Hypertrace Service
Hypertrace service combines hypertrace-ui, hypertrace-graphql, gateway-service, attribute-service, query-service, entity-service into single service. This is used in Hypertrace standalone deployment to make the deployment compact and use less resource.
How this works?
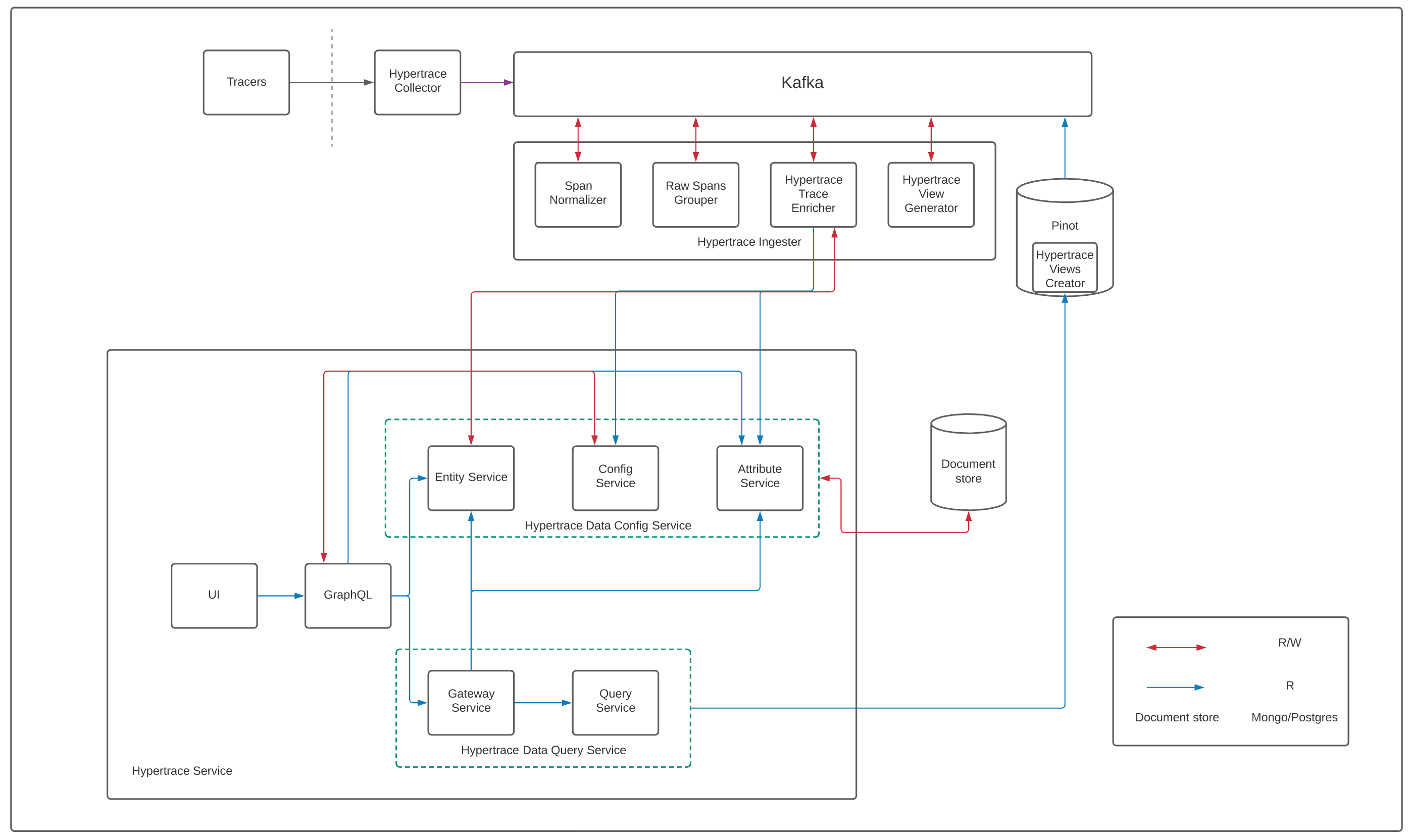 |
|---|
| Hypertrace Architecture |
hypertrace-UI talks to hypertrace-GraphQL service which serves the GraphQL API which queries data from downstream services. GraphQL services talks to different grpc services to form the response.
Attribute service fetches all attributes relevant to the scope of what is being shown on UI from document store, where it also stores attributes. All of this metadata assists the UI and backend to perform things in a generic fashion, like
- All String attributes in the UI can have a different look and feel and also different operations that can be supported on them(in the explorer).
- The backend also uses part of the information(like the sources) to figure out where to fetch data from i.e. query-service vs entity-service.
While hypertrace offers a simple service model, it also permits storing certain fields in different backends. Attributes include tags to help locate the service hosting their corresponding data.
Ex.
key: apiName,
value_kind: TYPE_STRING,
groupable : true,
display_name: Endpoint Name,
scope: API_TRACE,
sources: [QS],
type: ATTRIBUTEFor example, apiName is generated from raw trace data streams. sources: [QS] communicates this, as Query Service is the api that queries that data (via Pinot).
Gateway service routes queries to corresponding downstream service based on the source of attributes and then does appropriate type conversion of data returned by downstream services. Gateway service talks to Attribute service to find where to forward the request. Here Query service interfares with Apache Pinot datastore Whereas Entity service here provides CRUD operations for raw or enriched entities, for its types, and their relations.
So if we query UI to search for trace with particular traceID using query like below
curl -s localhost:2020/graphql -H 'Content-Type: application/graphql' -d \
'{
traces(
type: API_TRACE
between: {
startTime: "2015-01-01T00:00:00.000Z"
endTime: "2025-01-01T00:00:00.000Z"
}
filterBy: [
{
operator: EQUALS
value: "348bae39282251a5"
type: ID
idType: API_TRACE
}
]
) {
total
}
}'
What it will do is it will send this to Gateway service which will forward this to query service and Query service will check if this traceID is present in rawTraceView if it's there it will return 1 or will return 0.
Recently added config service is a place to store configuration data such as user preferences, saved query filters, ingestion config, etc. Many of these use cases have not yet been built out. In general, this service is meant for user-managed configuration that needs to be persisted, and contains support for version history, auditing etc. In the past, we've addressed such things by spinning up individual services (such as attribute service). As new features get built out, we want to avoid that (and eventually to merge older services back into this).
Hypertrace-data-config-service, is designed to be a single macro-service, with separate modules defining different GRPC services that expose feature-specific APIs whereas Hypertrace-data-query-service, is another macro-service that interferes with Pinot to fetch the data. The query and config logical group separation you see in the architecture is a step towards the next iteration of architecture where you will see 3 logical groups namely, ingestion, config, and Query layers.
Building locally
The Hypertrace service uses gradlew to compile/install/distribute. Gradle wrapper is already part of the source code. To build Hypertrace Service, run:
./gradlew clean build dockerBuildImagesTesting image
To test your image using the docker-compose setup follow the steps:
- Commit you changes to a branch say
hypertrace-service-test. - Go to hypertrace-service and checkout the above branch in the submodule.
cd hypertrace-service && git checkout hypertrace-service-test && cd .. - Change tag for
hypertrace-servicefrom:mainto:testin docker-compose file like this.
hypertrace-service:
image: hypertrace/hypertrace-service:test
container_name: hypertrace-service
...- and then run
docker-compose upto test the setup.