
- Config File Directory
- Config Options
- api_resource Property
- Filter Property
- Start/End Properties
- Index Credentials
- Demographic Baselines
- Baseline Calculations
- Tableau Workbook Generation
- Custom Tableau Workbooks
- Development
- Example Config Recipes
Installation
If Node.js is not installed, install it from https://nodejs.org/. Once complete, check by running node -v from a
terminal window to show the install version.
Make sure you have Git installed. This will allow easy syncing to update the source code. Download and install Git from https://git-scm.com/.
Clone the repo:
git clone https://github.com/haganbt/pepp.git
cd pepp
Install node module dependencies:
sudo npm install
Sync New Changes
PEPP code changes reguarly with new features and bug fixes. To sync with the most recent changes, from your local PEPP directory:
git pull origin master
Check for any NPM module changes:
sudo npm prune
sudo npm install
Quick Start
- Edit
config/demo.jsand add values for the PYLON recording id along with authentication credentials. - Run PEPP with the command
node app.js
User Guide
PEPP uses a configuration file to define request tasks. Files can be configured as JSON, YAML, hjson, JSON5, CoffeeScript etc (see /config for examples of JSON and YAML). Each task defines a request to the PYLON /analyze resource. With this is mind, usage requires 3 steps:
- Define request tasks within a config file
- Tell PEPP which config file to use
- Run tasks
Config File Structure
The config file contains an analysis object consisting of two arrays: freqDist and timeSeries. Tasks (i.e. an analysis request to PYLON) are simply defined by specifying
an object { ... } within the desired request type array. The below example defines a single task for both a freqDist and timeSeries. Note depending upn which request type is being run, PYLON
mandates specific key:values be present:
"analysis": {
"freqDist": [
{
target: "fb.author.gender"
}
],
"timeSeries": [
{
interval: "day"
}
]
}
]Single Task
As noted above, to make a single request, define a single task object inside the required type array (freqDist or timeSeries):
"freqDist": [
{
"target": "fb.author.gender"
}
]Native Nested Tasks
PYLON supports nesting of low cardinality targets up tot 3 levels deep. PEPP supports these using the child key:
{
"name": "example_native_nested",
"target": "fb.author.gender",
"threshold": 2,
"child": {
"target": "fb.author.age",
"threshold": 2,
"child": {
"target": "fb.media_type",
"threshold": 2
}
}
} Custom Nested
Custom nested tasks offer increased flexibility over native nested tasks by adding support for all targets (native nested tasks are currently restricted to low cardinality targets only).
The workflow for custom nested tasks is simple in that each result key from a primary task is used to generates subsequent secondary tasks by using the key as a filter parameter.
Custom nested tasks are configured within the config file using the then object:
"freqDist": [
{
"target": "fb.topics.name",
"threshold": 2,
"then": { // <-- then object defines custom nested
"target": "fb.author.gender",
"threshold": 2
}
}
]Mixing Nested Task Types
It is possible to specify a custom nested task containing a native nested task. For example:
{
"target": "fb.parent.topics.name",
"threshold": 25,
"then": { // <-- custom nested
"target":"fb.parent.author.region",
"threshold": 20,
"child": { // <-- native nested
"target": "fb.parent.author.gender",
"threshold": 2,
"child": {
"target": "fb.parent.author.region",
"threshold": 50
}
}
}
}As with any custom nested query, this will dynamically generate a filter property and next query (the 3 level native nested) from the result keys returned from the first task.
NOTE: Native nested followed by custom nested is not currently supported.
Merged Tasks
Multiple tasks can be merged together to deliver a single combined result set. Simply wrap the tasks in an array object. Note the task name is set using the array key:
"freqDist": [
{
"merged__example": [ // <-- Task name
{
task 1...
},
{
task 2...
}
]
}
]Analysis Tags
Analysis Tags provide freedom to define custom filters as part of analysis tasks. Each Analysis Tag can be defined and then referenced and reused throughout a config recipe.
This technique is especially useful for data sets where VEDO is unavailable, or required tags have been omitted or were unknown at the time of recording.
Analysis tags are simply config defined filters that can then be used within a task definition in place of a target and threshold.
Analysis Tags are defined at the config parent level using an analysisTags key and then referenced from within each task using the analysis_tag key.
Consider the below example where custom filters have been defined for characters and US areas. These are defined within the analysisTags key. Each of the Analysis Tags are then referenced as part of a freqDist task:
"analysisTags": {
"character": [ //<-- name to identify analysis_tag family
{
"key": "yogi",
"filter": "fb.all.content contains_any \"yogi\""
},
{
"key": "booboo",
"filter": "fb.all.content contains_any \"booboo\""
}
],
"us_areas": [ //<-- second analysis_tag family
{
"key": "New England",
"filter": "fb.author.country in \"United States\" and fb.author.region in \"Maine, Vermont, New Hampshire, Massachusetts, Rhode Island, Connecticut\""
},
{
"key": "Pacific",
"filter": "fb.author.country in \"United States\" and fb.author.region in \"Alaska, California, Hawaii, Oregon, Washington\""
}
]
},
"analysis": {
"freqDist": [
{
"name": "example-fd-task_tag",
"analysis_tag": "character", //<-- reference analysis_tag family
"then": {
"analysis_tag": "us_areas", //<-- reference analysis_tag family
"then": {
"target": "fb.topics.name",
"threshold":2
}
}
}
]
}Example output:
key1,key2,key3,interactions,unique_authors
yogi,New England,Birthday,100,100
yogi,Pacific,Birthday,300,300
booboo,New England,Birthday,600,600
booboo,Pacific,Birthday,1600,1600Analysis Tags can be used anywhere a regular target would be used, with the exceptions of at any level of a Native Nested task, or the bottom-most level in any other task.
Config File Selection
Config File Selection by Environment Variable
To specify which config file to use, set the NODE_ENV environment variable:
On a Mac:
export NODE_ENV=myConfigFile
On a Windows machine:
set NODE_ENV=myConfigFile
NOTE: only specify the config file name. Omit the filetype extension, i.e. .json
If NODE_ENV is not specified, the demo config file will be used i.e.load the /config/demo.js
config file.
Config File Selection by Commandline Argument
Alternatively, the filename may be specified by the first commandline argument to the app:
node app.js myConfigFileConfig File Directory
The directory from which config files are loaded can be set by defining the NODE_CONFIG_DIR environment variable. This can be a full path from your root directory, or a relative path from the process if the value begins with ./ or ../.
Config Options
Below is a summary of all supported config options.
| Option | Scope | Description |
|---|---|---|
app.max_parallel_tasks |
global | The number of tasks to run in parallel. |
app.log_level | global | Output log level. debug shows full requests and responses. info, warn, debug, trace |
||
app.date_format | global | Format used for all data outputs. Defaults to YYYY-MM-DD HH:mm:ss. See http://momentjs.com/docs/#/displaying/format/ |
||
app.api_resource | global | Sets the default resource for all tasks. analyze, task |
||
app.analyze_uri |
app index | The full URI of the /analyze resource endpoint. No trailing forward slash. |
app.task_uri |
app index | The full URI of the /task resource endpoint. No trailing forward slash. |
analysis_tag |
task | OPTIONAL. Specify which analysisTags to use in nested query |
analysisTags |
global | OPTIONAL. Define any analysis tags to be used in tasks |
end |
global task | OPTIONAL. unix timestamp. Defaults to now UTC |
filter |
global, task | OPTIONAL. PYLON analyze filter parameter containing CSDL |
index.default.auth.api_key |
index | The api key used for authentication |
index.default.auth.username |
index | The username used for authentication |
index.default.subscription_id |
index | The recording subscription id of the index |
index.default.api_resource | index | Set the api respurce for all tasks using this index. analyze, task |
||
id |
merged task | A unique identifier for each merged task result set. Used to distinguish between results on output. |
only | task | Only execute the specific task(s) with this flag set. Must evaluate to boolean truthy: true, "true", 1, "yes" |
||
skip | task | Do not execute the specific task(s) with this flag set. Must evaluate to boolean truthy: true, "true", 1, "yes" |
||
group |
task | Assign task to the execution group specified. Groups can be selected at runtime via commandline argument or PEPP_GROUP |
start |
global task | OPTIONAL. start time - unix timestamp. Defaults to now -30 days UTC |
target |
freqDist task | PYLON analyze target parameter |
threshold |
freqDist task | OPTIONAL. PYLON parameter to identify the threshold. Defaults to 200 of omitted |
then |
freqDist task | Specify custom nested task properties |
then.analysis_type | task | OPTIONAL. Override custom nested task types. freqDist, timeSeries |
api_resource Property
The api_resource property identifies if either the analyze or task api resource will be used for tasks. This property can be set in three different ways depending upon the required behavior.
app.api_resource- Sets the default api resource for all tasks.index.<my_index>.api_resource- Set the default api resource for all tasks using the specific index.api_resource- Set the default api resource for a specific task. Custom nested tasks will inherit this value if set.
NOTE: If more than one of the above is set, the override order is as per the above order i.e. app is overriden by index which is overridden by individual tasks.
Filter Property
A filter parameter can be set in 3 places within PEPP:
- global - apply a filter to all tasks within the config file
- task - apply a filter to a specific task
- custom nested child - apply a filter to a custom nested child task
If any of the above options are set in conjunction with each other, each will simply augment the next joining with an AND. Examples of each type are below.
Global Filter
Specifying a global filter parameter will apply the filter to all tasks within the config file (including custom nested child tasks - see below). Example:
{
"filter": "interaction.tag_tree.property ==\"Yogi\"",
"analysis": {
"freqDist": [
.....
}
Task Filter
A task level filter can be set as expected:
{
"filter": "interaction.tag_tree.property ==\"Yogi\"",
"threshold": 2,
"target": "fb.author.gender"
}
Custom Nested
In cases where a filter is set within a custom nested task, all child tasks automatically inherit the parent filter property from the parent task. Consider the following config:
"freqDist": [
{
"filter": "fb.all.content any \"Yogi\"",
"target": "fb.author.gender",
"threshold": 2,
"then": {
"target": "fb.topics.name",
"threshold": 3,
}
}
}
Both the gender and the subsequent topics tasks will all have the "Yogi" filter appended.
Custom Nested Child Filter
It is also possible to specify a filter as part of a custom child task as follows:
"freqDist": [
{
"filter": "fb.all.content any \"Yogi\"",
"target": "fb.author.gender",
"threshold": 2,
"then": {
"filter": "fb.all.content any \"Booboo\"", //<-- child filter
"target": "fb.topics.name",
"threshold": 3,
}
}
}
Once again, the filter parameters are simply augmented together. In the above example the gender task with have the "Yogi" filter applied and all child tasks with have both the "Yogi" and "Booboo" filters applied together e.g:
"filter":"(fb.author.gender == \"female\") AND (fb.all.content any \"Yogi\") AND (fb.all.content any \"Booboo\")""NOTE: Setting the log_level to debug`` will show the requests being generated, including thefilter```.
Start/End Properties
Optional start and end unix timestamp properties can be set globally (apply to all tasks) or at a specific task level to specify the time range for analysis queries. If both are set, the task will override the global setting.
In addition, if you are using a JavaScript config file (rather than JSON or YAML), you can use any JavaScript date library for simper configuration. For example, using moment.js:
"use strict";
const moment = require('moment');
module.exports = {
start: moment.utc().subtract(7, 'days').unix(),
...Execution Groups
When the group property is assigned on a task, it defines all tasks labeled with the same group value as a set. These groups can be useful when your recipe file has multiple logical groups of tasks that are often run together. For example, all tasks associated with brand monitoring vs. those for content monitoring, or when running all tasks in your recipe would exceed your hourly analyze limit.
At runtime, the group to be executed may be specified on the commandline:
node app.js myrecipe mygroupor via the PEPP_GROUP environment variable:
export PEPP_GROUP=mygroupThe skip and only properties may also be used in conjunction with the execution group functionality. In the context of a single group, if a task is designated as only, other tasks in the group without this flag will not be executed. When skip is used, the identified task will not be executed in the context of the group. NOTE: When no group is specified, the group context does not apply, and any task with only specified will be executed from the recipe.
Index Credentials
One or more PYLON idexes must be defined by setting a parent index key. Credentials defined under the default
key will be used unless overridden by setting an index parameter. The default analyze URI can also be overwritten
to support a proxy:
module.exports = {
"index": {
"default": {
"subscription_id": "<RECORDING_ID>",
"auth": {
"username": "<USERNNAME>",
"api_key": "<API_KEY>"
}
},
"foo": {
"analyze_uri": "https://pylonsandbox.datasift.com/v1/pylon/analyze", //<-- override analyze URI
"subscription_id": "<RECORDING_ID>",
"auth": {
"username": "<USERNNAME>",
"api_key": "<API_KEY>"
}
}
},
"analysis": {
"freqDist": [
{
"index": "foo", //<-- override default creds
"target": "fb.author.age",
"threshold": 2
},
{
"target": "fb.author.age",
"threshold": 2
}
]
}
};Custom Nested Tasks
If an index key is set as part of a parent custom nested task, the child task will inherit these values.
{
"index": "foo",
"target": "fb.author.gender",
"threshold": 2,
"then": {
"target": "fb.type", //<-- inherits "foo" creds
"threshold": 2
}
}Demographic Baselines
PEPP supports baseline and microtargeting use cases by automatically calculating 1 or more probability comparators against a baseline data set.
NOTE: Currently, PEPP only supports age and gender targets for baseline comparisons. A baseline task can be created as follows:
1) Name the merged tasks
The merged task name must include the string "baseline" to trigger the baseline calculation workflow:
"freqDist": [
{
"merged_baseline_example": [ // <-- name must include "baseline"
{
task 1...
},
{
task 2...
}
]
}
] 2) Create age/gender tasks
Tasks can be age gender (or gender age, no difference) however all tasks must be identical i.e. if one task uses age and gender others should not use gender and age:
"freqDist": [
{
"merged_baseline_example": [
{
"target": "fb.parent.author.age",
"threshold": 6,
"child": {
"target": "fb.parent.author.gender",
"threshold": 2
}
},
{
"target": "fb.parent.author.age",
"threshold": 6,
"child": {
"target": "fb.parent.author.gender",
"threshold": 2
}
},
]
}
]3) Add an id for each task
Each task must have a unique id key and value. The baseline tasks must have an id that contains the string "baseline" to declare which result set to compare to.
Comparator tasks can have any id. If the id is omitted, one will be generated:
"freqDist": [
{
"merged_baseline_example": [
{
"id": "yogi", // <-- unique id
"target": "fb.parent.author.age",
"threshold": 6,
"child": {
"target": "fb.parent.author.gender",
"threshold": 2
}
},
{
"id": "baseline", // <-- unique id
"target": "fb.parent.author.age",
"threshold": 6,
"child": {
"target": "fb.parent.author.gender",
"threshold": 2
}
},
]
}
]4) Define what you wish to baseline
Using either a filter and/or a different index, define the tasks accordingly to compare data sets.
The below example uses a micro targeting approach to compare two products (defined using VEDO tags) within the default index, to the baseline index (note the different index parameter used to specify a different set of index credentials).
"freqDist": [
{
"merged_baseline_example": [
{
"id": "yogi",
"filter": "interaction.tag_tree.brand == \"yogi\"", // <-- Yogi filter
"target": "fb.parent.author.age",
"threshold": 6,
"child": {
"target": "fb.parent.author.gender",
"threshold": 2
}
},
{
"id": "booboo",
"filter": "interaction.tag_tree.brand == \"booboo\"", // <-- Booboo filter
"target": "fb.parent.author.age",
"threshold": 6,
"child": {
"target": "fb.parent.author.gender",
"threshold": 2
}
},
{
"id": "baseline",
"index": "global" // <-- specify another index to query
"target": "fb.parent.author.age",
"threshold": 6,
"child": {
"target": "fb.parent.author.gender",
"threshold": 2
}
},
]
}
]Baseline Calculations
When a baseline task is run, by default a CSV result set is generated with the following format:
| id | category | key | total_unique_authors | unique_author | probability | index | expected_baseline |
|---|---|---|---|---|---|---|---|
| baseline | 25-34 | female | 916900 | 178200 | 0.194350529 | 1 | 178200 |
| baseline | 25-34 | male | 916900 | 81400 | 0.088777402 | 1 | 81400 |
| yogi | 25-34 | male | 1197600 | 237600 | 0.198396794 | 2.234766831 | 106319.8168 |
| yogi | 25-34 | female | 1197600 | 159900 | 0.133517034 | 0.686990845 | 232754.1935 |
| booboo | 25-34 | male | 1971700 | 453300 | 0.229903129 | 2.589658222 | 175042.4038 |
| booboo | 25-34 | female | 1971700 | 460900 | 0.233757671 | 1.202763236 | 383200.9379 |
- total_unique_authors: the total number of unique authors for the id
- unique_author: the unique author count for the specific ide, category and key combination
- probability: unique_author / total_unique_authors
- index: comparator probability / baseline probability
- expected baseline: total_unique_authors * baseline probability
With these results, it become simple to plot meaningful visualizations.
Bar Chart
Plotting unique_author (foreground) against expected_baseline (background):
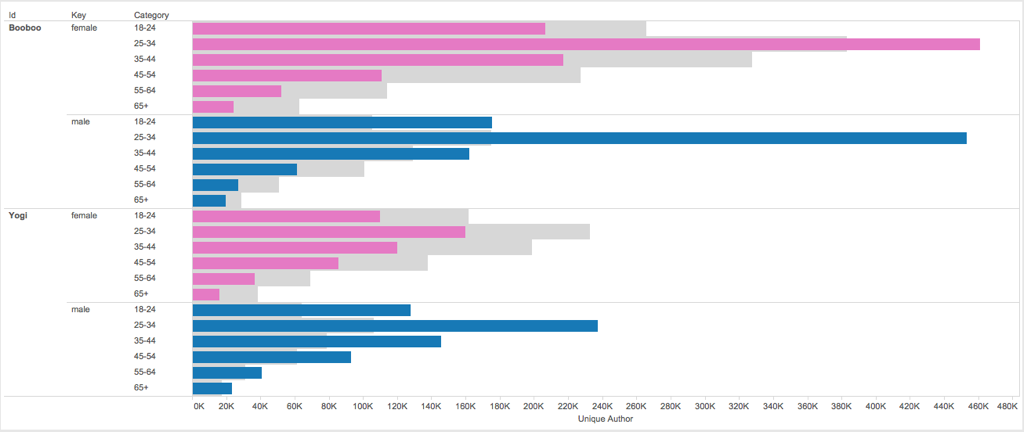
Bubble Chart
Plotting the index with a reference line of 1:
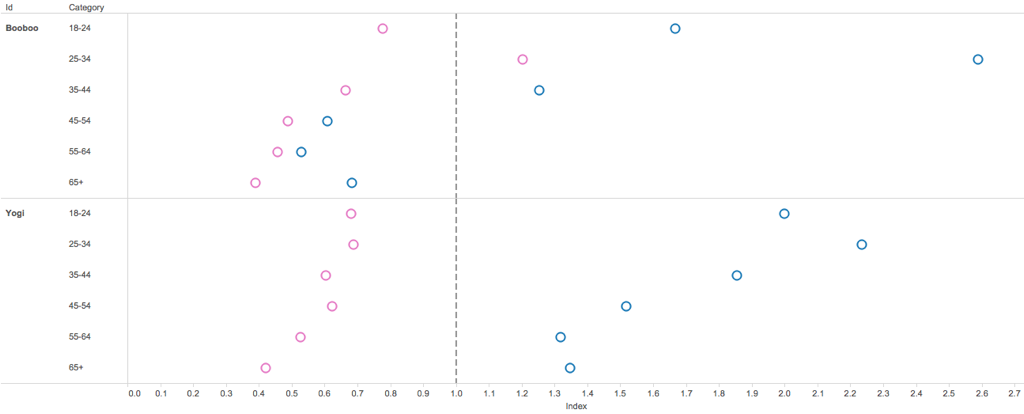
Tableau Workbook Generation
PEPP supports the automated generation of Tableau workbooks. It does this by simply exporting CSV data that a pre-built workbook utilizes for visualizations.
Each workbook is designed based on a specific use case as detailed below. Simply open the required config file and follow any instructions within the header.
| Use Case | Config File Name | Explore By | Description |
|---|---|---|---|
| Brand Analytics - Brand Reputation Management | BA_brand_reputation_management.js |
Tags | Full Details |
| Content & Media Analytics - - Content Discovery | CMA_content_discovery.js |
Tags | Full Details |
| Content & Media Analytics - - Topic Analysis | CMA_topic_analysis.js |
Index | Full Details |
Custom Tableau Workbooks
PEPP will automatically check the /tableau-templates directory for a Tableau workbook (.twb) file with an identical name to that of the config file being executed. If a corresponding workbook is found, it will be copied to the output directory along with the other output files rewriting the directory paths within the workbook accordingly. You can specify to use a template with a different name by using the app.template property in your config file. (Do not include the .twb extension in this property.)
With this in mind, it then becomes easy to create new custom Tableau workbooks simply by developing a config recipe an associated workbook, and copying the .tbx file back in to the /tableau-templates directory. This is especially useful for refreshing data sets.
Development
npm run develop
Tests
npm testor
npm run test:watchLint
npm run lintDev ENV Config
source config/developer.shContributing
Pull requests welcome - with associated tests ;)
Logging
- "warn" : A note on something that should probably be looked at by an operator eventually.
- "info" : Detail on regular operation.
- "debug" : Anything else, i.e. too verbose to be included in "info" level.
- "trace" : Very detailed application logging.
Example Config Recipes
Multi-Index - Merged 3 Level Custom Nested
Top topics by age and gender from two different indexes:
"analysis": {
"freqDist": [
{
"merged_custom_nested": [
{
"index": "foo",
"id":"booboo",
"target": "fb.parent.author.age",
"threshold": 2,
"then": {
"target": "fb.parent.author.gender",
"threshold": 2,
"then": {
"target": "fb.parent.topics.name",
"threshold": 2
}
}
},
{
"id": "yogi",
"target": "fb.parent.author.age",
"threshold": 2,
"then": {
"target": "fb.parent.author.gender",
"threshold": 2,
"then": {
"target": "fb.parent.topics.name",
"threshold": 2
}
}
}
]
}
]
} Multi-Index - Merged 2 Level Custom Nested with type override
Top topics by gender by week from two different indexes:
"timeSeries": [
{
"merged_custom_nested": [
{
"id": "yogi",
"index": "other",
"interval": "week",
"then": {
"analysis_type": "freqDist",
"target": "fb.author.gender",
"threshold": 2,
"then": {
"target": "fb.topics.name",
"threshold": 2
}
}
},
{
"id": "booboo",
"interval": "week",
"then": {
"analysis_type": "freqDist",
"target": "fb.author.gender",
"threshold": 2,
"then": {
"target": "fb.topics.name",
"threshold": 2
}
}
}
]
}
]Hourly url volumes by tag:
"freqDist": [
{
"name": "tag_url_by_hour",
"target": "interaction.tag_tree.property",
"threshold": 20,
"then": {
"target": "links.url",
"threshold": 10,
"then": {
"analysis_type": "timeSeries",
"interval": "hour"
}
}
},
]