Paper
Abstract
The recent Maddness method approximates Matrix Multiplication (MatMul) without the need for multiplication by using a hash-based version of product quantization (PQ). The hash function is a decision tree, allowing for efficient hardware implementation, as multiply-accumulate operations are replaced by decision tree passes and LUT lookups. Stella Nera is the first Maddness accelerator achieving 15x higher area efficiency (GMAC/s/mm^2) and 25x higher energy efficiency (TMAC/s/W) than direct MatMul accelerators in the same technology. In a commercial 14 nm technology and scaled to 3 nm, we achieve an energy efficiency of 161 TOp/s/W@0.55V with a Top-1 accuracy on CIFAR-10 of over 92.5% using ResNet9.
Algorithmic - Maddness

ResNet-9 LUTs, Thresholds, Dims
Halutmatmul example
import numpy as np
from halutmatmul.halutmatmul import HalutMatmul
A = np.random.random((10000, 512))
A_train = A[:8000]
A_test = A[8000:]
B = np.random.random((512, 10))
C = np.matmul(A_test, B)
hm = HalutMatmul(C=32, K=16)
hm.learn_offline(A_train, B)
C_halut = hm.matmul_online(A_test)
mse = np.square(C_halut - C).mean()
print(mse)Installation
# install conda environment & activate
# mamba is recommended for faster install
conda env create -f environment_gpu.yml
conda activate halutmatmul
# IIS prefixed env
conda env create -f environment_gpu.yml --prefix /scratch/janniss/conda/halutmatmul_gpuDifferentiable Maddness

Hardware - OpenROAD flow results from CI - NOT OPTIMIZED
All completely open hardware results are NOT OPTIMIZED! The results are only for reference and to show the flow works. In the paper results from commercial tools are shown. See this as a community service to make the hardware results more accessible.
| All Designs | NanGate45 |
|---|---|
| All Report | All |
| History | History |
Open Hardware Results Table
| NanGate45 | halut_matmul | halut_encoder_4 | halut_decoder |
|---|---|---|---|
| Area [μm^2] | 128816 | 46782 | 24667.5 |
| Freq [Mhz] | 166.7 | 166.7 | 166.7 |
| GE | 161.423 kGE | 58.624 kGE | 30.911 kGE |
| Std Cell [#] | 65496 | 23130 | 12256 |
| Voltage [V] | 1.1 | 1.1 | 1.1 |
| Util [%] | 50.4 | 48.7 | 52.1 |
| TNS | 0 | 0 | 0 |
| Clock Net |  |
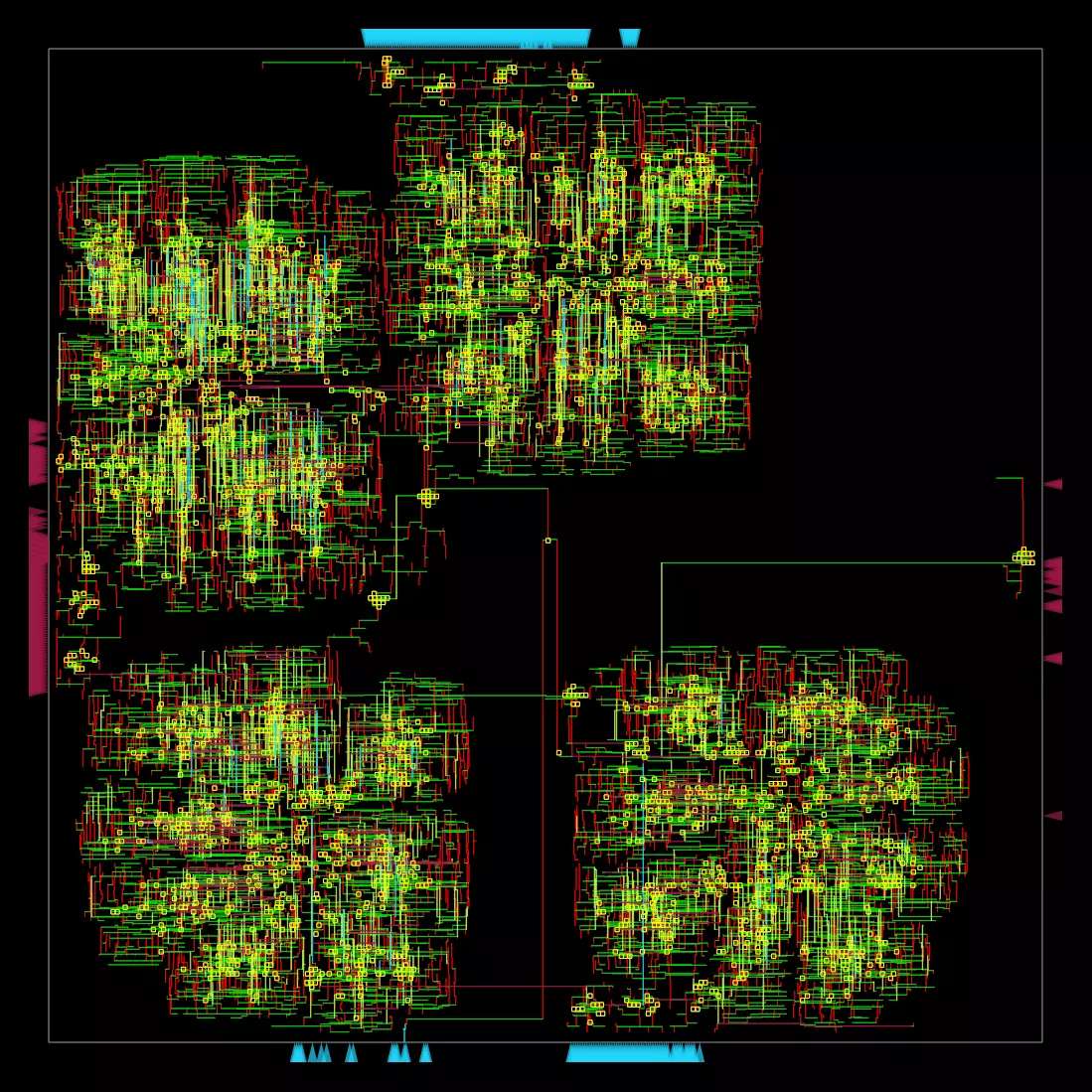 |
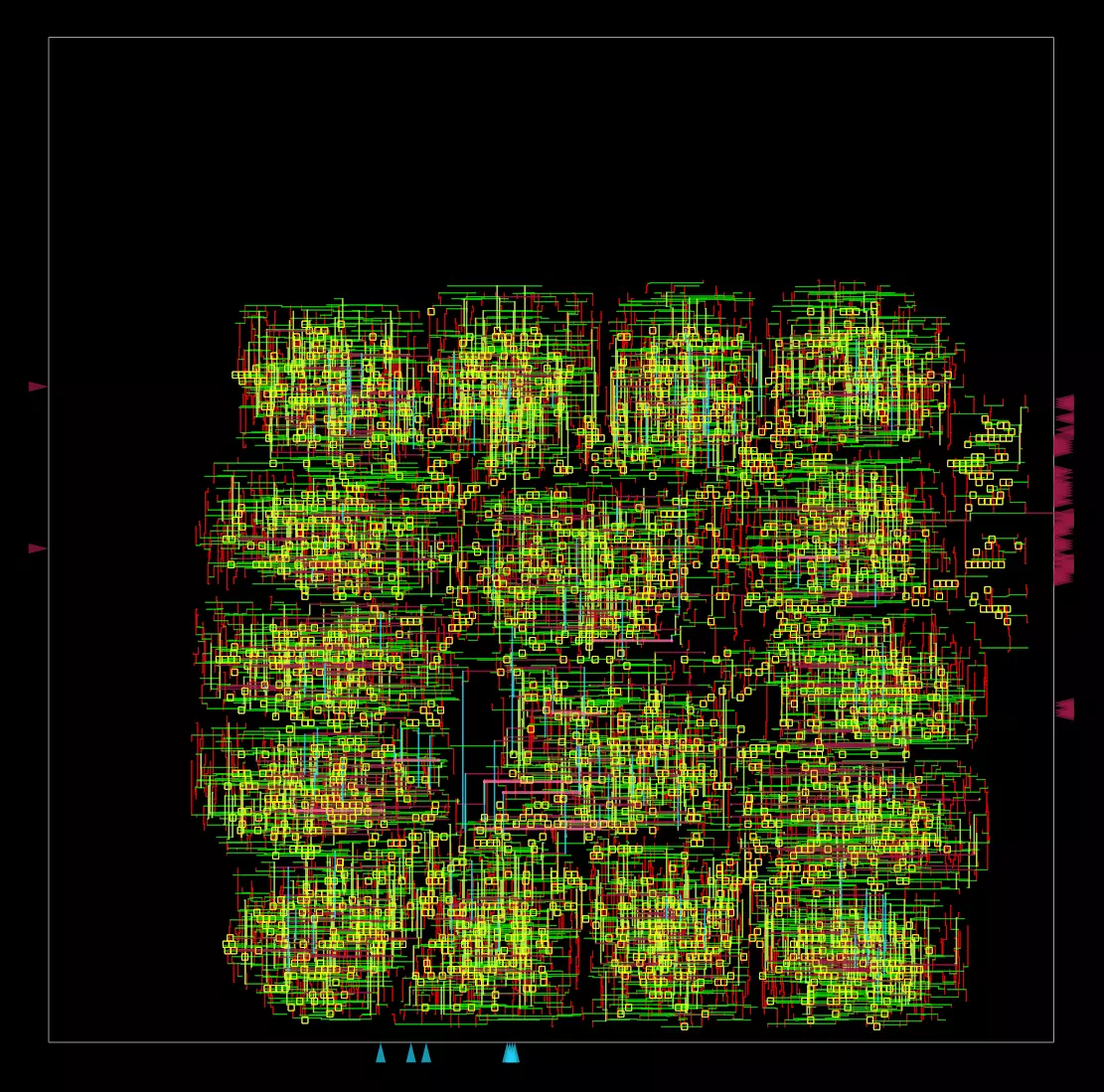 |
| Routing | 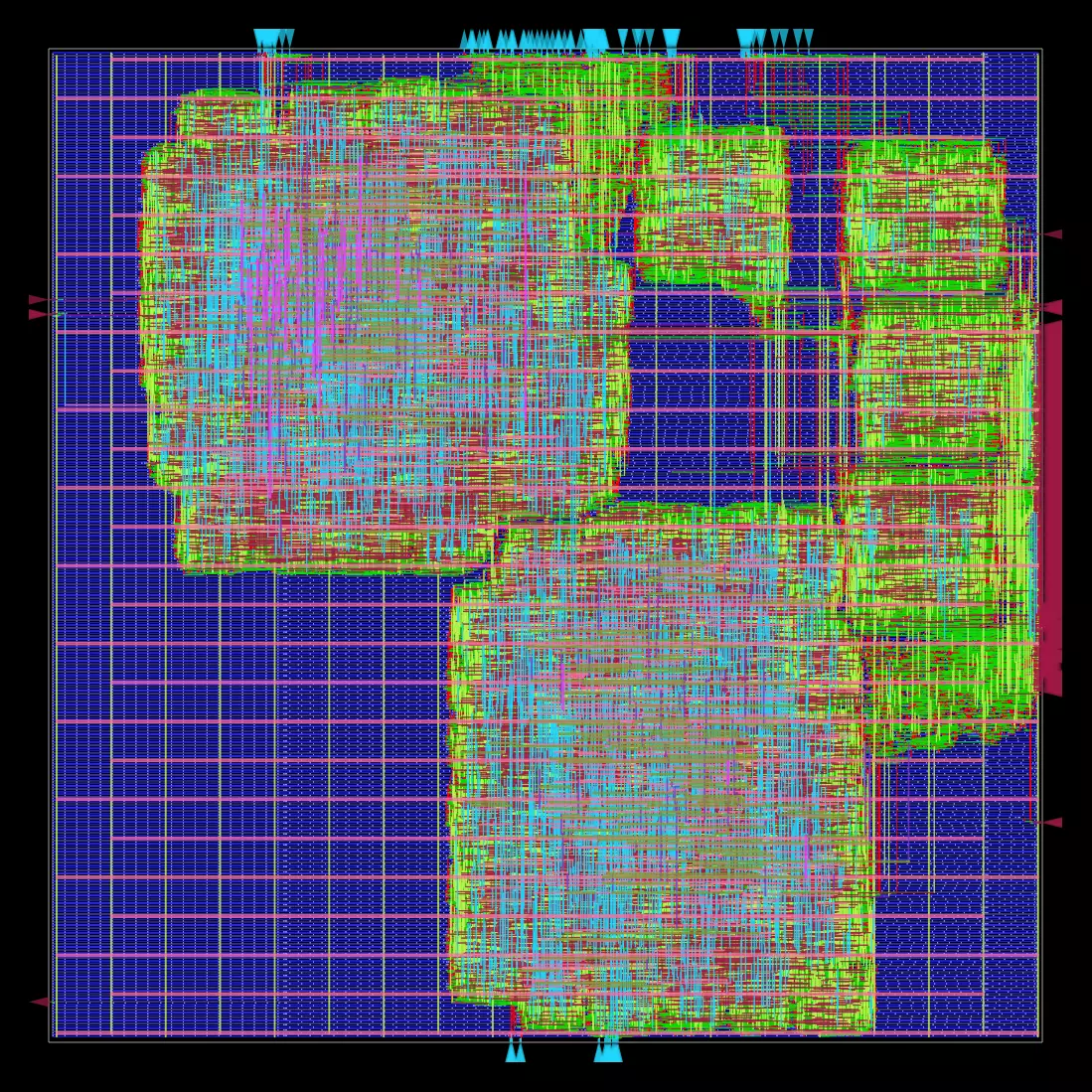 |
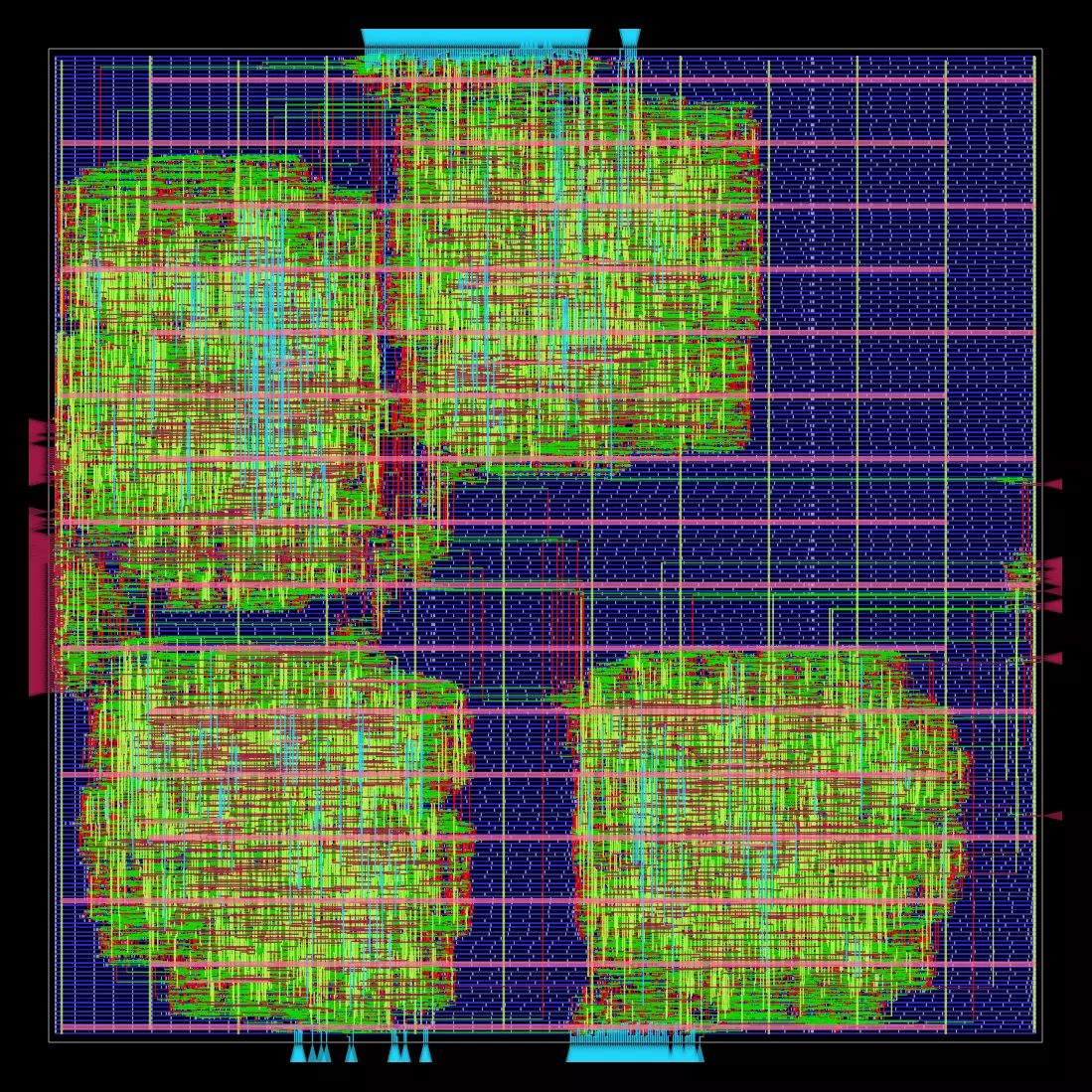 |
 |
| GDS | GDS Download | GDS Download | GDS Download |
Full design (halutmatmul)
Run locally with:
git submodule update --init --recursive
cd hardware
ACC_TYPE=INT DATA_WIDTH=8 NUM_M=8 NUM_DECODER_UNITS=4 NUM_C=16 make halut-open-synth-and-pnr-halut_matmulReferences
- arXiv Maddness paper
- Based on MADDness/Bolt.
Citation
@article{schonleber2023stella,
title={Stella Nera: Achieving 161 TOp/s/W with Multiplier-free DNN Acceleration based on Approximate Matrix Multiplication},
author={Sch{\"o}nleber, Jannis and Cavigelli, Lukas and Andri, Renzo and Perotti, Matteo and Benini, Luca},
journal={arXiv preprint arXiv:2311.10207},
year={2023}
}