 jdimeo
commented
1 year ago
jdimeo
commented
1 year ago So we went "all in" on the "disaggregated" approach, which is both way more powerful but way less literate than the path you are on. Not saying one is better or worse, but ours facilitates a lot of modularity and re-use (at the expense of a top to bottom file as you describe). Here are some examples (totally fake, our real use case is Child Development Monitoring & Evaluation)
We have separate YAML files for response scales:
---
values:
- value: 0
label:
key: min
en-US: Incorrect
sw-TZ: Kosa
id-ID: Salah
- value: 1
label:
key: max
en-US: Correct
sw-TZ: Sahihi
id-ID: Benar(note the ability to translate/localize the survey- we bidirectionally integrate with https://tolgee.io/)
which can then be included in other scales:
---
include:
- "incorrect-correct"
values:
- value: 2
label:
key: notask
en-US: Did not ask
sw-TZ: "Je, si kuuliza"
id-ID: Tidak bertanyaOr variables, in entirety, mix n' match, or even "merged" (using numeric values or keys to override values).
id: travel_enjoyment
type: Input
name:
en-US: Travel enjoyment
definition:
prompt:
en-US: How often do you travel?
en-GB: How often do you go on holiday? # Contextualized English a form of "translation"
scale:
include:
- "all-most-some-no-time" # Included scale from the scale libraryA key concept in our framework is variants. So you can adjust the wording or the response scale for young kids vs. old kids vs. caregivers or by country (or other ways). This is also the way we capture relevance or skip logic... under a dynamic condition, disable this variable or groups of variables. Here's an example of a consent question that is worded for use with an enumerator/interviewer, but uses a variant to override the prompt if the given survey is for "Self-enumeration" - the respondent is using the tablet themselves.
---
id: base_consent
aliases:
- "intro_informed_conse"
- "verbal_consent"
type: Input
dataType: Binary
name:
en-US: Informed Consent
definition:
prompt:
en-US: >
Do you agree to participating in this interview and to share this information?
notes:
en-US: >
If the response is yes, continue with the survey. If the response is no, finalize and exit the survey.
scale:
include:
- "no-yes"
variants:
- for: Self-Enumeration
override:
prompt:
en-US: Are you willing to complete the survey?or an example of the dynamic variant and/or skip condition:
variants:
- when: travel_enjoyment.value != travel_enjoyment.scale.min # Not "none" - the scale option with key "min". Could also have done > 0
override:
enabled: falseand then you can pull this all together into a survey YAML:
id: helloworld
name: Hello World
blocks:
- prompt:
en-US: >
This is a demonstration using a simple survey
- name:
en-US: Hello World block
elements:
- variable: base_consent
- variable: hw_name
- variable: hw_age
- variable: travel_enjoymentWhich again allows you to refer to and re-use variables across multiple surveys. So you can generate a whole "grid" of surveys- with an interviewer, for self-enumeration, for young kids/old kids, etc. which creates XLSForms which then load into Data Collection platforms and then we use their REST APIs to pipe the data back to our data warehouse.
I do strongly recommend using someone else's backend because of things like localization/language support, offline collection, case management, security, etc. So much more to discuss/share!
(note that Markdown is supported in all the en-US and other language bits... not shown in my examples, but the "down" part is still there ;-))
 jhelvy
jhelvy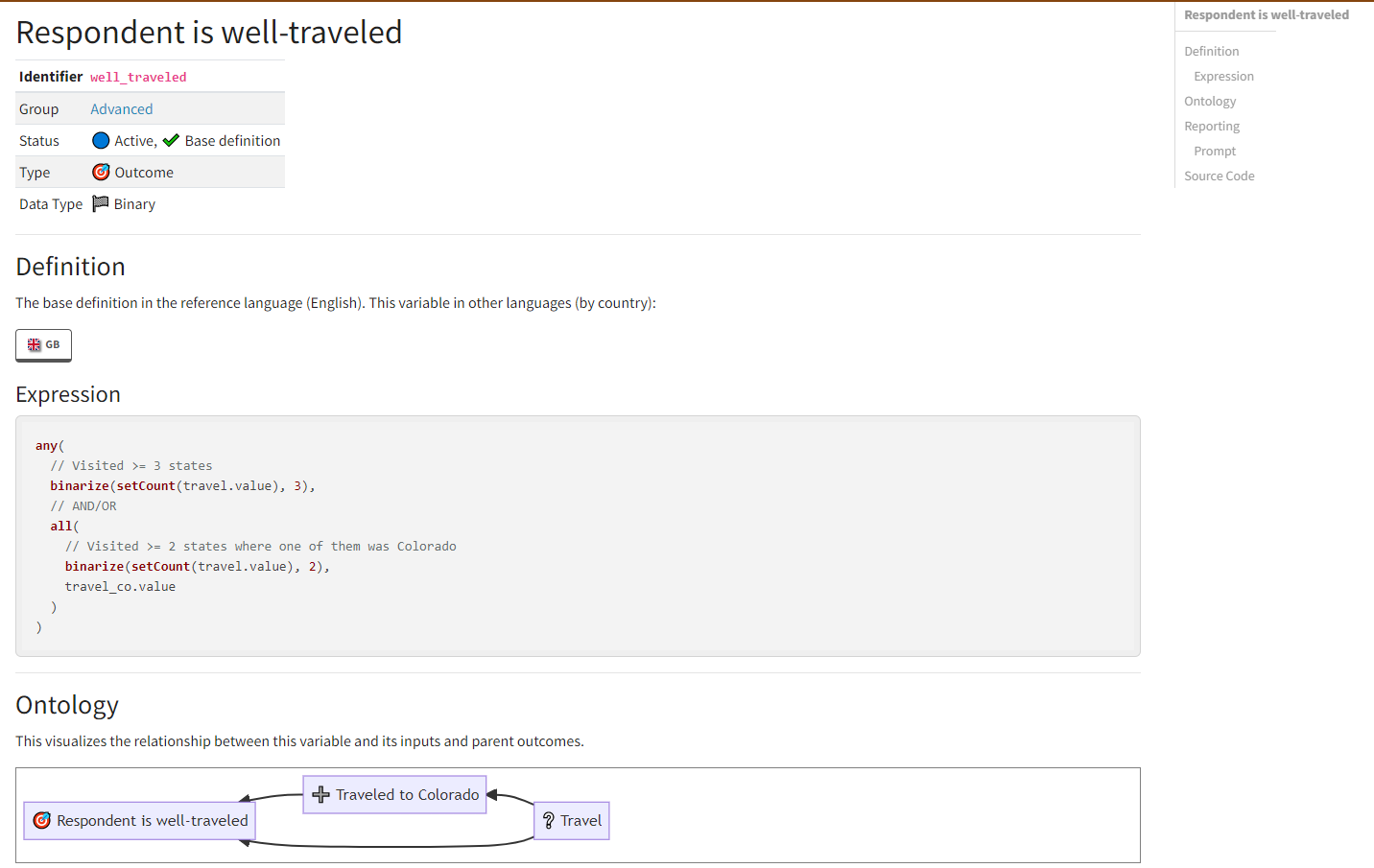

In building out this package, I am considering two quite different frameworks. This issue discusses them both.
Option 1
This is the original framework discussed in my blog post. It is a "disaggregated" framework in that the survey is defined by multiple Rmd / qmd files that are linked together with a
_survey.ymlfile, and the survey questions are all defined in a_questions.ymlfile. A functioning prototype built on {shinysurveys} is available in this repo here.Some benefits of this framework are that some of the "high-level" survey design elements are easily visible. For example, the overall survey flow logic is clear and easy to modify by just editing the
_survey.ymlfile. Likewise, the survey questions are all centralized in the_questions.ymlfile, making them equally easy to quickly view and modify.A downside to this framework is that the user has to open and edit multiple different files to get a fully-functioning survey. It is also not clear how the user might preview the rendered survey (other than simply compiling the survey and taking it themselves). Perhaps a
preview()function could be made, or perhaps in the_survey.ymlfile there could be other elements that control things like having the survey in"preview"mode, as well as other global options, like CSS, themes, etc. This could be similar to how Quarto / RMarkdown websites work.Option 2
In this option, the entire survey would be designed in a single .qmd file (I'm using Quarto over RMarkdown as a default for now). An example of this framework can be seen in this repo here, though this one is not yet functioning. In this framework, the .qmd file feels much more like editing a xaringan or Quarto presentation file in that all of the content is there in a single file. Questions could be defined here in code chunks using a simple function, e.g.
q(), that take all the same arguments that would otherwise be defined in the_questions.ymlfile in option 1. Survey control logic could be defined using options just after the---page breaks. For example, askipoption could be put in place to allow control over skipping.This framework has the nice benefit of being able to edit and preview the entire survey from one place. There are fewer files, and the integration between markdown and code feels tighter. A simple yaml at the top of this file could also allow the user to specify global options like CSS, themes, etc. The ability to define questions in code chunks is also useful. For example, if the user wanted a
selecttype question and wanted to include a series of values as options, they could define that series using R code, e.g.1900:2023(for "year of birth"). This could potentially be done in Option 1 too in the_questions.ymlfile if we allow for in-line code, e.g.`r 1900:2023`. But in general it feels like there would be more flexibility in defining the questions with this framework, such as the ability to read in an external file to define options.A downside to this framework is that the handling of the survey control logic and the questions themselves are a little clumsy. It isn't as clearly obvious how and where things like skipping questions are being done as the user has to parse through the file looking for a
skipoption, and they also have to remember to set names for the pages that are involved in skipping, etc.Discussion
Maybe there is a compromise between these two. I still in general prefer Option 1 as it feels easier to separate out the design of the different survey elements:
Every survey has at least these 3 elements, and being able to separately define each feels convenient. The issue of previewing the results could probably be handled by just making a function, e.g.
surveydown::preview(). Apageargument could allow the preview to start at a given location in the survey,surveydown::preview(page = 'screener').The main aspect I would want improved in this framework is to allow more flexibility in how question options are defined in
_questions.yml. The inclusion of in-line code for options is a big step in the right direction here.Another aspect that would need to be added is adding more options in the
_survey.ymlfile. For example, some overall global options could be added along side the control logic, something like this: