How Well Does GPT-4V(ision) Adapt to Distribution Shifts? A Preliminary Investigation
![]()
![]()
Code for the Paper "How Well Does GPT-4V(ision) Adapt to Distribution Shifts? A Preliminary Investigation".
💥 News 💥
- [2024.03.05] Our paper is accepted by ICLR 2024 Workshop on Mathematical and Empirical Understanding of Foundation Models
- [2024.01.16] Our code repository supports the evaluation for Gemini Pro Vision.
- [2023.12.14] An extensive collection of benchmark test cases, totaling 23.4k across 13 datasets, is now public 🤗 Hugging Face.
- [2023.12.13] Thrilled to see that our gpt-4v-distribution-shift paper has been featured by AK on Daily Papers page.
- [2023.12.13] Our gpt-4v-distribution-shift paper has been accessible at https://arxiv.org/pdf/2312.07424.pdf.
🐙 Requirements
- Clone this repository and navigate to the project directory
git clone git@github.com:jameszhou-gl/gpt-4v-distribution-shift.git
cd gpt-4v-distribution-shift- Create a Conda environment and activate it
conda create -n gpt-4v-distribution-shift python==3.10.13 -y
conda activate gpt-4v-distribution-shift
pip install --upgrade pip- Navigate to the LLaVA directory and install its dependencies
cd LLaVA
pip install -e .- Return to the project root directory and install its dependencies
cd gpt-4v-distribution-shift
pip install -e .⚠️ Prepare Dataset ⚠️
Download the datasets
follow the instructions for preparing the datasets
After downloading camelyon17_v1.0 and fmow_v1.1, run the following code snippet to convert the file structures similar to PACS and VLCS.
python ./data/process_wilds.pySupported Datasets
Currently, the project supports the following 13 datasets (See detail here):
- PACS
- VLCS
- office_home
- domain_net
- camelyon17_v1.0
- fmow_v1.1
- terra_incognita
- iwildcam_v2.0
- HAM10000
- NIH_Chest_X_ray_14
- drugood_assay
- drugood_scaffold
- Xray(COVID)
Construct and Maintain a JSON File Storing Metadata for Each Dataset
Maintain a dataset_info.json file in the ./data directory with metadata for each dataset:
Example for PACS:
{
"PACS": {
"domains": ["art_painting", "cartoon", "photo", "sketch"],
"class_names": ["dog", "giraffe", "horse", "person", "guitar", "elephant", "house"],
"subject": "nature"
}
}:hammer_and_wrench: Evaluation Pipeline
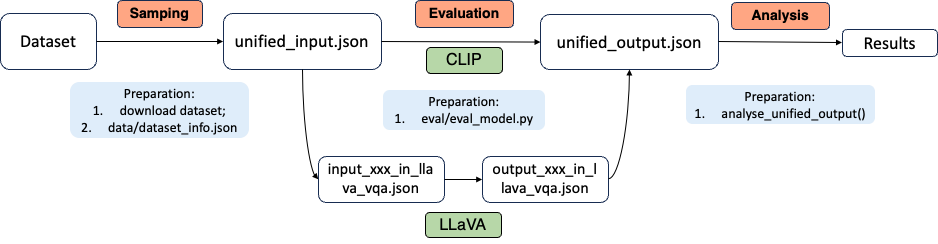
Our evaluation pipeline is designed with two key considerations in mind:
- Diverse Dataset and Domain Evaluation: We evaluate GPT-4V across a wide range of datasets and domains. This necessitates a preprocessing step to transform raw dataset data into formats suitable for input to the models.
- Varied Model Input and Output Formats: The three models under evaluation—GPT-4V, CLIP, and LLaVA—each require and produce different input and output formats, respectively.
Example Evaluation Workflow
To illustrate our pipeline, let’s consider an example where we evaluate both the CLIP and LLaVA models on the VLCS dataset. You can find the details of this example in our repository.
The pipeline is depicted in the following diagram:
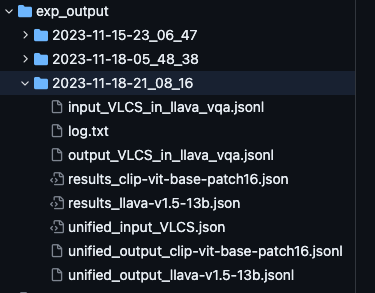
Evaluating CLIP Model on VLCS Dataset
First, we evaluate the CLIP model on the VLCS dataset using the following command:
python ./evaluation/eval_clip.py --dataset VLCS --num_sample 50During this process, the following files are generated in sequence:
unified_input_VLCS.json: The preprocessed input data for the VLCS dataset.unified_output_clip-vit-base-pathc16.jsonl: The output from the CLIP model.results_clip-vit-base-pathc16.json: The summarized results and analysis.
Evaluating LLaVA Model
Next, we continue with the evaluation of the LLaVA model, building upon the results from the CLIP model:
# Evaluate LLaVA based on the previous CLIP evaluation
CUDA_VISIBLE_DEVICES=0,1 python ./evaluation/eval_llava.py --dataset PACS --continue_dir=exp_output/2023-11-18-21_08_16This step results in the creation of the following files, in order:
input_VLCS_in_llava_vqa.jsonl: Input data for LLaVA in its expected vqa format.output_VLCS_in_llava_vqa.jsonl: LLaVA's output data.unified_llava-v1.5-13b.jsonandresults_llava-v1.5-13.json: Detailed results and analysis for the LLaVA model.
To review the detailed outcomes of each model, refer to the respective results_model_name.json files (e.g., results_llava-v1.5-13.json).
🤖 Evaluation
To conduct the evaluation, follow these steps:
Evaluating with CLIP
To evaluate the CLIP model on the PACS and VLCS datasets:
python ./evaluation/eval_clip.py --dataset PACS VLCS --num_sample 50This command evaluates the CLIP model on both PACS and VLCS datasets, processing 50 samples from each.
Evaluating with LLaVA-v1.5-13b
To evaluate the LLaVA model (the exact model loaded can be found parser.add_argument('--model_name', 'type'='str', 'choices'=['llava-v1.5-7b', 'llava-v1.5-13b'], 'default'="llava-v1.5-13b")):
CUDA_VISIBLE_DEVICES=0,1 python ./evaluation/eval_llava.py --num_sample 1This command evaluates the LLaVA model, limiting the evaluation to 1 sample per dataset.
Continuation Evaluation with LLaVA Based on CLIP
To continue the evaluation with LLaVA based on the samples selected from CLIP:
CUDA_VISIBLE_DEVICES=0,1 python ./evaluation/eval_llava.py --dataset PACS --continue_dir=<path_to_clip_results>Replace <path_to_clip_results> with the directory path where the CLIP results are stored. This command continues the LLaVA evaluation using the CLIP model's results as a starting point, for a quick and fair comparion between two models.
Evaluating with gpt-4-vision-preview
export OPENAI_API_KEY="your-openai-api-key"
python evaluation/eval_gpt-4v.py --num_sample 1The outpur directory example can be find in the repository:
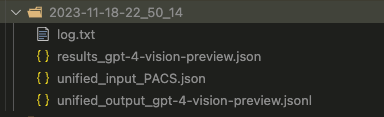
Comprehensive Evaluation Example for Three Models on a Specific Dataset
This example demonstrates how to conduct a complete evaluation of three different models (CLIP, LLaVA, and GPT-4V) on the PACS dataset. Follow these steps to replicate the evaluation process:
Step 1: Evaluate the CLIP Model and LLaVA Model
- First, run the evaluation for the CLIP model. This step will generate and save random samples (named PACS) in the specified output directory.
- Next, evaluate the LLaVA model using the samples generated from the CLIP model evaluation. Set the
--continue_dirargument to the output directory in CLIP.
We run bash evaluation/clip_llava_eval_pipeline.sh
Use clip_llava_eval_pipeline.sh
#!/bin/bash
# ! Specify the dataset and the number of samples
dataset="PACS"
num_sample=80 # 20 in default
# Get the current timestamp
current_time=$(date +"%Y-%m-%d-%H_%M_%S")
# Define the base output directory
base_output_dir="./exp_output"
timestamped_output_dir="${base_output_dir}/${current_time}"
# Create the timestamped output directory
mkdir -p "$timestamped_output_dir"
# Copy the bash script to the new output directory
cp ./evaluation/clip_llava_eval_pipeline.sh "$timestamped_output_dir"
# Run the CLIP evaluation script with the new output directory
python ./evaluation/eval_clip.py --dataset $dataset --output_dir "$timestamped_output_dir" --num_sample $num_sample --save_samples
# Evaluate LLaVA model using CLIP's samples
CUDA_VISIBLE_DEVICES=0,1 python ./evaluation/eval_llava.py --dataset $dataset --continue_dir="$timestamped_output_dir"Step 2: Evaluate the GPT-4V Model in Two Scenarios
Finally, evaluate the GPT-4V model based on two criteria:
-
Failure Cases in CLIP: Evaluate GPT-4V on the cases where the CLIP model failed.
randomly choose NUM_FAILURE failure samples in CLIP
-
Random Samples: Evaluate GPT-4V on random samples saved in
exp_output/2023-11-22-19_18_50.
randomly choose NUM_RAND samples in from random samples in CLIP
Note that we split the total 1800 cases into four parts due to current rate limit as 500 RPD in OpenAI API.
We run bash evaluation/gpt-4v_eval_pipeline.sh using gpt-4v_eval_pipeline.sh:
#!/bin/bash
# This script runs the GPT-4V evaluation pipeline. It prepares the evaluation,
# then runs the GPT-4V scenario runner with different scenarios and API keys.
# ! Specify
# Directory where the output of the CLIP and LLaVA models is stored
CONTINUE_DIR="exp_output/2023-11-22-19_18_50"
# Number of random and failure cases to prepare for GPT-4V evaluation
NUM_RAND=1800 # 1800 in default
NUM_FAILURE=180 # 180 in default
# Copy the bash script to the new output directory
cp evaluation/gpt-4v_eval_pipeline.sh "$CONTINUE_DIR"
# Prepare the GPT-4V evaluation dataset
echo "Preparing GPT-4V evaluation dataset..."
python evaluation/prepare_gpt4v_evaluation.py --num_rand $NUM_RAND --num_failure $NUM_FAILURE --continue_dir $CONTINUE_DIR
# Run GPT-4V evaluation for different scenarios
# Scenario 1: Failure cases, Part 1
echo "Running GPT-4V evaluation for Failure Scenario 1..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name failure_1 --openai_api_key your-openai-api-key
# Scenario 2: Failure cases, Part 2
echo "Running GPT-4V evaluation for Failure Scenario 2..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name failure_2 --openai_api_key your-openai-api-key
# Scenario 1: Random cases, Part 1
echo "Running GPT-4V evaluation for Random Scenario 1..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_1 --openai_api_key your-openai-api-key
# Scenario 2: Random cases, Part 2
echo "Running GPT-4V evaluation for Random Scenario 2..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_2 --openai_api_key your-openai-api-key
# Scenario 3: Random cases, Part 3
echo "Running GPT-4V evaluation for Random Scenario 3..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_3 --openai_api_key your-openai-api-key
# Scenario 4: Random cases, Part 4
echo "Running GPT-4V evaluation for Random Scenario 4..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_4 --openai_api_key your-openai-api-key
echo "GPT-4V evaluation pipeline completed."
After the above bash job is completed, you would find the results_model-name_failure.json and results_model-name_random.json for each of clip, llava, gpt-4v.
Step 3: Evaluate the Gemini Pro Vision Model in Two Scenarios
We evaluate the Gemini model based on two criteria:
-
Failure Cases in CLIP: Evaluate Gemini Pro Vision on the cases where the CLIP model failed, i.e., saved in
./exp_output/2023-11-22-22_21_35. -
Random Samples: Evaluate Gemini Pro Vision on random samples, i.e., saved in
./exp_output/2023-11-22-19_18_50.
We run bash evaluation/gemini_eval_pipeline.sh using gemini_eval_pipeline.sh:
😈 Reproduce Table 1 and 2 in the paper
Recognizing the continuous evolution of multimodal foundation models, such as Gemini, we make our random test cases public in huggingface repository, as a benchmark for evaluating and tracking the adaptability of SOTA foundation models to distribution shifts.
Here, we present how to reproduce the gpt-4v on the specific random sample sets.
#!/bin/bash
# This script runs the GPT-4V evaluation pipeline. It prepares the evaluation,
# then runs the GPT-4V scenario runner with different scenarios and API keys.
# ! Specify
# Directory where the output of the CLIP and LLaVA models is stored
CONTINUE_DIR="your-path-for-hugginface-gpt-4v-distribution-shift-PACS"
# Scenario 1: Random cases, Part 1
echo "Running GPT-4V evaluation for Random Scenario 1..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_1 --openai_api_key your-openai-api-key
# Scenario 2: Random cases, Part 2
echo "Running GPT-4V evaluation for Random Scenario 2..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_2 --openai_api_key your-openai-api-key
# Scenario 3: Random cases, Part 3
echo "Running GPT-4V evaluation for Random Scenario 3..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_3 --openai_api_key your-openai-api-key
# Scenario 4: Random cases, Part 4
echo "Running GPT-4V evaluation for Random Scenario 4..."
python evaluation/gpt-4v_scenario_runner.py --continue_dir $CONTINUE_DIR --scenario_name random_4 --openai_api_key your-openai-api-key
echo "GPT-4V evaluation pipeline completed.":white_check_mark: Citation
If you find our work useful in your research, please consider citing:
@misc{han2023does,
title={How Well Does GPT-4V(ision) Adapt to Distribution Shifts? A Preliminary Investigation},
author={Zhongyi Han and Guanglin Zhou and Rundong He and Jindong Wang and Tailin Wu and Yilong Yin and Salman Khan and Lina Yao and Tongliang Liu and Kun Zhang},
year={2023},
eprint={2312.07424},
archivePrefix={arXiv},
primaryClass={cs.LG}
}