 rwightman
commented
3 years ago
rwightman
commented
3 years ago @eliahuhorwitz looks like you are doing single node, single worker training so this isn't likely a concern, but you should be aware if you do distributed train, you should always confirm your validation results on a single node with the validation script afterwards, the distributed validation results will be a bit different due to padding of the batch, etc.
You can always double check the sanity of the bits and tpu results by using the same checkpoints and validating on a GPU with the the master branch, that is well tested.
For the official CIFAR training the vit authors used 98% of the train split https://github.com/google-research/vision_transformer/blob/main/vit_jax/configs/common.py#L93 ... unfortunately you can split 98 and then split again for multi-node train due to limitations in splitting up the samples for even distribution across distributed nodes right now.
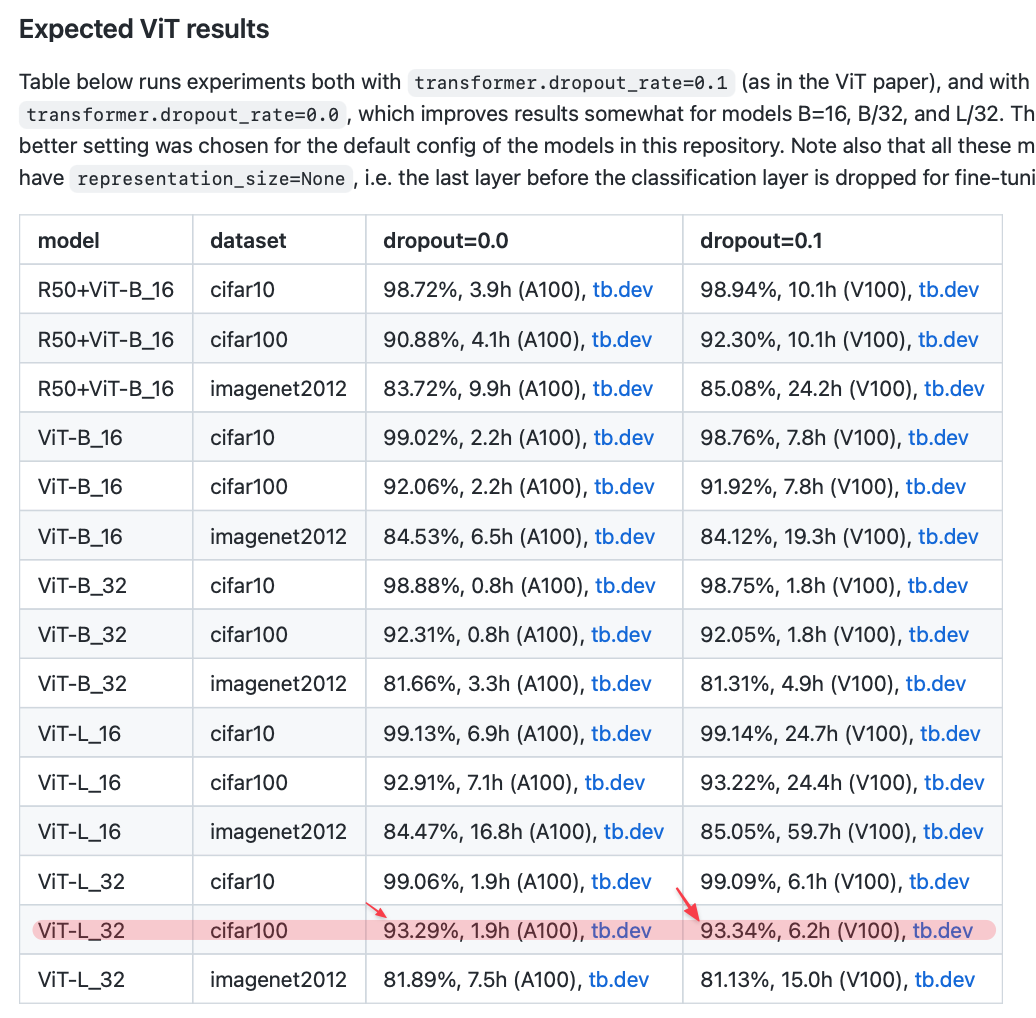
The other factor is that the default weights are the ImageNet-21k 300epoch variants from the 'How to train your ViT' paper, not the original, 94.1 is the CIFAR-100 result for that paper for L/16 and 93.2 for B/16, L32 wasn't used, but the R50+L/32 hybrid had 93.9. Augmentation was off for the transfer runs in that paper.
One of the main observations in that paper was that when pre-training with higher augmentation + regularization w/ vision transformers, the results roughly match using an order of magnitude more data ... so in1k -> 21k and 21k -> jft300m as compared to the original paper.. thus your resutls aren't that crazy.
 eliahuhorwitz
eliahuhorwitz
Hey, I've been finetuning ViT on different datasets (cifar100, oxford_pets, etc.). I am using Google TRC TPUs, specifically V3 VM using the bits_and_tpu branch. I have found the results of finetuning to be odd, specifically, on CIFAR100 I am seeing the eval top1 accuracy reaching 94.19 within 17 epochs (I even had 1 run get to 94.44), these numbers are closer to JFT300 results and not ImageNet21K results. From the original ViT paper below they get 93.04 on a similar setup to mine and from the google research github repo also attached below the get 93.29. Even more surprising to me is the fact I get the 94.x results when I turn off the image augmentations.
To try and ensure I didn't introduce a bug into the codebase, I cloned a new copy of the repo and performed tests aginst it. I start finetunning with:
python3 launch_xla.py --num-devices 1 finetune.py ~/tensorflow_datasets --dataset tfds/cifar100:3.0.2 --opt sgd --epochs 1000 --workers 1 --val-split test --mixup 0 --cutmix 0 --opt-eps=1e-08 --train-interpolation=bicubic --warmup-lr=1e-06 --lr 0.004 -b 128 --num-classes 100 --model vit_large_patch32_384and my finetune.py file is just a copy of the train script with a change in the way I create the mode, that is I comment out this
and instead put this
model = timm.create_model(args.model, pretrained=True, num_classes=args.num_classes)The full script is below:
Here is the summary of the above output (I stopped it once I saw it is too high)
And here is a graph of a similar run with slightly different hyperparams which I let run for longer (it reached 94.44!!!)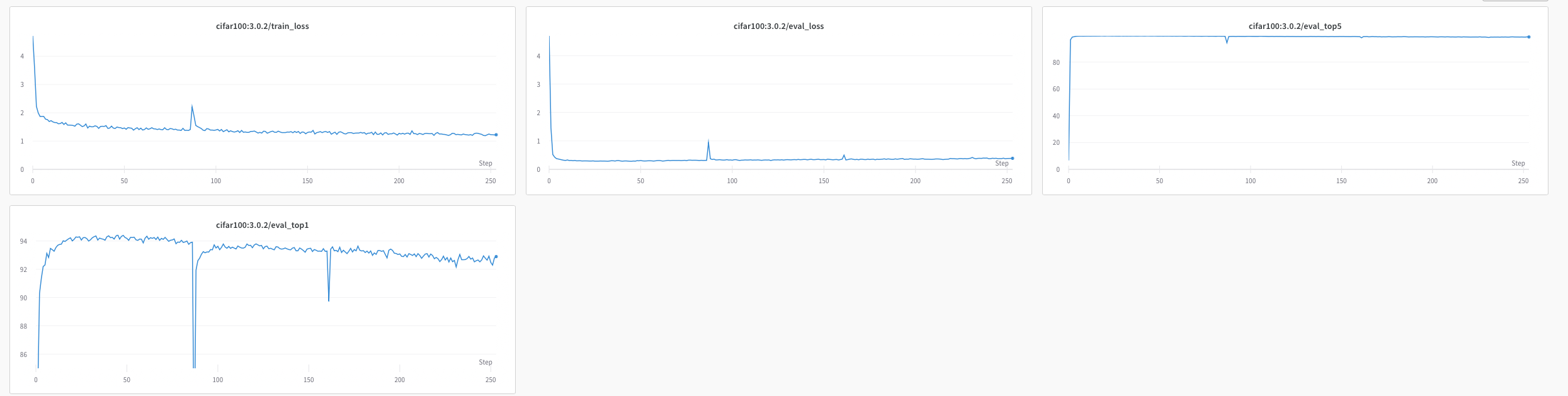
I've made sure to start a clean machine for this, with a fresh download of cifar100 from TFDS, and of course, a fresh clone of the codebase.
The above results also make me completely doubt the results I have been getting for my own models that use this codebase/pretrained models. I am working now on trying to reproduce this on a GPU, but I don't have access to the same amount of compute so this is going to be more challenging.
Am I somehow missing something or doing something wrong in the fine-tuning script? Could these be real results? Or do you think there is some bug in the XLA/TPU side of things?
Do you have any recommendations as to where should I start looking for a solution?
Thanks, Eliahu