
![]()
![]()
![]()
Tabla de contenidos
- Descripción de la aplicación
- Arquitectura
- Desarrollo
- Descripción del microservicio (Nuevo versión 5.0)
- Descripción de la arquitectura de la aplicación
- Despliegue de la aplicación en PaaS
- Despliegue de la infraestructura en máquina local
- Despliegue de la infraestructura y aprovisionamiento en azure
- Comprobaciones de aprovisionamiento del hito3
- Creación automática de una máquina virtual en Azure
- Orquestación de 2 máquinas virtuales con Vagrant en azure
- Comprobaciones del hito 5
- Contenedores docker (NUEVO versión 6.0)
Novedades
- Versión 2.0 (15/11/2018): Desarrollo del hito número 2 de la asignatura de cloud computing. Documentación generada.
-
Versión 3.0 (04/12/2018): Incluye desarrollo del microservicio de tareas y el desarrollo del hito número 3 de la asignatura de cloud computing. Documentación generada.
-
Versión 4.0 (18/12/2018): Incluye reimplementación total del servicio web de usuarios, y añade token de acceso y cifrado de las contraseñas. Documentación generada.
-
Versión 5.0 (17/01/2019): Incluye composición de microservicios. Microservicio de tareas utiliza microservicio de usuarios. Documentación generada.
-
Versión 6.0 (NUEVO versión 6.0) (25/01/2019): Incluye el lanzamiento de forma automatizada de los microservicios utilizando tápers docker tanto de forma local como en azure. Documentación generada
Contenedor: http://40.118.150.169/
Dockerhub: https://hub.docker.com/r/jmv74211/user_service
Despliegue Vagrant: 23.97.133.230
Descripción de la aplicación
Smartage va a ser un servicio web que permitirá a los usuarios realizar un seguimiento de su trabajo, a la vez que puedan planificar y repartir nuevas tareas de forma equitativa en un plazo determinado. Dicho servicio constará de las siguientes funcionalidades:
-
Agenda de trabajo: Permite añadir tareas realizadas con un esfuerzo y coste estimado. Por ejemplo (ejemplo real).
"Un hombre encargado de gestionar los regadíos de unos campos necesita saber: qué campos ha regado, qué días y cuántas horas ha dedicado en cada uno ellos para llevar un seguimiento de su trabajo y saber cuánto tiene que cobrar a cada uno de ellos mes a mes."
Esta funcionalidad estaría enfocada a este tipo de contexto, el usuario podrá crear una o varias secciones de trabajo e introducir registros cada vez que realice una tarea, indicando la fecha, concepto y número de horas realizadas. Finalmente, el servicio mostrará dicha información clasificada por mes y aportará distintos datos de interés.
-
Programación de tareas: Permite añadir nuevas tareas a realizar con una fecha límite y esfuerzo estimado, y el servicio propondrá una distribución de dicha tarea de forma parcial a lo largo del calendario.
-
Calendario: Permite visualizar la distribución de las tareas a lo largo del calendario.
-
Trabajo diario: Muestra las tareas del usuario que se proponen a realizar en el día actual.
Arquitectura
La arquitectura de la aplicación se basa en un arquitectura de microservicios. Cada funcionalidad anteriormente descrita, se desarrollará como un microservicio independiente. Los microservicios previstos a desarrollar son los siguientes:
- Microservicio de gestión de usuarios: Registro y acceso.
- Microservicio de programación de agenda de trabajo.
- Microservicio de programación de tareas.
- Microservicio de calendario.
- Microservicio de trabajo diario.
La estructura del servicio se basará en una aplicación que hará de gestor y se encargará de llamar a los diferentes microservicios cada vez que se necesiten.
Desarrollo
El conjunto de microservicios se van a desarrollar utilizando las siguientes teconologías:
-
 Lenguaje de programación principal.
Lenguaje de programación principal. -
 Microframework web.
Microframework web. -
 Sistema de almacenamiento persistente.
Sistema de almacenamiento persistente. -
 Proxy de conexión de python con la BD.
Proxy de conexión de python con la BD. -
 Facilita el uso de peticiones HTTP 1.1.
Facilita el uso de peticiones HTTP 1.1. -
 Módulo empleado para realizar las pruebas del software.
Módulo empleado para realizar las pruebas del software.
Descripción del microservicio (Nuevo versión 5.0)
La funcionalidad del microservicio de usuarios (user_service) es la siguiente:
-
Identificación de usuarios: Permite identificar a un usuario por medio de username y password.
-
Creación de usuarios: Permite registrar nuevos usuarios.
-
Borrado de usuarios: Permite eliminar usuarios del sistema
-
Búsqueda de usuarios: Permite listar la información de un usuario en el caso de tener privilegios de administrador.
-
Listado de usuarios: Permite realizar un listado de usuarios
La funcionalidad del microservicio de tareas (task_service) es la siguiente:
-
Identificación de usuarios: Permite identificar a un usuario por medio de username y password.
-
Creación de usuarios: Permite registrar nuevos usuarios.
-
Borrado de usuarios: Permite eliminar usuarios del sistema
-
Añadir tareas: Permite que los usuarios añadan nuevas tareas a través de una petición PUT.
-
Modificar tareas: Permite que los usuarios modifiquen tareas a través de una petición POST.
-
Eliminar tareas: Permite que los usuarios eliminen tareas a través de una petición DELETE.
-
Mostrar tareas: Permite que mostrar a los usuarios el conjunto de tareas que existen. En el siguiente hito se desarrollará este apartado más en profundidad, permitiendo enlazar a los usuarios registrados e identificados en el sistema utilizando el microservicio de login y registro, y posteriormente accediendo al microservicio de tareas donde puedan consultar y gestionar sus propias tareas.
Descripción de la arquitectura de la aplicación
Hasta ahora se han implementado dos microservicios llamados user_service y task_service.
Cuando el microservicio user_service recibe una petición por parte del cliente, este interactúa con otro servicio de base de datos noSQL que es el servicio que almacena los datos de la aplicación (dicho servicio es porporcionado por mlab), y finalmente se devuelve la respuesta de la petición al cliente.
De igual forma que el anterior, cuando el microservicio task_service recibe una petición por parte del cliente, interactúa con el servicio de base de datos y con el microservicio de usuarios para devolver la respuesta a la petición del cliente.
Como se puede observar, el microservicio de tareas utiliza el microservicio de usuarios para poder gestionar la información de los usuarios y su acceso al sistema mediante una autenticación por token.
La arquitectura se ha modificado de esta versión (Versión 4.0).
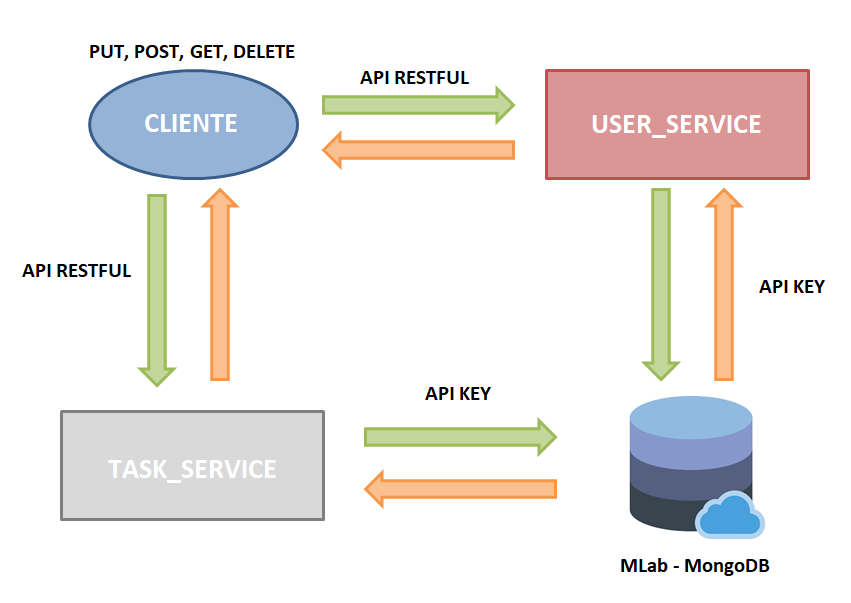
A esta otra (Versión 5.0)
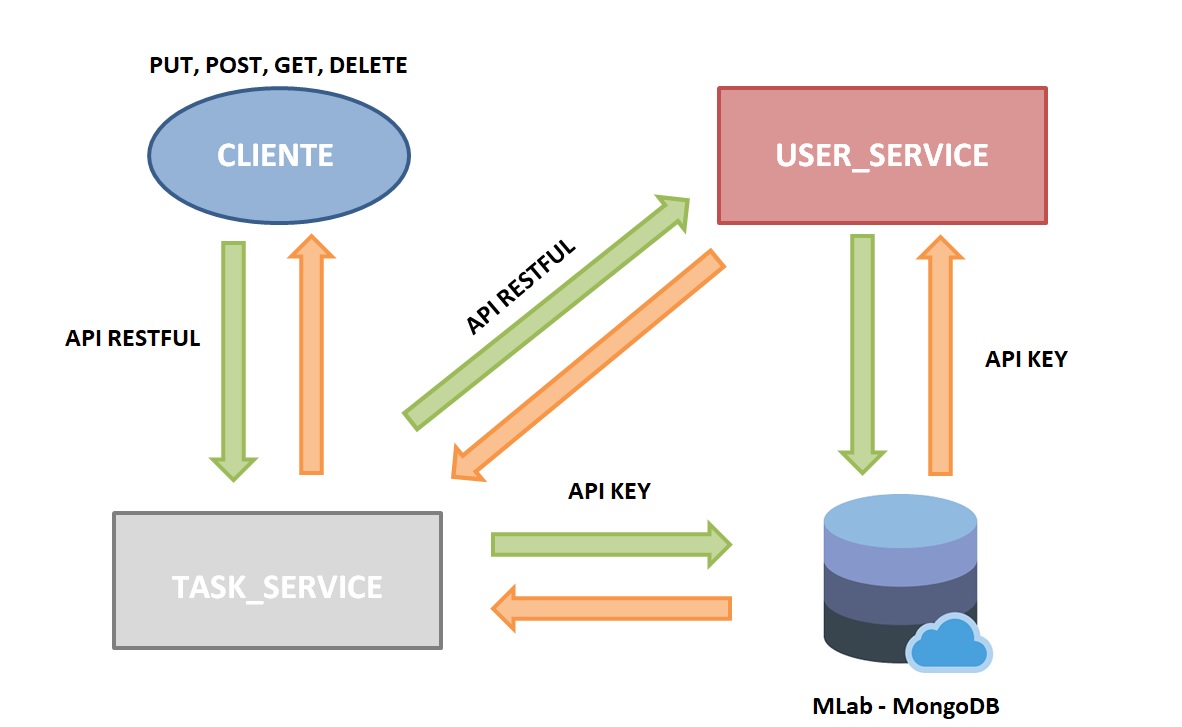
Guía de uso del microservicio de tareas (Versión 5.0).
En primer lugar, para poder acceder a las funcionalidades, es necesario registrarse o identificarse.
Creación de un usuario
[PUT] --> {
'username':'nombreUsuario', 'password':'contraseña', 'email':'direccionEmail'
} --> http://DirecciónIP/userSi el usuario se ha creado correctamente nos devolverá el siguiente json:
[RESPONSE] --> {
message' : 'New user created!
}Identificación de un usuario
Para poder identificarnos en la aplicación, será necesario introducir nuestro usuario y contraseña en el login.
Tras dicha identificación, se devolverá un mensaje de bienvenida al usuario y el token de sesión que se necesita enviar en la cabecera de cada petición para acceder a las diferentes funcionalidades.
[POST] --> {
'usuario':'nombreUsuario',
'password':'contraseña'
} --> http://DirecciónIP/loginEn el caso de realizar un login correcto se nos devolverá un mensaje como el siguiente:
[RESPONSE] --> {
message' : 'Bienvenid@ usuario',
token : 'tokenHash'
}En el caso de introducir erróneamente los datos, se distinguen los siguientes casos:
-
Enviar una petición POST con el contenido de los datos de forma incorrecta (falta algún campo, las claves no se llaman username, pasword...). En tal caso se nos mostrará un mensaje de error como el siguiente:
Could not verify, invalid arguments!
-
Introducir un usuario inexistente. En tal caso se nos mostrará un mensaje de error como el siguiente:
User does not exist! -
Introducir una contraseña errónea. En tal caso se nos mostrará el siguiente mensaje:
Password incorrect!
Obtener los datos del usuarios
Para listar la información de un usuario, basta con realizar la siguiente petición GET:
[GET] --> {
headers={ 'content-type': 'application/json',
'access-token': 'tokenHash'
}
} --> http://DirecciónIP/user/<username>En el caso de ser usuario administrador o buscar su propio perfil, la información que nos devuelve es la siguiente:
[RESPONSE] --> {
users' :
{
"admin": "False",
"email": "email@correo.ugr.es",
"password": "sha256$8gyJWifM$78e76359473b9fefdbc888ec47eaa98571458b368ff74c19a7be68d7e6160c45",
"public_id": "b0c8b763-0bad-41bc-ad16-032cb8e3f10f",
"username": "usuarioPrueba"
}
}Si se intenta mirar el perfil de otro usuario sin ser administrador nos mostrará el siguiente mensaje:
[RESPONSE] --> {
'message' : 'You cannot perform that action!'
}O si el usuario buscado no existe:
[RESPONSE] --> {
'message' : 'User not found!'
}Eliminar a un usuario
Esta funcionalidad nos permite eliminar permanentemente un usuario del sistema. Para eliminar a un usuario basta con realizar la siguiente petición DELETE:
[DELETE] --> {
headers={ 'content-type': 'application/json',
'access-token': 'tokenHash'
}
} --> http://DirecciónIP/user/<username>Tras eliminar al usuario, se nos devolverá un mensaje con código de error 204.
Añadir tareas
Para añadir una tarea vamos a realizar una petición PUT, añadiendo la información en formato JSON. Como se puede observar en la siguient imagen, no es necesario añadir el task_id, ya que el servicio lo inserta automáticamente.
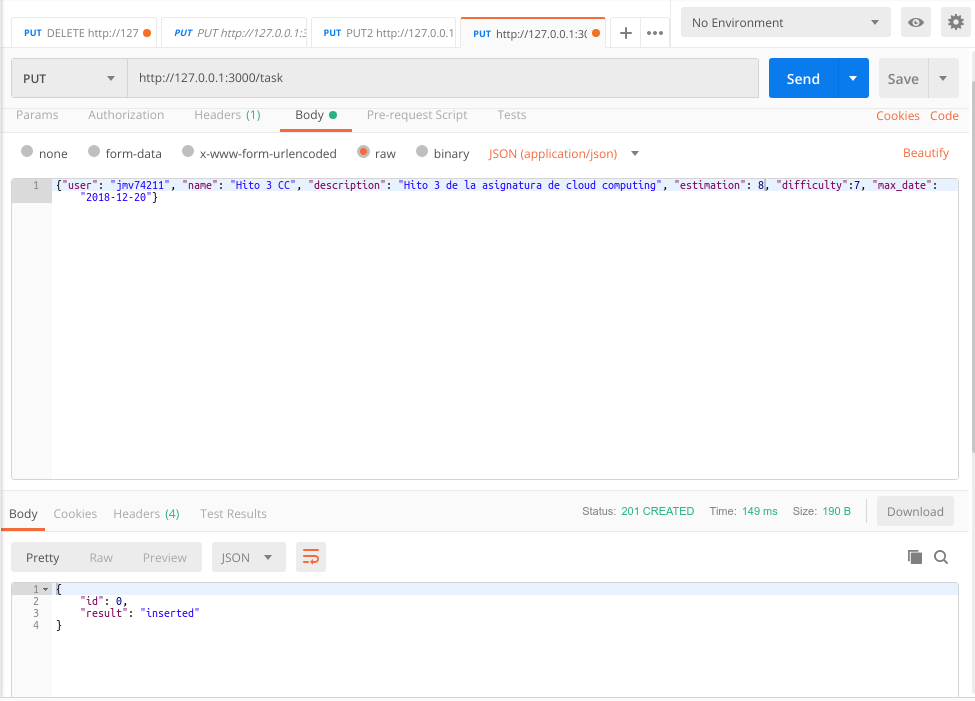
Como resultado nos devuelve que se ha insertado con id = 0 y un código de estado de 201.
Mostrar tareas
Para mostar una tarea, vamos a utilizar la petición GET.
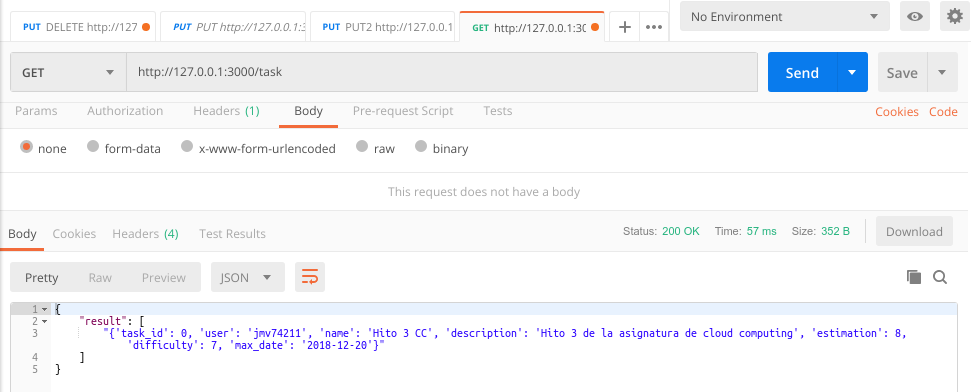
Como se puede observar, nos muestra la tarea que añadimos en el apartado anterior con un código de estado = 200.
Modificar tareas
En primer lugar vamos a añadir otra tarea utilizando la orden PUT descrita anteriormente. La tarea la vamos a relacionar con una supuesta práctica de IC.
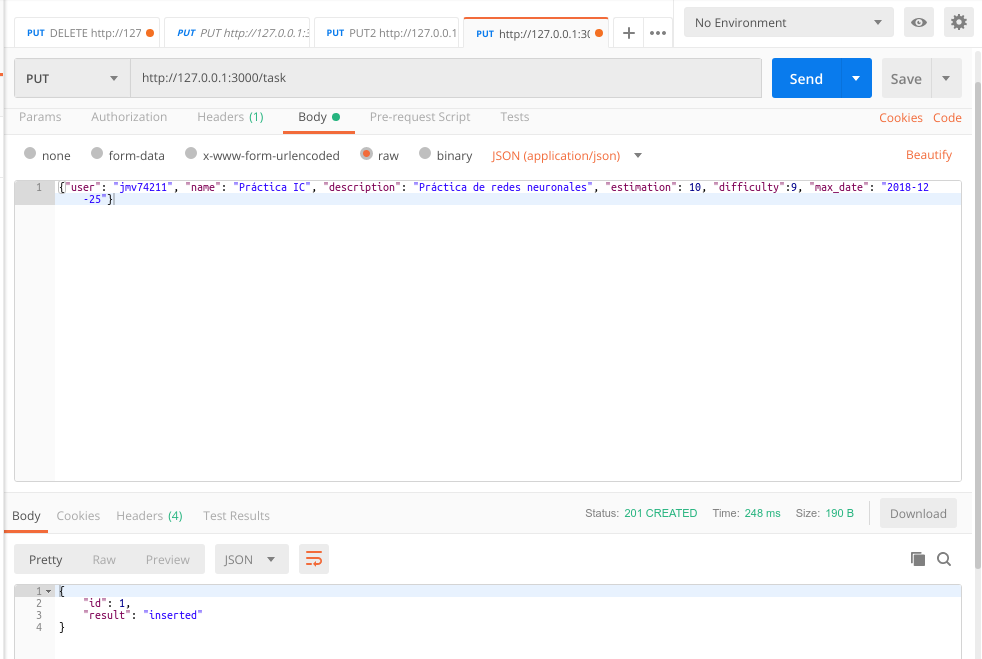
Ahora vamos a proceder a modificar dicha tarea mediante la petición POST. Por ejemplo vamos a modificar la estimación temporal y la fecha máxima de entrega.
Atención: En este caso si es necesario introducir el task_id, para poder identificar la tarea que deseamos modificar.
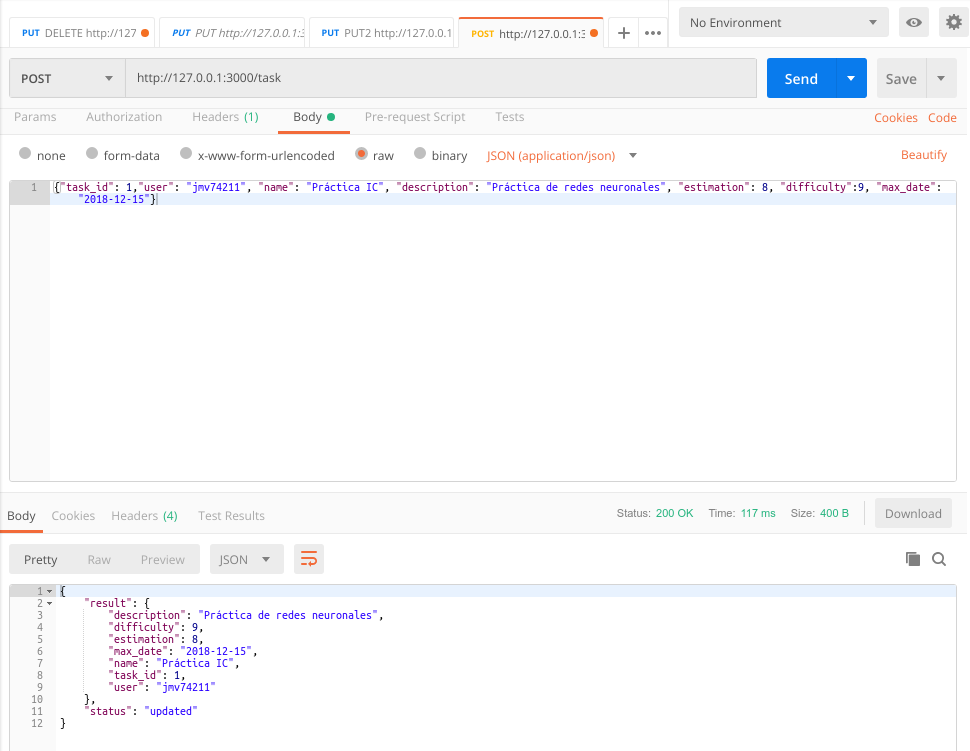
Eliminar tareas
Para proceder a eliminar una tarea vamos a utilizar la petición DELETE. Simplemente basta con emplear el identificador de la tarea que se desea eliminar, como se puede observar en la siguiente imagen:
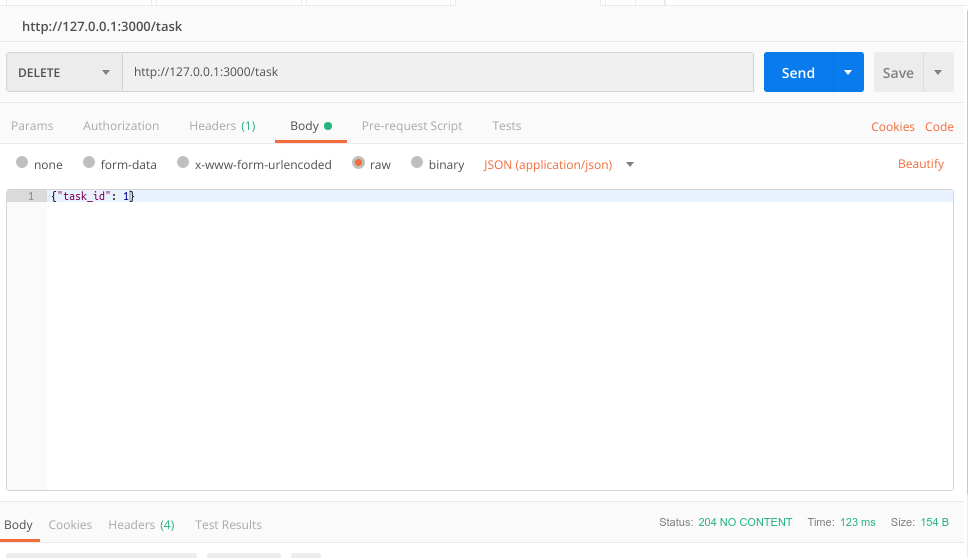
Como se puede observar, nos devuelve el código de estados 204, correspondiente a que no hay contenido.
Volvemos a comprobar la lista de tareas mediante la petición GET para verificar que la tarea se ha eliminado correctamente.
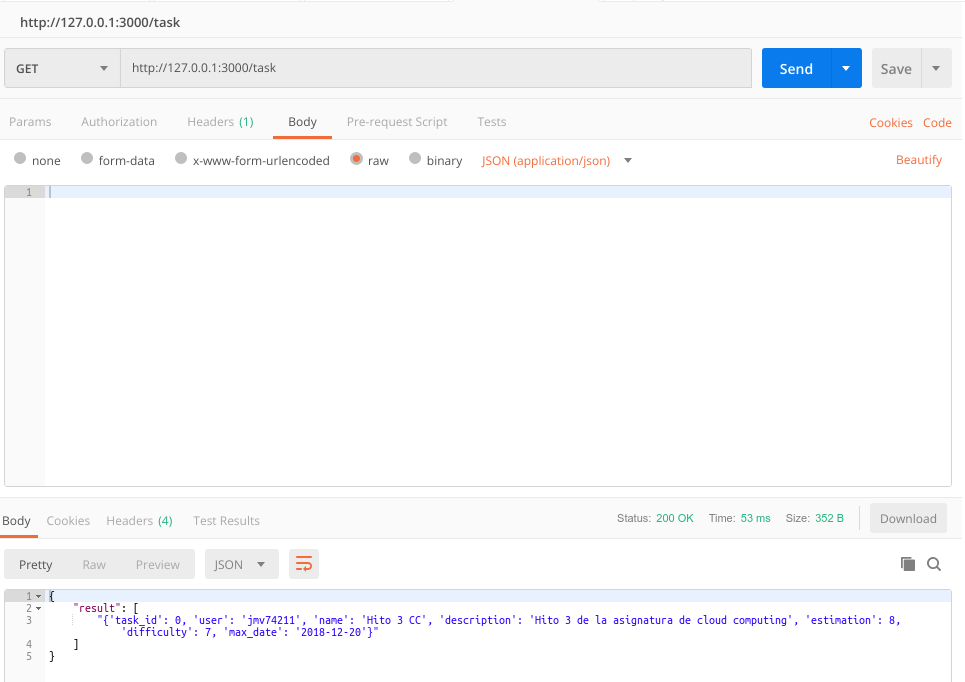
Despliegue de la aplicación en PaaS
La aplicación se ha desplegado en el PaaS heroku. En el siguiente enlace se puede ver el por qué se ha tomado esta decisión, y cómo se ha realizado.
Despliegue: https://proyecto-smartage.herokuapp.com/
Despliegue de la infraestructura en máquina local
Instrucciones para el despliegue en localhost
En el caso de que se quiera realizar un despliegue de forma local, se proporciona una serie de código que define la infraestructura necesaria para su correcto despliegue en cuestión de segundos o pocos minutos.
Vagrant
En primer lugar, se ha utilizado Vagrant para generar entornos de desarrollo reproducibles y compartibles de forma muy sencilla.
La versión de vagrant que se ha usado en este proyecto es: Vagrant 2.0.2
En este caso se ha utilizado para crear una máquina virtual en virtualbox, y configurado para que se ejecute un script de aprovisionamiento que instale el software necesario para que se ejecute nuestra aplicación.
El archivo donde se describe esta infraestructura se llama Vagrantfile y el utilizado en este proceso de despliegue es el siguiente.
Ansible
Como software para automatizar el proceso de aprovisionamiento se ha utilizado Ansible.
La versión de ansible que se ha utilizado en este proyecto es: ansible 2.7.2
Los archivos necesarios para ejecutar correctamente ansible son los siguientes:
-
ansible.cfg: Archivo para configurar ansible.
-
ansible_hosts: Archivo para definir el conjunto de host.
-
playbook_principal.yml: Archivo donde se define el conjunto de instrucciones que se van a ejecutar en los hosts. En este caso se han utilizado roles para instalar una configuración base y la versión 3.6 de python.
Se puede consultar el contenido de dichos archivos haciendo click en el nombre del archivo de la lista anterior.
Despliegue de la infraestructura
Una vez descargado el repositorio e instalado vagrant y ansible, montar la infraestructura necesaria para ejecutar el proyecto es muy sencillo.
Basta con situarse en el directorio de vagrant dentro del directorio del proyecto y ejecutar vagrant up.
Automáticamente se creará la máquina virtual (en este caso utilizando VirtualBox) y se ejecutará el playbook principal que contiene el conjunto de instrucciones para instalar el software necesario para el despliegue.
En el caso de no utilizar vagrant, también podemos realizar el aprovisionamiento utilizando órdenes de ansible. En este caso podemos ejecutar el aprovisionamiento situándose dentro del directorio provision y ejecutando la orden ansible-playbook playbook_principal.yml.
Despliegue de la infraestructura y aprovisionamiento en azure
Se ha creado una máquina virtual en Azure con ubuntu 16.04 LTS.
Para poder ejecutar el aprovisionamiento, se ha creado un playbook específico que se puede ejecutar con la orden ansible-playbook playbook_principal.yml y que instala todo el software y dependencias necesarias para lanzar la aplicación.
Tras ejecutar dicho playbook con ansible, lanzamos la aplicación y probamos que funciona correctamente haciendo peticiones a la siguiente dirección:
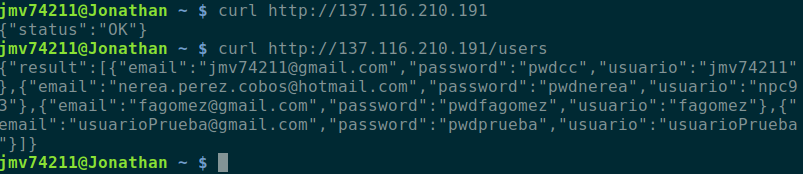
Se puede consultar la documentación correspondiente al hito número 3 que describe con más detalle el apartado del despliegue de la infraestructura virtual y del aprovisionamiento.
Comprobaciones de aprovisionamiento del hito3
-
Comprobación de @jmv74211 al aprovisionamiento de @gecofer disponible en este enlace.
-
Comprobación de @gecofer al aprovisionamiento de @jmv74211 disponible en este enlace.
Creación automática de una máquina virtual en Azure
Para poder crear una máquina virtual en Azure de forma automática, se ha realizado un script llamado [acopio.sh]() que se encarga de crear la máquina utilizando las órdenes del cliente de Azure y aprovisionando dicha máquina mediante ansible para que se pueda ejecutar de forma sencilla nuestra aplicación en cuestión de unos segundos.
Simplemente basta con ejecutar el siguiente script con la siguiente orden:
./acopio.shLa información relacionada con todo este proceso está disponible en la documentación del hito 4.
Orquestación de 2 máquinas virtuales con Vagrant en azure
Para poder orquestar las dos máquinas virtuales que darán la infraestructura necesaria para que los microservicios de tareas y usuarios funcionen correctamente, se ha utilizado Vagrant utilizando como proveedor Azure.
En el directorio orquestación está disponible el Vagrantfile que se ha utilizado, y se puede revisar la documentación del hito 5 para conocer más en profundidad cómo se ha realizado.
Comprobaciones del hito 5
-
Comprobación de @jmv74211 al aprovisionamiento de @gecofer disponible en este enlace.
-
Comprobación de @gecofer al aprovisionamiento de @jmv74211 disponible en este enlace.
Contenedores docker (NUEVO versión 6.0)
Se ha realizado el despliegue de los microservicios de usuarios y tareas mediante contenedores Docker. Para ello se ha elaborado un dockerfile para cada microservicio y finalmente se ha creado un script para generar las imágenes (en base a dichos dockerfiles), y posteriormente ejecutarlos hasta lanzar la aplicación de forma automática.
Dicho despliegue se ha realizado tanto de forma local como en azure.
Para más información, consultar la documentación generada del hito 6