Awesome-Efficient-LLM
A curated list for Efficient Large Language Models
Full List
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
- Leaderboard
Please check out all the papers by selecting the sub-area you're interested in. On this main page, only papers released in the past 90 days are shown.
🚀 Updates
- May 29, 2024: We've had this awesome list for a year now :smiling_face_with_three_hearts:!
- Sep 6, 2023: Add a new subdirectory project/ to organize efficient LLM projects.
- July 11, 2023: A new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs.
💮 Contributing
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.
:star: Recommended Paper
For each topic, we have curated a list of recommended papers that have garnered a lot of GitHub stars or citations.
Paper from July 13, 2024 - Now (see Full List from May 22, 2023 here)
Quick Link
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
Network Pruning / Sparsity
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 [ [:star: SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot Elias Frantar, Dan Alistarh |
 |
Github paper | [//]: #Recommend |
 [ [:star: LLM-Pruner: On the Structural Pruning of Large Language Models Xinyin Ma, Gongfan Fang, Xinchao Wang |
 |
Github paper | [//]: #Recommend |
 [ [:star: A Simple and Effective Pruning Approach for Large Language Models Mingjie Sun, Zhuang Liu, Anna Bair, J. Zico Kolter |
 |
Github Paper |
[//]: #Recommend |
 [ [:star: Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen |
 |
Github Paper |
[//]: #Recommend |
| Beyond 2:4: exploring V:N:M sparsity for efficient transformer inference on GPUs Kang Zhao, Tao Yuan, Han Bao, Zhenfeng Su, Chang Gao, Zhaofeng Sun, Zichen Liang, Liping Jing, Jianfei Chen |
 |
Paper | [//]: #10/30 |
 EvoPress: Towards Optimal Dynamic Model Compression via Evolutionary Search Oliver Sieberling, Denis Kuznedelev, Eldar Kurtic, Dan Alistarh |
 |
Github Paper |
[//]: #10/30 |
| FedSpaLLM: Federated Pruning of Large Language Models Guangji Bai, Yijiang Li, Zilinghan Li, Liang Zhao, Kibaek Kim |
 |
Paper | [//]: #10/30 |
 Pruning Foundation Models for High Accuracy without Retraining Pu Zhao, Fei Sun, Xuan Shen, Pinrui Yu, Zhenglun Kong, Yanzhi Wang, Xue Lin |
Github Paper |
[//]: #10/30 | |
| Self-calibration for Language Model Quantization and Pruning Miles Williams, George Chrysostomou, Nikolaos Aletras |
 |
Paper | [//]: #10/29 |
| Beware of Calibration Data for Pruning Large Language Models Yixin Ji, Yang Xiang, Juntao Li, Qingrong Xia, Ping Li, Xinyu Duan, Zhefeng Wang, Min Zhang |
Paper | [//]: #10/29 | |
 [ [AlphaPruning: Using Heavy-Tailed Self Regularization Theory for Improved Layer-wise Pruning of Large Language Models Haiquan Lu, Yefan Zhou, Shiwei Liu, Zhangyang Wang, Michael W. Mahoney, Yaoqing Yang |
 |
Github Paper |
[//]: #10/21 |
| Beyond Linear Approximations: A Novel Pruning Approach for Attention Matrix Yingyu Liang, Jiangxuan Long, Zhenmei Shi, Zhao Song, Yufa Zhou |
 |
Paper | [//]: #10/21 |
| [ DISP-LLM: Dimension-Independent Structural Pruning for Large Language Models Shangqian Gao, Chi-Heng Lin, Ting Hua, Tang Zheng, Yilin Shen, Hongxia Jin, Yen-Chang Hsu |
 |
Paper | [//]: #10/21 |
| [ Self-Data Distillation for Recovering Quality in Pruned Large Language Models Vithursan Thangarasa, Ganesh Venkatesh, Nish Sinnadurai, Sean Lie |
 |
Paper | [//]: #10/21 |
| LLM-Rank: A Graph Theoretical Approach to Pruning Large Language Models David Hoffmann, Kailash Budhathoki, Matthaeus Kleindessner |
 |
Paper | [//]: #10/21 |
 [ [Is C4 Dataset Optimal for Pruning? An Investigation of Calibration Data for LLM Pruning Abhinav Bandari, Lu Yin, Cheng-Yu Hsieh, Ajay Kumar Jaiswal, Tianlong Chen, Li Shen, Ranjay Krishna, Shiwei Liu |
 |
Github Paper |
[//]: #10/13 |
| Mitigating Copy Bias in In-Context Learning through Neuron Pruning Ameen Ali, Lior Wolf, Ivan Titov |
 |
Paper | [//]: #10/04 |
 [ [MaskLLM: Learnable Semi-Structured Sparsity for Large Language Models Gongfan Fang, Hongxu Yin, Saurav Muralidharan, Greg Heinrich, Jeff Pool, Jan Kautz, Pavlo Molchanov, Xinchao Wang |
 |
Github Paper |
[//]: #09/27 |
| [ Search for Efficient Large Language Models Xuan Shen, Pu Zhao, Yifan Gong, Zhenglun Kong, Zheng Zhan, Yushu Wu, Ming Lin, Chao Wu, Xue Lin, Yanzhi Wang |
 |
Paper | [//]: #09/27 |
 CFSP: An Efficient Structured Pruning Framework for LLMs with Coarse-to-Fine Activation Information Yuxin Wang, Minghua Ma, Zekun Wang, Jingchang Chen, Huiming Fan, Liping Shan, Qing Yang, Dongliang Xu, Ming Liu, Bing Qin |
 |
Github Paper |
[//]: #09/27 |
| OATS: Outlier-Aware Pruning Through Sparse and Low Rank Decomposition Stephen Zhang, Vardan Papyan |
Paper | [//]: #09/27 | |
| KVPruner: Structural Pruning for Faster and Memory-Efficient Large Language Models Bo Lv, Quan Zhou, Xuanang Ding, Yan Wang, Zeming Ma |
 |
Paper | [//]: #09/21 |
| Evaluating the Impact of Compression Techniques on Task-Specific Performance of Large Language Models Bishwash Khanal, Jeffery M. Capone |
 |
Paper | [//]: #09/21 |
| STUN: Structured-Then-Unstructured Pruning for Scalable MoE Pruning Jaeseong Lee, seung-won hwang, Aurick Qiao, Daniel F Campos, Zhewei Yao, Yuxiong He |
 |
Paper | [//]: #09/13 |
 PAT: Pruning-Aware Tuning for Large Language Models Yijiang Liu, Huanrui Yang, Youxin Chen, Rongyu Zhang, Miao Wang, Yuan Du, Li Du |
 |
Github Paper |
[//]: #09/02 |
| LLM Pruning and Distillation in Practice: The Minitron Approach Sharath Turuvekere Sreenivas, Saurav Muralidharan, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov |
 |
Paper | [//]: #08/27 |
| Language-specific Calibration for Pruning Multilingual Language Models Simon Kurz, Zhixue Zhao, Jian-Jia Chen, Lucie Flek |
Paper | [//]: #08/27 | |
 LLM-Barber: Block-Aware Rebuilder for Sparsity Mask in One-Shot for Large Language Models Yupeng Su, Ziyi Guan, Xiaoqun Liu, Tianlai Jin, Dongkuan Wu, Graziano Chesi, Ngai Wong, Hao Yu |
 |
Github Paper |
[//]: #08/27 |
| Enhancing One-shot Pruned Pre-trained Language Models through Sparse-Dense-Sparse Mechanism Guanchen Li, Xiandong Zhao, Lian Liu, Zeping Li, Dong Li, Lu Tian, Jie He, Ashish Sirasao, Emad Barsoum |
 |
Paper | [//]: #08/27 |
| A Convex-optimization-based Layer-wise Post-training Pruner for Large Language Models Pengxiang Zhao, Hanyu Hu, Ping Li, Yi Zheng, Zhefeng Wang, Xiaoming Yuan |
 |
Paper | [//]: #08/08 |
| Pruning Large Language Models with Semi-Structural Adaptive Sparse Training Weiyu Huang, Guohao Jian, Yuezhou Hu, Jun Zhu, Jianfei Chen |
 |
Paper | [//]: #08/08 |
| Greedy Output Approximation: Towards Efficient Structured Pruning for LLMs Without Retraining Jianwei Li, Yijun Dong, Qi Lei |
 |
Paper | [//]: #08/08 |
 Compact Language Models via Pruning and Knowledge Distillation Saurav Muralidharan, Sharath Turuvekere Sreenivas, Raviraj Joshi, Marcin Chochowski, Mostofa Patwary, Mohammad Shoeybi, Bryan Catanzaro, Jan Kautz, Pavlo Molchanov |
 |
Github Paper |
[//]: #07/29 |
| MINI-LLM: Memory-Efficient Structured Pruning for Large Language Models Hongrong Cheng, Miao Zhang, Javen Qinfeng Shi |
 |
Paper | [//]: #07/21 |
| Reconstruct the Pruned Model without Any Retraining Pingjie Wang, Ziqing Fan, Shengchao Hu, Zhe Chen, Yanfeng Wang, Yu Wang |
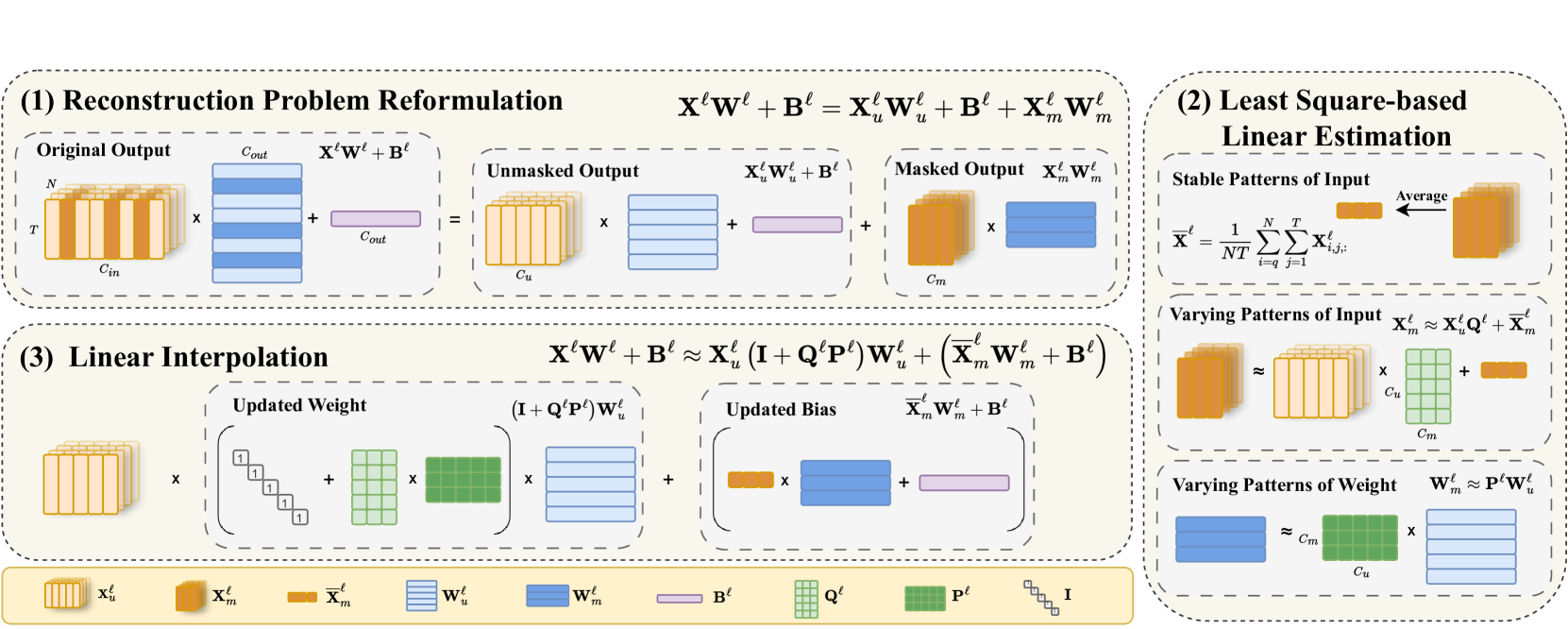 |
Paper | [//]: #07/21 |
| Q-Sparse: All Large Language Models can be Fully Sparsely-Activated Hongyu Wang, Shuming Ma, Ruiping Wang, Furu Wei |
 |
Paper | [//]: #07/16 |
Knowledge Distillation
| Title & Authors | Introduction | Links | |
|---|---|---|---|
| :star: Knowledge Distillation of Large Language Models Yuxian Gu, Li Dong, Furu Wei, Minlie Huang |
 |
Github Paper |
[//]: #Recommend |
| Pre-training Distillation for Large Language Models: A Design Space Exploration Hao Peng, Xin Lv, Yushi Bai, Zijun Yao, Jiajie Zhang, Lei Hou, Juanzi Li |
Paper | [//]: #10/30 | |
 MiniPLM: Knowledge Distillation for Pre-Training Language Models Yuxian Gu, Hao Zhou, Fandong Meng, Jie Zhou, Minlie Huang |
 |
Github Paper |
[//]: #10/29 |
| Speculative Knowledge Distillation: Bridging the Teacher-Student Gap Through Interleaved Sampling Wenda Xu, Rujun Han, Zifeng Wang, Long T. Le, Dhruv Madeka, Lei Li, William Yang Wang, Rishabh Agarwal, Chen-Yu Lee, Tomas Pfister |
 |
Paper | [//]: #10/21 |
| Evolutionary Contrastive Distillation for Language Model Alignment Julian Katz-Samuels, Zheng Li, Hyokun Yun, Priyanka Nigam, Yi Xu, Vaclav Petricek, Bing Yin, Trishul Chilimbi |
 |
Paper | [//]: #10/13 |
| BabyLlama-2: Ensemble-Distilled Models Consistently Outperform Teachers With Limited Data Jean-Loup Tastet, Inar Timiryasov |
Paper | [//]: #09/27 | |
| EchoAtt: Attend, Copy, then Adjust for More Efficient Large Language Models Hossein Rajabzadeh, Aref Jafari, Aman Sharma, Benyamin Jami, Hyock Ju Kwon, Ali Ghodsi, Boxing Chen, Mehdi Rezagholizadeh |
 |
Paper | [//]: #09/27 |
 SKIntern: Internalizing Symbolic Knowledge for Distilling Better CoT Capabilities into Small Language Models Huanxuan Liao, Shizhu He, Yupu Hao, Xiang Li, Yuanzhe Zhang, Kang Liu, Jun Zhao |
 |
Github Paper |
[//]: #09/27 |
 [ [LLMR: Knowledge Distillation with a Large Language Model-Induced Reward Dongheng Li, Yongchang Hao, Lili Mou |
 |
Github Paper |
[//]: #09/21 |
| Exploring and Enhancing the Transfer of Distribution in Knowledge Distillation for Autoregressive Language Models Jun Rao, Xuebo Liu, Zepeng Lin, Liang Ding, Jing Li, Dacheng Tao |
 |
Paper | [//]: #09/21 |
| Efficient Knowledge Distillation: Empowering Small Language Models with Teacher Model Insights Mohamad Ballout, Ulf Krumnack, Gunther Heidemann, Kai-Uwe Kühnberger |
 |
Paper | [//]: #09/21 |
 The Mamba in the Llama: Distilling and Accelerating Hybrid Models Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao |
 |
Github Paper |
[//]: #09/02 |
| FIRST: Teach A Reliable Large Language Model Through Efficient Trustworthy Distillation KaShun Shum, Minrui Xu, Jianshu Zhang, Zixin Chen, Shizhe Diao, Hanze Dong, Jipeng Zhang, Muhammad Omer Raza |
 |
Paper | [//]: #08/27 |
| Interactive DualChecker for Mitigating Hallucinations in Distilling Large Language Models Meiyun Wang, Masahiro Suzuki, Hiroki Sakaji, Kiyoshi Izumi |
 |
Paper | [//]: #08/27 |
| Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models Aviv Bick, Kevin Y. Li, Eric P. Xing, J. Zico Kolter, Albert Gu |
 |
Paper | [//]: #08/20 |
| Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting Emmanuel Aboah Boateng, Cassiano O. Becker, Nabiha Asghar, Kabir Walia, Ashwin Srinivasan, Ehi Nosakhare, Victor Dibia, Soundar Srinivasan |
 |
Paper | [//]: #08/20 |
| LaDiMo: Layer-wise Distillation Inspired MoEfier Sungyoon Kim, Youngjun Kim, Kihyo Moon, Minsung Jang |
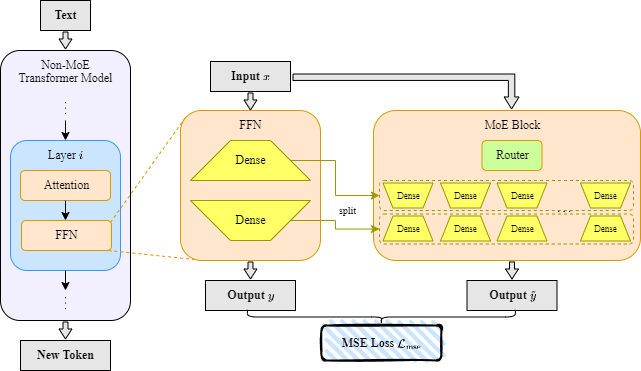 |
Paper | [//]: #08/13 |
| BOND: Aligning LLMs with Best-of-N Distillation Pier Giuseppe Sessa, Robert Dadashi, Léonard Hussenot, Johan Ferret, Nino Vieillard et al |
 |
Paper | [//]: #07/29 |
| Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models Quan Li, Tianxiang Zhao, Lingwei Chen, Junjie Xu, Suhang Wang |
 |
Paper | [//]: #07/24 |
| DDK: Distilling Domain Knowledge for Efficient Large Language Models Jiaheng Liu, Chenchen Zhang, Jinyang Guo, Yuanxing Zhang, Haoran Que et al |
 |
Paper | [//]: #07/24 |
| Key-Point-Driven Mathematical Reasoning Distillation of Large Language Model Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang |
 |
Paper | [//]: #07/16 |
| Don't Throw Away Data: Better Sequence Knowledge Distillation Jun Wang, Eleftheria Briakou, Hamid Dadkhahi, Rishabh Agarwal, Colin Cherry, Trevor Cohn |
Paper | [//]: #07/16 | |
| Multi-Granularity Semantic Revision for Large Language Model Distillation Xiaoyu Liu, Yun Zhang, Wei Li, Simiao Li, Xudong Huang, Hanting Chen, Yehui Tang, Jie Hu, Zhiwei Xiong, Yunhe Wang |
 |
Paper | [//]: #07/16 |
Quantization
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 [ [:star: GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers Elias Frantar, Saleh Ashkboos, Torsten Hoefler, Dan Alistarh |
 |
Github Paper |
[//]: #Recommend |
 [ [:star: SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han |
 |
Github Paper |
[//]: #Recommend |
 :star: AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, Song Han |
 |
Github Paper |
[//]: #Recommend |
 [ [:star: OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, Ping Luo |
 |
Github Paper |
[//]: #Recommend |
| Understanding the difficulty of low-precision post-training quantization of large language models Zifei Xu, Sayeh Sharify, Wanzin Yazar, Tristan Webb, Xin Wang |
 |
Paper | [//]: #10/30 |
 1-bit AI Infra: Part 1.1, Fast and Lossless BitNet b1.58 Inference on CPUs Jinheng Wang, Hansong Zhou, Ting Song, Shaoguang Mao, Shuming Ma, Hongyu Wang, Yan Xia, Furu Wei |
 |
Github Paper |
[//]: #10/30 |
| QuAILoRA: Quantization-Aware Initialization for LoRA Neal Lawton, Aishwarya Padmakumar, Judith Gaspers, Jack FitzGerald, Anoop Kumar, Greg Ver Steeg, Aram Galstyan |
Paper | [//]: #10/30 | |
| Evaluating Quantized Large Language Models for Code Generation on Low-Resource Language Benchmarks Enkhbold Nyamsuren |
Paper | [//]: #10/30 | |
 :star: SqueezeLLM: Dense-and-Sparse Quantization Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer |
 |
Github Paper |
[//]: #Recommend |
| Pyramid Vector Quantization for LLMs Tycho F. A. van der Ouderaa, Maximilian L. Croci, Agrin Hilmkil, James Hensman |
 |
Paper | [//]: #10/29 |
| SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators Rasoul Shafipour, David Harrison, Maxwell Horton, Jeffrey Marker, Houman Bedayat, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi, Saman Naderiparizi |
 |
Paper | [//]: #10/21 |
 FlatQuant: Flatness Matters for LLM Quantization Yuxuan Sun, Ruikang Liu, Haoli Bai, Han Bao, Kang Zhao, Yuening Li, Jiaxin Hu, Xianzhi Yu, Lu Hou, Chun Yuan, Xin Jiang, Wulong Liu, Jun Yao |
 |
Github Paper |
[//]: #10/21 |
 SLiM: One-shot Quantized Sparse Plus Low-rank Approximation of LLMs Mohammad Mozaffari, Maryam Mehri Dehnavi |
 |
Github Paper |
[//]: #10/21 |
| Scaling laws for post-training quantized large language models Zifei Xu, Alexander Lan, Wanzin Yazar, Tristan Webb, Sayeh Sharify, Xin Wang |
 |
Paper | [//]: #10/21 |
| Continuous Approximations for Improving Quantization Aware Training of LLMs He Li, Jianhang Hong, Yuanzhuo Wu, Snehal Adbol, Zonglin Li |
Paper | [//]: #10/21 | |
 DAQ: Density-Aware Post-Training Weight-Only Quantization For LLMs Yingsong Luo, Ling Chen |
 |
Github Paper |
[//]: #10/21 |
 Quamba: A Post-Training Quantization Recipe for Selective State Space Models Hung-Yueh Chiang, Chi-Chih Chang, Natalia Frumkin, Kai-Chiang Wu, Diana Marculescu |
 |
Github Paper |
[//]: #10/21 |
| AsymKV: Enabling 1-Bit Quantization of KV Cache with Layer-Wise Asymmetric Quantization Configurations Qian Tao, Wenyuan Yu, Jingren Zhou |
 |
Paper | [//]: #10/21 |
| Channel-Wise Mixed-Precision Quantization for Large Language Models Zihan Chen, Bike Xie, Jundong Li, Cong Shen |
 |
Paper | [//]: #10/21 |
| Progressive Mixed-Precision Decoding for Efficient LLM Inference Hao Mark Chen, Fuwen Tan, Alexandros Kouris, Royson Lee, Hongxiang Fan, Stylianos I. Venieris |
 |
Paper | [//]: #10/21 |
 EXAQ: Exponent Aware Quantization For LLMs Acceleration Moran Shkolnik, Maxim Fishman, Brian Chmiel, Hilla Ben-Yaacov, Ron Banner, Kfir Yehuda Levy |
 |
Github Paper |
[//]: #10/14 |
 PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs Mengzhao Chen, Yi Liu, Jiahao Wang, Yi Bin, Wenqi Shao, Ping Luo |
 |
Github Paper |
[//]: #10/14 |
 :star: Extreme Compression of Large Language Models via Additive Quantization Vage Egiazarian, Andrei Panferov, Denis Kuznedelev, Elias Frantar, Artem Babenko, Dan Alistarh |
 |
Github Paper |
[//]: #Recommend |
| Scaling Laws for Mixed quantization in Large Language Models Zeyu Cao, Cheng Zhang, Pedro Gimenes, Jianqiao Lu, Jianyi Cheng, Yiren Zhao |
 |
Paper | [//]: #10/14 |
| PalmBench: A Comprehensive Benchmark of Compressed Large Language Models on Mobile Platforms Yilong Li, Jingyu Liu, Hao Zhang, M Badri Narayanan, Utkarsh Sharma, Shuai Zhang, Pan Hu, Yijing Zeng, Jayaram Raghuram, Suman Banerjee |
 |
Paper | [//]: #10/14 |
| CrossQuant: A Post-Training Quantization Method with Smaller Quantization Kernel for Precise Large Language Model Compression Wenyuan Liu, Xindian Ma, Peng Zhang, Yan Wang |
 |
Paper | [//]: #10/13 |
| SageAttention: Accurate 8-Bit Attention for Plug-and-play Inference Acceleration Jintao Zhang, Jia wei, Pengle Zhang, Jun Zhu, Jianfei Chen |
 |
Paper | [//]: #10/04 |
| Addition is All You Need for Energy-efficient Language Models Hongyin Luo, Wei Sun |
 |
Paper | [//]: #10/02 |
 VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models Yifei Liu, Jicheng Wen, Yang Wang, Shengyu Ye, Li Lyna Zhang, Ting Cao, Cheng Li, Mao Yang |
 |
Github Paper |
[//]: #09/27 |
 INT-FlashAttention: Enabling Flash Attention for INT8 Quantization Shimao Chen, Zirui Liu, Zhiying Wu, Ce Zheng, Peizhuang Cong, Zihan Jiang, Yuhan Wu, Lei Su, Tong Yang |
 |
Github Paper |
[//]: #09/27 |
| Accumulator-Aware Post-Training Quantization Ian Colbert, Fabian Grob, Giuseppe Franco, Jinjie Zhang, Rayan Saab |
 |
Paper | [//]: #09/27 |
 [ [DuQuant: Distributing Outliers via Dual Transformation Makes Stronger Quantized LLMs Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, Ying Wei |
 |
Github Paper |
[//]: #09/27 |
| A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B Jemin Lee, Sihyeong Park, Jinse Kwon, Jihun Oh, Yongin Kwon |
 |
Paper | [//]: #09/21 |
| The Uniqueness of LLaMA3-70B with Per-Channel Quantization: An Empirical Study Minghai Qin |
 |
Paper | [//]: #09/02 |
| Matmul or No Matmal in the Era of 1-bit LLMs Jinendra Malekar, Mohammed E. Elbtity, Ramtin Zand Co |
 |
Paper | [//]: #08/27 |
 MobileQuant: Mobile-friendly Quantization for On-device Language Models Fuwen Tan, Royson Lee, Łukasz Dudziak, Shell Xu Hu, Sourav Bhattacharya, Timothy Hospedales, Georgios Tzimiropoulos, Brais Martinez |
 |
Github Paper |
[//]: #08/27 |
 ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models Chao Zeng, Songwei Liu, Yusheng Xie, Hong Liu, Xiaojian Wang, Miao Wei, Shu Yang, Fangmin Chen, Xing Mei |
 |
Github Paper |
[//]: #08/20 |
| STBLLM: Breaking the 1-Bit Barrier with Structured Binary LLMs Peijie Dong, Lujun Li, Dayou Du, Yuhan Chen, Zhenheng Tang, Qiang Wang, Wei Xue, Wenhan Luo, Qifeng Liu, Yike Guo, Xiaowen Chu |
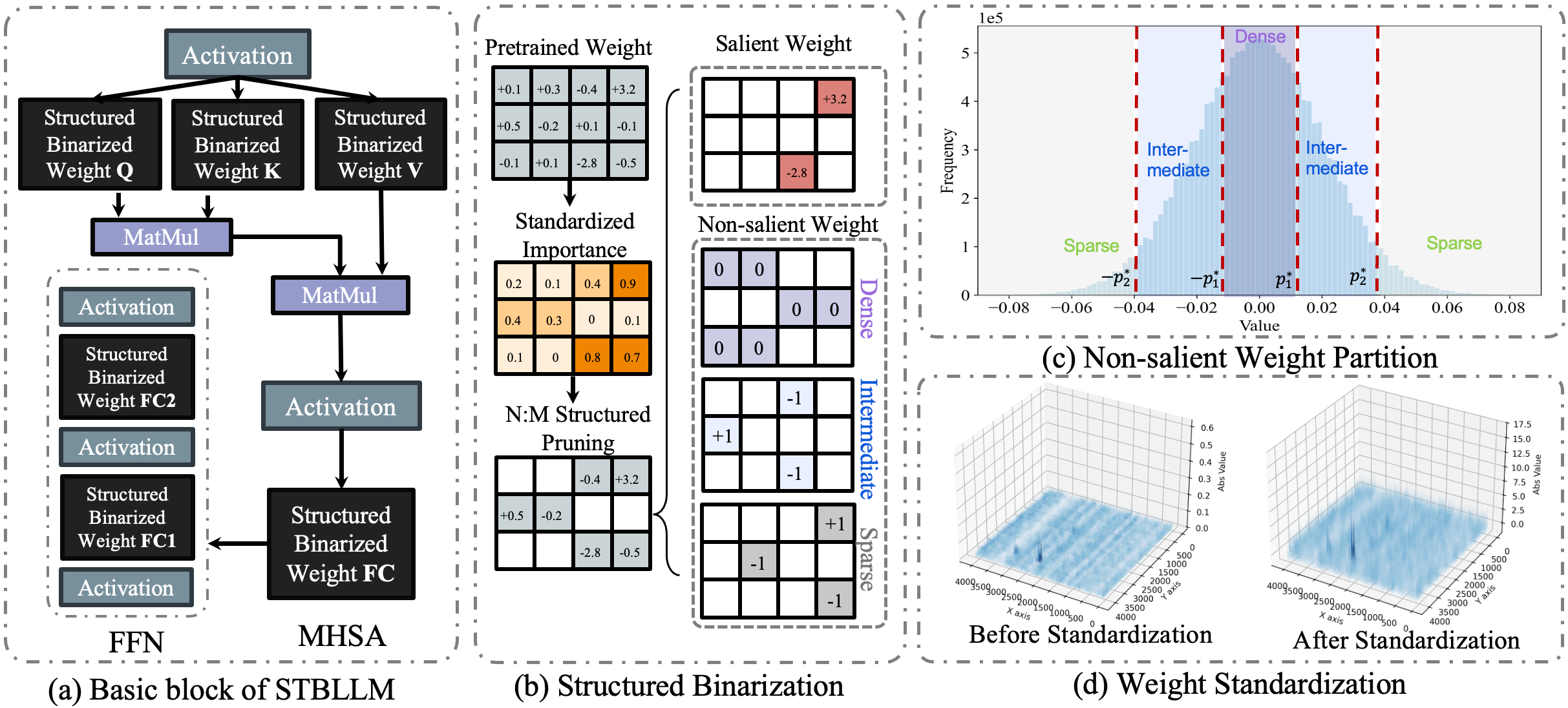 |
Paper | [//]: #08/08 |
 Accurate and Efficient Fine-Tuning of Quantized Large Language Models Through Optimal Balance Ao Shen, Qiang Wang, Zhiquan Lai, Xionglve Li, Dongsheng Li |
 |
Github Paper |
[//]: #07/26 |
 [ [Scalify: scale propagation for efficient low-precision LLM training Paul Balança, Sam Hosegood, Carlo Luschi, Andrew Fitzgibbon |
Github Paper |
[//]: #07/26 | |
 EfficientQAT: Efficient Quantization-Aware Training for Large Language Models Mengzhao Chen, Wenqi Shao, Peng Xu, Jiahao Wang, Peng Gao, Kaipeng Zhang, Yu Qiao, Ping Luo |
 |
Github Paper |
[//]: #07/21 |
 LRQ: Optimizing Post-Training Quantization for Large Language Models by Learning Low-Rank Weight-Scaling Matrices Jung Hyun Lee, Jeonghoon Kim, June Yong Yang, Se Jung Kwon, Eunho Yang, Kang Min Yoo, Dongsoo Lee |
 |
Github Paper |
[//]: #07/21 |
 Spectra: A Comprehensive Study of Ternary, Quantized, and FP16 Language Models Ayush Kaushal, Tejas Pandey, Tejas Vaidhya, Aaryan Bhagat, Irina Rish |
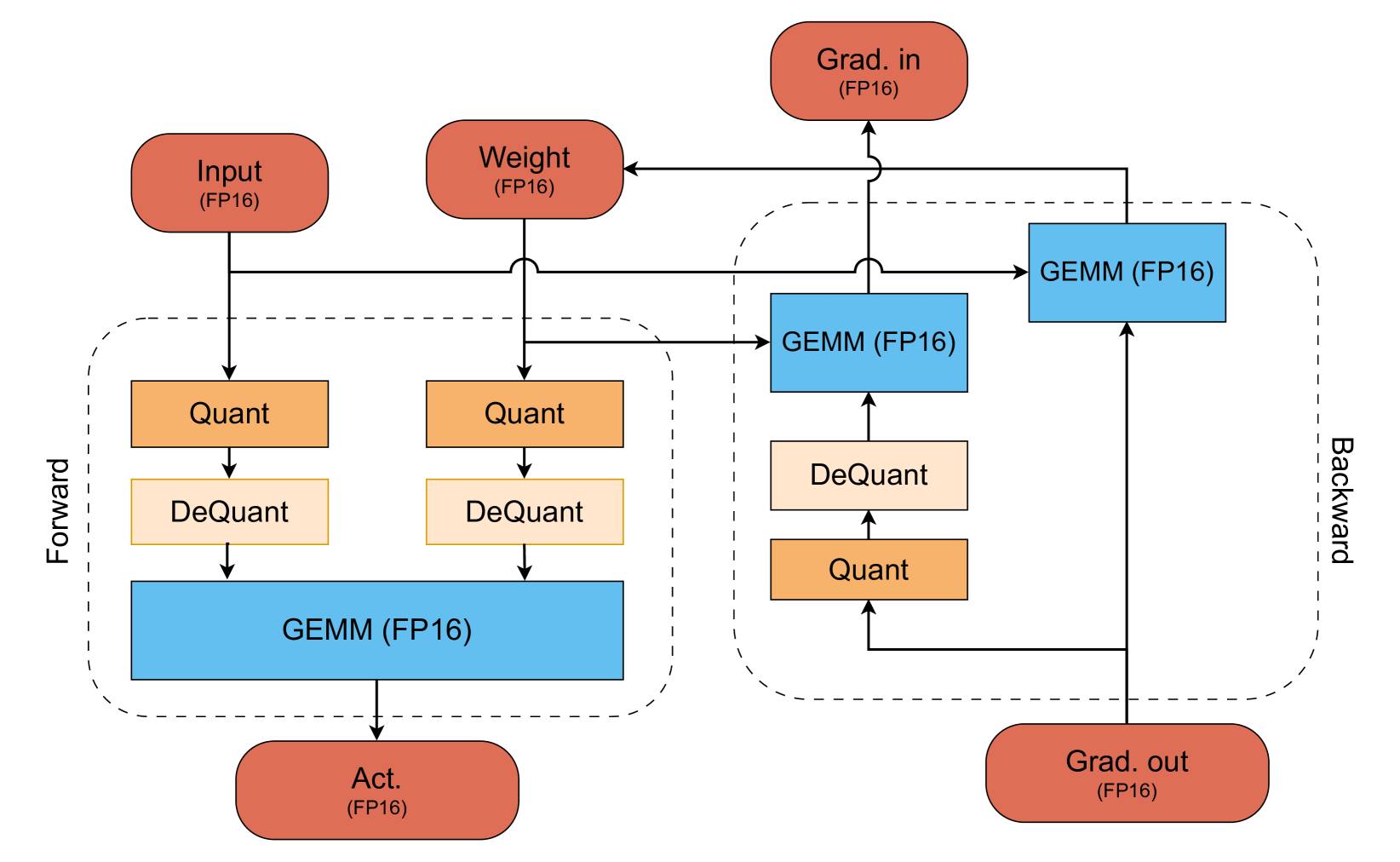 |
Github Paper |
[//]: #07/21 |
 Fast Matrix Multiplications for Lookup Table-Quantized LLMs Han Guo, William Brandon, Radostin Cholakov, Jonathan Ragan-Kelley, Eric P. Xing, Yoon Kim |
 |
Github Paper |
[//]: #07/16 |
| LeanQuant: Accurate Large Language Model Quantization with Loss-Error-Aware Grid Tianyi Zhang, Anshumali Shrivastava |
 |
Paper | [//]: #07/16 |
| Prefixing Attention Sinks can Mitigate Activation Outliers for Large Language Model Quantization Seungwoo Son, Wonpyo Park, Woohyun Han, Kyuyeun Kim, Jaeho Lee |
 |
Paper | [//]: #07/16 |
Inference Acceleration
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 [ [:star: Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time Zichang Liu, Jue WANG, Tri Dao, Tianyi Zhou, Binhang Yuan, Zhao Song, Anshumali Shrivastava, Ce Zhang, Yuandong Tian, Christopher Re, Beidi Chen |
 |
Github Paper |
[//]: #Recommend |
 :star: SpecInfer: Accelerating Generative LLM Serving with Speculative Inference and Token Tree Verification Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Rae Ying Yee Wong, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, Zhihao Jia |
 |
Github paper |
[//]: #Recommend |
 :star: Efficient Streaming Language Models with Attention Sinks Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, Mike Lewis |
 |
Github Paper |
[//]: #Recommend |
 :star: EAGLE: Lossless Acceleration of LLM Decoding by Feature Extrapolation Yuhui Li, Chao Zhang, and Hongyang Zhang |
 |
Github Blog |
[//]: #Recommend |
 :star: Medusa: Simple LLM Inference Acceleration Framework with Multiple Decoding Heads Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, Tri Dao |
 |
Github Paper |
[//]: #Recommend |
 MagicPIG: LSH Sampling for Efficient LLM Generation Zhuoming Chen, Ranajoy Sadhukhan, Zihao Ye, Yang Zhou, Jianyu Zhang, Niklas Nolte, Yuandong Tian, Matthijs Douze, Leon Bottou, Zhihao Jia, Beidi Chen |
 |
Github Paper |
[//]: #10/30 |
| Faster Language Models with Better Multi-Token Prediction Using Tensor Decomposition Artem Basharin, Andrei Chertkov, Ivan Oseledets |
 |
Paper | [//]: #10/29 |
| Efficient Inference for Augmented Large Language Models Rana Shahout, Cong Liang, Shiji Xin, Qianru Lao, Yong Cui, Minlan Yu, Michael Mitzenmacher |
 |
Paper | [//]: #10/29 |
 Dynamic Vocabulary Pruning in Early-Exit LLMs Jort Vincenti, Karim Abdel Sadek, Joan Velja, Matteo Nulli, Metod Jazbec |
 |
Github Paper |
[//]: #10/29 |
 CoreInfer: Accelerating Large Language Model Inference with Semantics-Inspired Adaptive Sparse Activation Qinsi Wang, Saeed Vahidian, Hancheng Ye, Jianyang Gu, Jianyi Zhang, Yiran Chen |
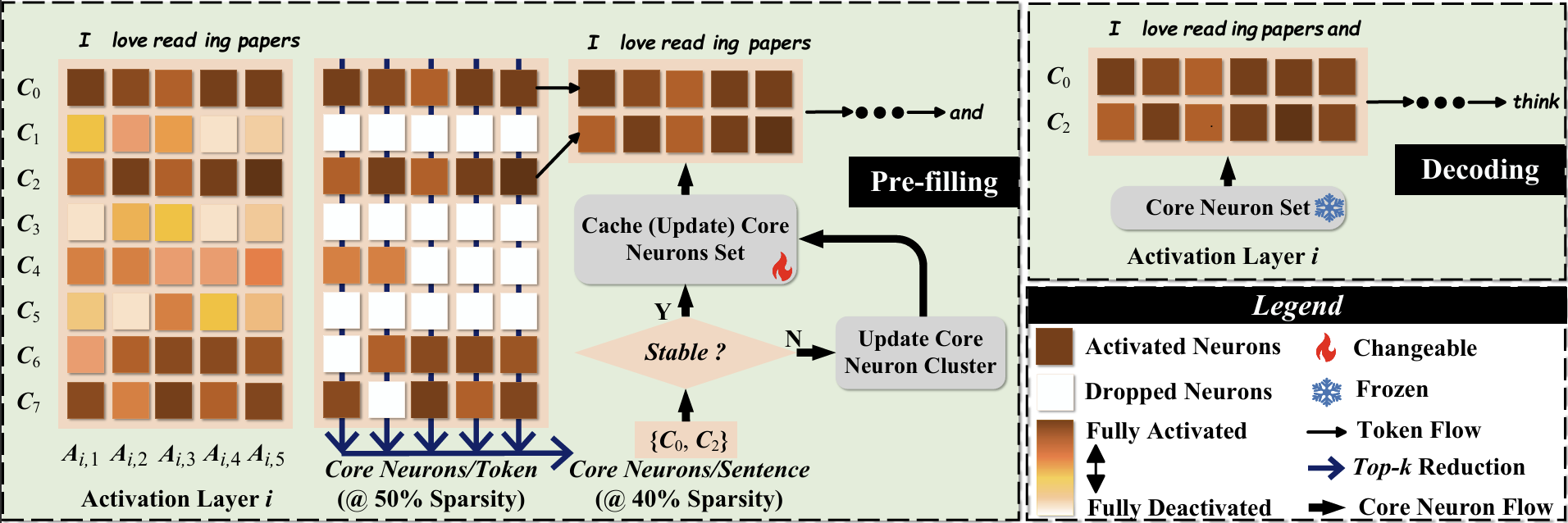 |
Github Paper |
[//]: #10/29 |
 DuoAttention: Efficient Long-Context LLM Inference with Retrieval and Streaming Heads Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, Song Han |
 |
Github Paper |
[//]: #10/21 |
| DySpec: Faster Speculative Decoding with Dynamic Token Tree Structure Yunfan Xiong, Ruoyu Zhang, Yanzeng Li, Tianhao Wu, Lei Zou |
 |
Paper | [//]: #10/21 |
| QSpec: Speculative Decoding with Complementary Quantization Schemes Juntao Zhao, Wenhao Lu, Sheng Wang, Lingpeng Kong, Chuan Wu |
 |
Paper | [//]: #10/21 |
| TidalDecode: Fast and Accurate LLM Decoding with Position Persistent Sparse Attention Lijie Yang, Zhihao Zhang, Zhuofu Chen, Zikun Li, Zhihao Jia |
 |
Paper | [//]: #10/14 |
| ParallelSpec: Parallel Drafter for Efficient Speculative Decoding Zilin Xiao, Hongming Zhang, Tao Ge, Siru Ouyang, Vicente Ordonez, Dong Yu |
 |
Paper | [//]: #10/14 |
 SWIFT: On-the-Fly Self-Speculative Decoding for LLM Inference Acceleration Heming Xia, Yongqi Li, Jun Zhang, Cunxiao Du, Wenjie Li |
 |
Github Paper |
[//]: #10/14 |
 TurboRAG: Accelerating Retrieval-Augmented Generation with Precomputed KV Caches for Chunked Text Songshuo Lu, Hua Wang, Yutian Rong, Zhi Chen, Yaohua Tang |
 |
Github Paper |
[//]: #10/13 |
| A Little Goes a Long Way: Efficient Long Context Training and Inference with Partial Contexts Suyu Ge, Xihui Lin, Yunan Zhang, Jiawei Han, Hao Peng |
 |
Paper | [//]: #10/04 |
| Mnemosyne: Parallelization Strategies for Efficiently Serving Multi-Million Context Length LLM Inference Requests Without Approximations Amey Agrawal, Junda Chen, Íñigo Goiri, Ramachandran Ramjee, Chaojie Zhang, Alexey Tumanov, Esha Choukse |
 |
Paper | [//]: #09/27 |
 Discovering the Gems in Early Layers: Accelerating Long-Context LLMs with 1000x Input Token Reduction Zhenmei Shi, Yifei Ming, Xuan-Phi Nguyen, Yingyu Liang, Shafiq Joty |
 |
Github Paper |
[//]: #09/27 |
| Dynamic-Width Speculative Beam Decoding for Efficient LLM Inference Zongyue Qin, Zifan He, Neha Prakriya, Jason Cong, Yizhou Sun |
 |
Paper | [//]: #09/27 |
 CritiPrefill: A Segment-wise Criticality-based Approach for Prefilling Acceleration in LLMs Junlin Lv, Yuan Feng, Xike Xie, Xin Jia, Qirong Peng, Guiming Xie |
 |
Github Paper |
[//]: #09/21 |
| RetrievalAttention: Accelerating Long-Context LLM Inference via Vector Retrieval Di Liu, Meng Chen, Baotong Lu, Huiqiang Jiang, Zhenhua Han, Qianxi Zhang, Qi Chen, Chengruidong Zhang, Bailu Ding, Kai Zhang, Chen Chen, Fan Yang, Yuqing Yang, Lili Qiu |
 |
Paper | [//]: #09/21 |
 Sirius: Contextual Sparsity with Correction for Efficient LLMs Yang Zhou, Zhuoming Chen, Zhaozhuo Xu, Victoria Lin, Beidi Chen |
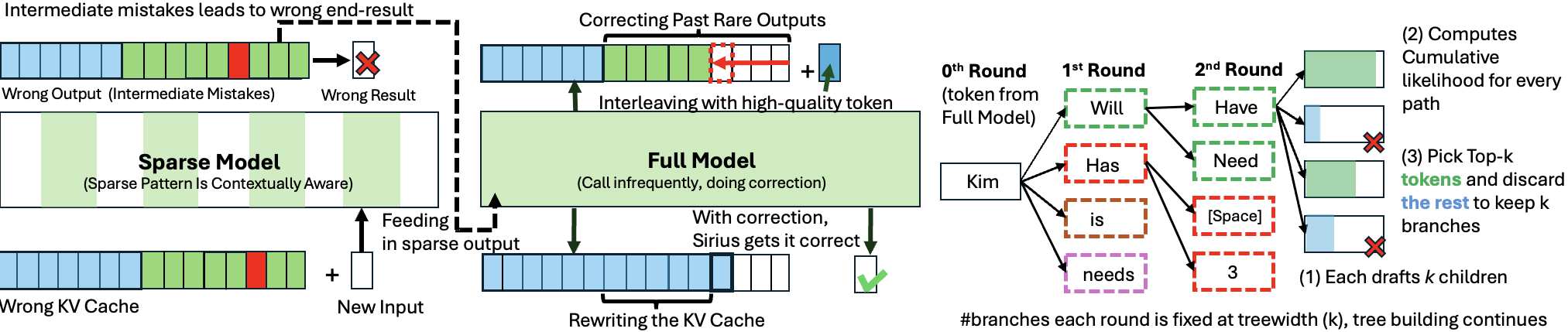 |
Github Paper |
[//]: #09/13 |
 OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs Jintian Zhang, Cheng Peng, Mengshu Sun, Xiang Chen, Lei Liang, Zhiqiang Zhang, Jun Zhou, Huajun Chen, Ningyu Zhang |
 |
Github Paper |
[//]: #09/13 |
| Path-Consistency: Prefix Enhancement for Efficient Inference in LLM Jiace Zhu, Yingtao Shen, Jie Zhao, An Zou |
 |
Paper | [//]: #09/06 |
| Boosting Lossless Speculative Decoding via Feature Sampling and Partial Alignment Distillation Lujun Gui, Bin Xiao, Lei Su, Weipeng Chen |
 |
Paper | [//]: #09/02 |
| Turning Trash into Treasure: Accelerating Inference of Large Language Models with Token Recycling Xianzhen Luo, Yixuan Wang, Qingfu Zhu, Zhiming Zhang, Xuanyu Zhang, Qing Yang, Dongliang Xu, Wanxiang Che |
 |
Paper | [//]: #08/20 |
| Speculative Diffusion Decoding: Accelerating Language Generation through Diffusion Jacob K Christopher, Brian R Bartoldson, Bhavya Kailkhura, Ferdinando Fioretto |
 |
Paper | [//]: #08/13 |
 Clover-2: Accurate Inference for Regressive Lightweight Speculative Decoding Bin Xiao, Lujun Gui, Lei Su, Weipeng Chen |
 |
Github Paper |
[//]: #08/08 |
| Accelerating Large Language Model Inference with Self-Supervised Early Exits Florian Valade |
Paper | [//]: #08/08 | |
| An Efficient Inference Framework for Early-exit Large Language Models Ruijie Miao, Yihan Yan, Xinshuo Yao, Tong Yang |
Paper | [//]: #08/08 | |
| [ Inference acceleration for large language models using "stairs" assisted greedy generation Domas Grigaliūnas, Mantas Lukoševičius |
 |
Paper | [//]: #08/08 |
| LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference Qichen Fu, Minsik Cho, Thomas Merth, Sachin Mehta, Mohammad Rastegari, Mahyar Najibi |
 |
Paper | [//]: #07/24 |
| Adaptive Draft-Verification for Efficient Large Language Model Decoding Xukun Liu, Bowen Lei, Ruqi Zhang, Dongkuan Xu |
 |
Paper | [//]: #07/21 |
| Multi-Token Joint Speculative Decoding for Accelerating Large Language Model Inference Zongyue Qin, Ziniu Hu, Zifan He, Neha Prakriya, Jason Cong, Yizhou Sun |
 |
Paper | [//]: #07/16 |
Efficient MOE
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 :star: Fast Inference of Mixture-of-Experts Language Models with Offloading Artyom Eliseev, Denis Mazur |
 |
Github Paper |
[//]: #Recommend |
| ExpertFlow: Optimized Expert Activation and Token Allocation for Efficient Mixture-of-Experts Inference Xin He, Shunkang Zhang, Yuxin Wang, Haiyan Yin, Zihao Zeng, Shaohuai Shi, Zhenheng Tang, Xiaowen Chu, Ivor Tsang, Ong Yew Soon |
 |
Paper | [//]: #10/29 |
| EPS-MoE: Expert Pipeline Scheduler for Cost-Efficient MoE Inference Yulei Qian, Fengcun Li, Xiangyang Ji, Xiaoyu Zhao, Jianchao Tan, Kefeng Zhang, Xunliang Cai |
Paper | [//]: #10/21 | |
 MC-MoE: Mixture Compressor for Mixture-of-Experts LLMs Gains More Wei Huang, Yue Liao, Jianhui Liu, Ruifei He, Haoru Tan, Shiming Zhang, Hongsheng Li, Si Liu, Xiaojuan Qi |
 |
Github Paper |
[//]: #10/14 |
| Diversifying the Expert Knowledge for Task-Agnostic Pruning in Sparse Mixture-of-Experts Zeliang Zhang, Xiaodong Liu, Hao Cheng, Chenliang Xu, Jianfeng Gao |
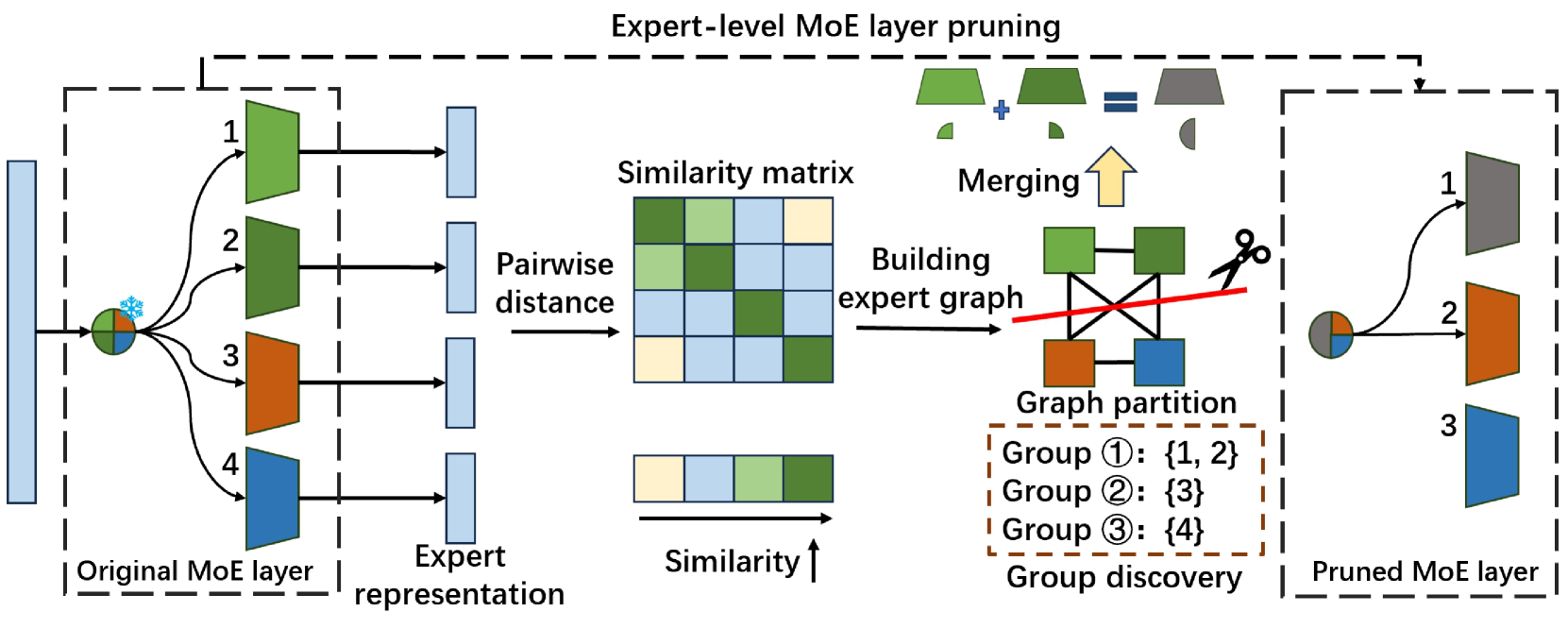 |
Paper | [//]: #07/16 |
Efficient Architecture of LLM
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 :star: MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |
 |
Github Paper Model |
[//]: #Recommend |
 :star: Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou |
 |
Github Paper |
[//]: #Recommend |
| Taipan: Efficient and Expressive State Space Language Models with Selective Attention Chien Van Nguyen, Huy Huu Nguyen, Thang M. Pham, Ruiyi Zhang, Hanieh Deilamsalehy, Puneet Mathur, Ryan A. Rossi, Trung Bui, Viet Dac Lai, Franck Dernoncourt, Thien Huu Nguyen |
 |
Paper | [//]: #10/29 |
 SeerAttention: Learning Intrinsic Sparse Attention in Your LLMs Yizhao Gao, Zhichen Zeng, Dayou Du, Shijie Cao, Hayden Kwok-Hay So, Ting Cao, Fan Yang, Mao Yang |
 |
Github Paper |
[//]: #10/21 |
 Basis Sharing: Cross-Layer Parameter Sharing for Large Language Model Compression Jingcun Wang, Yu-Guang Chen, Ing-Chao Lin, Bing Li, Grace Li Zhang |
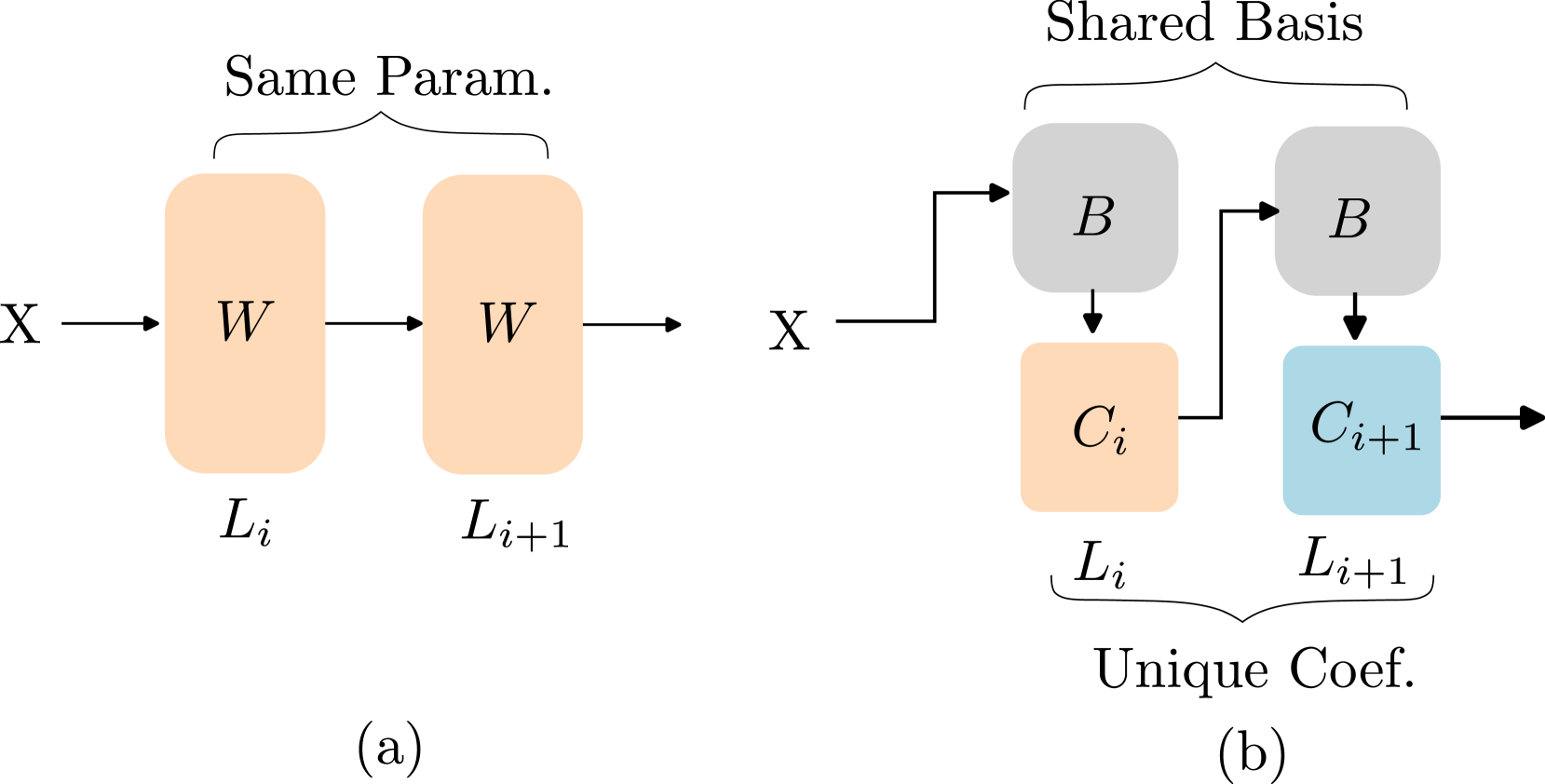 |
Github Paper |
[//]: #10/14 |
| Rodimus*: Breaking the Accuracy-Efficiency Trade-Off with Efficient Attentions Zhihao He, Hang Yu, Zi Gong, Shizhan Liu, Jianguo Li, Weiyao Lin |
 |
Paper | [//]: #10/14 |
| SentenceVAE: Enable Next-sentence Prediction for Large Language Models with Faster Speed, Higher Accuracy and Longer Context Hongjun An, Yifan Chen, Zhe Sun, Xuelong Li |
 |
Paper | [//]: #08/08 |
 Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads Xihui Lin, Yunan Zhang, Suyu Ge, Barun Patra, Vishrav Chaudhary, Xia Song |
 |
Github Paper |
[//]: #07/26 |
 Beyond KV Caching: Shared Attention for Efficient LLMs Bingli Liao, Danilo Vasconcellos Vargas |
 |
Github Paper |
[//]: #07/21 |
KV Cache Compression
| Title & Authors | Introduction | Links | |
|---|---|---|---|
| :star: Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao |
 |
Paper | [//]: #Recommend |
 A Systematic Study of Cross-Layer KV Sharing for Efficient LLM Inference You Wu, Haoyi Wu, Kewei Tu |
 |
Github Paper |
[//]: #10/30 |
| Lossless KV Cache Compression to 2% Zhen Yang, J.N.Han, Kan Wu, Ruobing Xie, An Wang, Xingwu Sun, Zhanhui Kang |
 |
Paper | [//]: #10/30 |
| MatryoshkaKV: Adaptive KV Compression via Trainable Orthogonal Projection Bokai Lin, Zihao Zeng, Zipeng Xiao, Siqi Kou, Tianqi Hou, Xiaofeng Gao, Hao Zhang, Zhijie Deng |
 |
Paper | [//]: #10/30 |
 Residual vector quantization for KV cache compression in large language model Ankur Kumar |
Github Paper |
[//]: #10/30 | |
 KVSharer: Efficient Inference via Layer-Wise Dissimilar KV Cache Sharing Yifei Yang, Zouying Cao, Qiguang Chen, Libo Qin, Dongjie Yang, Hai Zhao, Zhi Chen |
 |
Github Paper |
[//]: #10/29 |
| LoRC: Low-Rank Compression for LLMs KV Cache with a Progressive Compression Strategy Rongzhi Zhang, Kuang Wang, Liyuan Liu, Shuohang Wang, Hao Cheng, Chao Zhang, Yelong Shen |
 |
Paper | [//]: #10/14 |
| SwiftKV: Fast Prefill-Optimized Inference with Knowledge-Preserving Model Transformation Aurick Qiao, Zhewei Yao, Samyam Rajbhandari, Yuxiong He |
 |
Paper | [//]: #10/14 |
| [ Dynamic Memory Compression: Retrofitting LLMs for Accelerated Inference Piotr Nawrot, Adrian Łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti |
 |
Paper | [//]: #10/02 |
| KV-Compress: Paged KV-Cache Compression with Variable Compression Rates per Attention Head Isaac Rehg |
 |
Paper | [//]: #10/02 |
 Ada-KV: Optimizing KV Cache Eviction by Adaptive Budget Allocation for Efficient LLM Inference Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, S. Kevin Zhou |
 |
Github Paper |
[//]: #10/13 |
 AlignedKV: Reducing Memory Access of KV-Cache with Precision-Aligned Quantization Yifan Tan, Haoze Wang, Chao Yan, Yangdong Deng |
 |
Github Paper |
[//]: #09/27 |
| CSKV: Training-Efficient Channel Shrinking for KV Cache in Long-Context Scenarios Luning Wang, Shiyao Li, Xuefei Ning, Zhihang Yuan, Shengen Yan, Guohao Dai, Yu Wang |
 |
Paper | [//]: #09/21 |
| A First Look At Efficient And Secure On-Device LLM Inference Against KV Leakage Huan Yang, Deyu Zhang, Yudong Zhao, Yuanchun Li, Yunxin Liu |
 |
Paper | [//]: #09/13 |
 Post-Training Sparse Attention with Double Sparsity Shuo Yang, Ying Sheng, Joseph E. Gonzalez, Ion Stoica, Lianmin Zheng |
 |
Github Paper |
[//]: #08/20 |
 Eigen Attention: Attention in Low-Rank Space for KV Cache Compression Utkarsh Saxena, Gobinda Saha, Sakshi Choudhary, Kaushik Roy |
 |
Github Paper |
[//]: #08/13 |
| Zero-Delay QKV Compression for Mitigating KV Cache and Network Bottlenecks in LLM Inference Zeyu Zhang,Haiying Shen |
 |
Paper | [//]: #08/09 |
| Finch: Prompt-guided Key-Value Cache Compression Giulio Corallo, Paolo Papotti |
 |
Paper | [//]: #08/08 |
 Palu: Compressing KV-Cache with Low-Rank Projection Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Kai-Chiang Wu |
 |
Github Paper |
[//]: #08/08 |
| ThinK: Thinner Key Cache by Query-Driven Pruning Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Aojun Zhou, Amrita Saha, Caiming Xiong, Doyen Sahoo |
 |
Paper | [//]: #08/08 |
| RazorAttention: Efficient KV Cache Compression Through Retrieval Heads Hanlin Tang, Yang Lin, Jing Lin, Qingsen Han, Shikuan Hong, Yiwu Yao, Gongyi Wang |
 |
Paper | [//]: #07/24 |
| PQCache: Product Quantization-based KVCache for Long Context LLM Inference Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, Bin Cui |
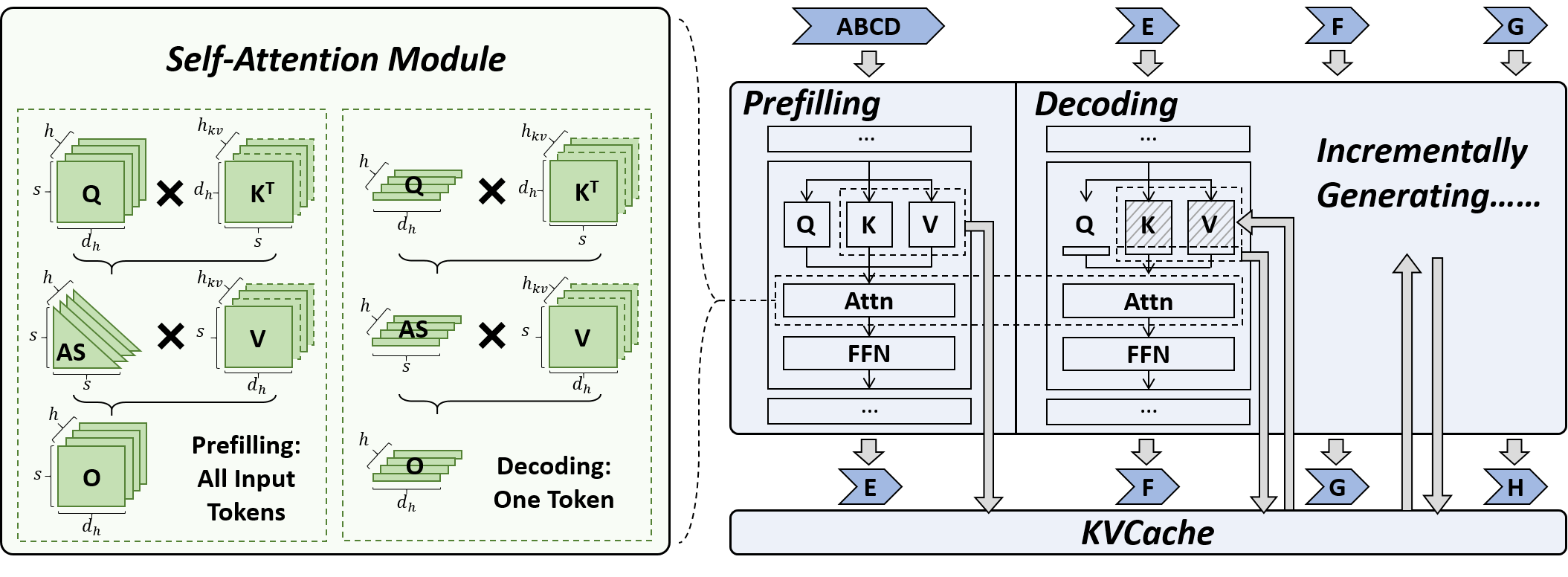 |
Paper | [//]: #07/21 |
 GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression Daniel Goldstein, Fares Obeid, Eric Alcaide, Guangyu Song, Eugene Cheah |
 |
Text Compression
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 [ [:star: LLMLingua: Compressing Prompts for Accelerated Inference of Large Language Models Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, Lili Qiu |
 |
Github Paper |
[//]: #Recommend |
:star: LongLLMLingua: Accelerating and Enhancing LLMs in Long Context Scenarios via Prompt Compression Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu |
 |
Github Paper |
[//]: #Recommend |
| [ Selection-p: Self-Supervised Task-Agnostic Prompt Compression for Faithfulness and Transferability Tsz Ting Chung, Leyang Cui, Lemao Liu, Xinting Huang, Shuming Shi, Dit-Yan Yeung |
 |
Paper | [//]: #10/21 |
| [ From Reading to Compressing: Exploring the Multi-document Reader for Prompt Compression Eunseong Choi, Sunkyung Lee, Minjin Choi, June Park, Jongwuk Lee |
 |
Paper | [//]: #10/14 |
| Perception Compressor:A training-free prompt compression method in long context scenarios Jiwei Tang, Jin Xu, Tingwei Lu, Hai Lin, Yiming Zhao, Hai-Tao Zheng |
 |
Paper | [//]: #10/02 |
 FineZip : Pushing the Limits of Large Language Models for Practical Lossless Text Compression Fazal Mittu, Yihuan Bu, Akshat Gupta, Ashok Devireddy, Alp Eren Ozdarendeli, Anant Singh, Gopala Anumanchipalli |
 |
Github Paper |
[//]: #09/27 |
 Parse Trees Guided LLM Prompt Compression Wenhao Mao, Chengbin Hou, Tianyu Zhang, Xinyu Lin, Ke Tang, Hairong Lv |
 |
Github Paper |
[//]: #09/27 |
 AlphaZip: Neural Network-Enhanced Lossless Text Compression Swathi Shree Narashiman, Nitin Chandrachoodan |
 |
Github Paper |
[//]: #09/27 |
| TACO-RL: Task Aware Prompt Compression Optimization with Reinforcement Learning Shivam Shandilya, Menglin Xia, Supriyo Ghosh, Huiqiang Jiang, Jue Zhang, Qianhui Wu, Victor Rühle |
 |
Paper | [//]: #09/27 |
| Efficient LLM Context Distillation Rajesh Upadhayayaya, Zachary Smith, Chritopher Kottmyer, Manish Raj Osti |
Paper | [//]: #09/06 | |
 Enhancing and Accelerating Large Language Models via Instruction-Aware Contextual Compression Haowen Hou, Fei Ma, Binwen Bai, Xinxin Zhu, Fei Yu |
 |
Github Paper |
[//]: #09/02 |
 500xCompressor: Generalized Prompt Compression for Large Language Models Zongqian Li, Yixuan Su, Nigel Collier |
 |
Github Paper |
[//]: #08/08 |
 QUITO: Accelerating Long-Context Reasoning through Query-Guided Context Compression Wenshan Wang, Yihang Wang, Yixing Fan, Huaming Liao, Jiafeng Guo |
 |
Github Paper |
[//]: #08/08 |
| [ Characterizing Prompt Compression Methods for Long Context Inference Siddharth Jha, Lutfi Eren Erdogan, Sehoon Kim, Kurt Keutzer, Amir Gholami |
 |
Paper | [//]: #07/16 |
Low-Rank Decomposition
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 Natural GaLore: Accelerating GaLore for memory-efficient LLM Training and Fine-tuning Arijit Das |
Github Paper |
[//]: #10/30 | |
| CompAct: Compressed Activations for Memory-Efficient LLM Training Yara Shamshoum, Nitzan Hodos, Yuval Sieradzki, Assaf Schuster |
 |
Paper | [//]: #10/30 |
| [ ESPACE: Dimensionality Reduction of Activations for Model Compression Charbel Sakr, Brucek Khailany |
 |
Paper | [//]: #10/14 |
| MoDeGPT: Modular Decomposition for Large Language Model Compression Chi-Heng Lin, Shangqian Gao, James Seale Smith, Abhishek Patel, Shikhar Tuli, Yilin Shen, Hongxia Jin, Yen-Chang Hsu |
 |
Paper | [//]: #08/20 |
Hardware/System
| Title & Authors | Introduction | Links | |
|---|---|---|---|
| EPIC: Efficient Position-Independent Context Caching for Serving Large Language Models Junhao Hu, Wenrui Huang, Haoyi Wang, Weidong Wang, Tiancheng Hu, Qin Zhang, Hao Feng, Xusheng Chen, Yizhou Shan, Tao Xie |
 |
Paper | [//]: #10/30 |
| [ SDP4Bit: Toward 4-bit Communication Quantization in Sharded Data Parallelism for LLM Training Jinda Jia, Cong Xie, Hanlin Lu, Daoce Wang, Hao Feng, Chengming Zhang, Baixi Sun, Haibin Lin, Zhi Zhang, Xin Liu, Dingwen Tao |
 |
Paper | [//]: #10/30 |
| FastAttention: Extend FlashAttention2 to NPUs and Low-resource GPUs Haoran Lin, Xianzhi Yu, Kang Zhao, Lu Hou, Zongyuan Zhan et al |
 |
Paper | [//]: #10/29 |
| POD-Attention: Unlocking Full Prefill-Decode Overlap for Faster LLM Inference Aditya K Kamath, Ramya Prabhu, Jayashree Mohan, Simon Peter, Ramachandran Ramjee, Ashish Panwar |
 |
Paper | [//]: #10/29 |
 TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices Zonghang Li, Wenjiao Feng, Mohsen Guizani, Hongfang Yu |
 |
Github Paper |
[//]: #10/02 |
| [ Efficient Arbitrary Precision Acceleration for Large Language Models on GPU Tensor Cores Shaobo Ma, Chao Fang, Haikuo Shao, Zhongfeng Wang |
 |
Paper | [//]: #09/27 |
| [ OPAL: Outlier-Preserved Microscaling Quantization A ccelerator for Generative Large Language Models Jahyun Koo, Dahoon Park, Sangwoo Jung, Jaeha Kung |
 |
Paper | [//]: #09/13 |
| Accelerating Large Language Model Training with Hybrid GPU-based Compression Lang Xu, Quentin Anthony, Qinghua Zhou, Nawras Alnaasan, Radha R. Gulhane, Aamir Shafi, Hari Subramoni, Dhabaleswar K. Panda |
 |
Paper | [//]: #09/06 |
| LUT Tensor Core: Lookup Table Enables Efficient Low-Bit LLM Inference Acceleration Zhiwen Mo, Lei Wang, Jianyu Wei, Zhichen Zeng, Shijie Cao, Lingxiao Ma, Naifeng Jing, Ting Cao, Jilong Xue, Fan Yang, Mao Yang |
 |
Paper | [//]: #08/20 |
| Kraken: Inherently Parallel Transformers For Efficient Multi-Device Inference Rohan Baskar Prabhakar, Hengrui Zhang, David Wentzlaff |
 |
Paper | [//]: #08/20 |
| SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference Serving Andreas Kosmas Kakolyris, Dimosthenis Masouros, Petros Vavaroutsos, Sotirios Xydis, Dimitrios Soudris |
 |
Paper | [//]: #08/13 |
| Designing Efficient LLM Accelerators for Edge Devices Jude Haris, Rappy Saha, Wenhao Hu, José Cano |
 |
Paper | [//]: #08/08 |
| PipeInfer: Accelerating LLM Inference using Asynchronous Pipelined Speculation Branden Butler, Sixing Yu, Arya Mazaheri, Ali Jannesari |
 |
Paper | [//]: #07/21 |
Tuning
| Title & Authors | Introduction | Links | |
|---|---|---|---|
| [ MiLoRA: Efficient Mixture of Low-Rank Adaptation for Large Language Models Fine-tuning Jingfan Zhang, Yi Zhao, Dan Chen, Xing Tian, Huanran Zheng, Wei Zhu |
 |
Paper | [//]: #10/29 |
 RoCoFT: Efficient Finetuning of Large Language Models with Row-Column Updates Md Kowsher, Tara Esmaeilbeig, Chun-Nam Yu, Mojtaba Soltanalian, Niloofar Yousefi |
 |
Github Paper |
[//]: #10/21 |
 [ [Layer-wise Importance Matters: Less Memory for Better Performance in Parameter-efficient Fine-tuning of Large Language Models Kai Yao, Penlei Gao, Lichun Li, Yuan Zhao, Xiaofeng Wang, Wei Wang, Jianke Zhu |
 |
Github Paper |
[//]: #10/21 |
| [ Parameter-Efficient Fine-Tuning of Large Language Models using Semantic Knowledge Tuning Nusrat Jahan Prottasha, Asif Mahmud, Md. Shohanur Islam Sobuj, Prakash Bhat, Md Kowsher, Niloofar Yousefi, Ozlem Ozmen Garibay |
 |
Paper | [//]: #10/21 |
 [ [QEFT: Quantization for Efficient Fine-Tuning of LLMs Changhun Lee, Jun-gyu Jin, Younghyun Cho, Eunhyeok Park |
 |
Github Paper |
[//]: #10/21 |
 [ [BIPEFT: Budget-Guided Iterative Search for Parameter Efficient Fine-Tuning of Large Pretrained Language Models Aofei Chang, Jiaqi Wang, Han Liu, Parminder Bhatia, Cao Xiao, Ting Wang, Fenglong Ma |
 |
Github Paper |
[//]: #10/21 |
 SparseGrad: A Selective Method for Efficient Fine-tuning of MLP Layers Viktoriia Chekalina, Anna Rudenko, Gleb Mezentsev, Alexander Mikhalev, Alexander Panchenko, Ivan Oseledets |
 |
Github Paper |
[//]: #10/13 |
| SpaLLM: Unified Compressive Adaptation of Large Language Models with Sketching Tianyi Zhang, Junda Su, Oscar Wu, Zhaozhuo Xu, Anshumali Shrivastava |
 |
Paper | [//]: #10/13 |
 Bone: Block Affine Transformation as Parameter Efficient Fine-tuning Methods for Large Language Models Jiale Kang |
 |
Github Paper |
[//]: #09/27 |
| Enabling Resource-Efficient On-Device Fine-Tuning of LLMs Using Only Inference Engines Lei Gao, Amir Ziashahabi, Yue Niu, Salman Avestimehr, Murali Annavaram |
 |
Paper | [//]: #09/27 |
| Tensor Train Low-rank Approximation (TT-LoRA): Democratizing AI with Accelerated LLMs Afia Anjum, Maksim E. Eren, Ismael Boureima, Boian Alexandrov, Manish Bhattarai |
 |
Paper | [//]: #08/08 |
Survey
| Title & Authors | Introduction | Links | |
|---|---|---|---|
 Prompt Compression for Large Language Models: A Survey Zongqian Li, Yinhong Liu, Yixuan Su, Nigel Collier |
 |
Github Paper |
[//]: #10/21 |
| Large Language Model Inference Acceleration: A Comprehensive Hardware Perspective Jinhao Li, Jiaming Xu, Shan Huang, Yonghua Chen, Wen Li, Jun Liu, Yaoxiu Lian, Jiayi Pan, Li Ding, Hao Zhou, Guohao Dai |
 |
Paper | [//]: #10/14 |
| A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms Ruihao Gong, Yifu Ding, Zining Wang, Chengtao Lv, Xingyu Zheng, Jinyang Du, Haotong Qin, Jinyang Guo, Michele Magno, Xianglong Liu |
 |
Paper | [//]: #09/27 |
 Contextual Compression in Retrieval-Augmented Generation for Large Language Models: A Survey Sourav Verma |
 |
Github Paper |
[//]: #09/27 |
| Art and Science of Quantizing Large-Scale Models: A Comprehensive Overview Yanshu Wang, Tong Yang, Xiyan Liang, Guoan Wang, Hanning Lu, Xu Zhe, Yaoming Li, Li Weitao |
Paper | [//]: #09/21 | |
| Hardware Acceleration of LLMs: A comprehensive survey and comparison Nikoletta Koilia, Christoforos Kachris |
Paper | [//]: #09/06 | |
| A Survey on Symbolic Knowledge Distillation of Large Language Models Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song |
 |
Paper | [//]: #08/27 |
| [ Inference Optimization of Foundation Models on AI Accelerators Youngsuk Park, Kailash Budhathoki, Liangfu Chen, Jonas Kübler, Jiaji Huang, Matthäus Kleindessner, Jun Huan, Volkan Cevher, Yida Wang, George Karypis |
Paper | [//]: #07/16 |