F5-TTS-api
这是用于 F5-TTS 项目的api和webui封装
F5-TTS是由上海交通大学开源的一款基于流匹配的全非自回归文本到语音转换系统(Text-to-Speech,TTS)。它以其高效、自然和多语言支持的特点脱颖而出
功能
- 提供api接口文件
api.py,可对接于视频翻译项目 pyvideotrans - 提供webui界面,可在浏览器中进行声音克隆
- 提供windows下整合包
整合包部署5G(包含f5-tts模型及环境)
整合包下载地址 123 网盘地址: https://www.123684.com/s/03Sxjv-kKjB3
整合包仅可用于 Windows10/11, 下载后解压即用
-
启动Api服务: 双击
run-api.bat,接口地址是http://127.0.0.1:5010/api -
启动webui服务:双击
run-webui.bat, 启动成功后,请手动打开浏览器页面http://127.0.0.1:7860.
整合包默认使用 cuda11.8版本,若有英伟达显卡,并且已安装配置好CUDA/cuDNN环境,将自动使用GPU加速
源码部署
-
需要提前安装
python3.10git -
克隆这个仓库:
git clone https://github.com/jianchang512/f5-tts-api
cd f5-tts - 创建虚拟环境
python -m venv venvwindows下执行命令激活环境 .\venv\scripts\activate
Mac/Linux下执行命令激活环境 . venv/bin/activate
-
安装依赖:
pip install -r requirements.txt -
启动api服务:
python api.py,接口地址是http://127.0.0.1:5010/api -
启动webui服务
python webui.py,在浏览器中打开http://127.0.0.1:7860.
使用注意/代理VPN
- 模型需要从
huggingface.co网站在线下载,该站点无法在国内访问,请提前开启系统代理或全局代理,否则模型会下载失败
在视频翻译软件中使用
- 启动api服务
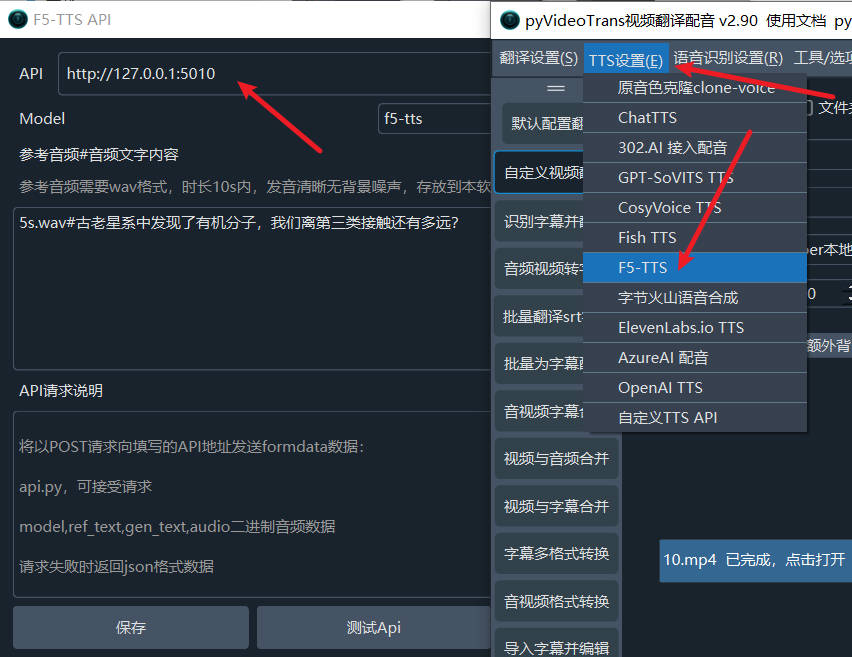
- 打开视频翻译软件,找到菜单-TTS设置-F5-TTS,填写api地址,如果未修改过地址,填写
http://127.0.0.1:5010 - 填写参考音频和音频内文本
API 使用示例
import requests
res=requests.post('http://127.0.0.1:5010/api',data={
"ref_text": '这里填写 1.wav 中对应的文字内容',
"gen_text": '''这里填写要生成的文本。''',
"model": 'f5-tts'
},files={"audio":open('./1.wav','rb')})
if res.status_code!=200:
print(res.text)
exit()
with open("ceshi.wav",'wb') as f:
f.write(res.content)