Improving Video Captioning with Temporal Composition of a Visual-Syntactic Embedding
![]()
This repository is the source code for the paper titled Improving Video Captioning with Temporal Composition of a Visual-Syntactic Embedding. Video captioning is the task of predicting a semantic and syntactically correct sequence of words given some context video. In this paper, we consider syntactic representation learning as an essential component of video captioning. We construct a visual-syntactic embedding by mapping into a common vector space a visual representation, that depends only on the video, with a syntactic representation that depends only on Part-of-Speech (POS) tagging structures of the video description. We integrate this joint representation into an encoder-decoder architecture that we call Visual-Semantic-Syntactic Aligned Network (SemSynAN), which guides the decoder (text generation stage) by aligning temporal compositions of visual, semantic, and syntactic representations. We tested our proposed architecture obtaining state-of-the-art results on two widely used video captioning datasets: the Microsoft Video Description (MSVD) dataset and the Microsoft Research Video-to-Text (MSR-VTT) dataset.
Table of Contents
Model
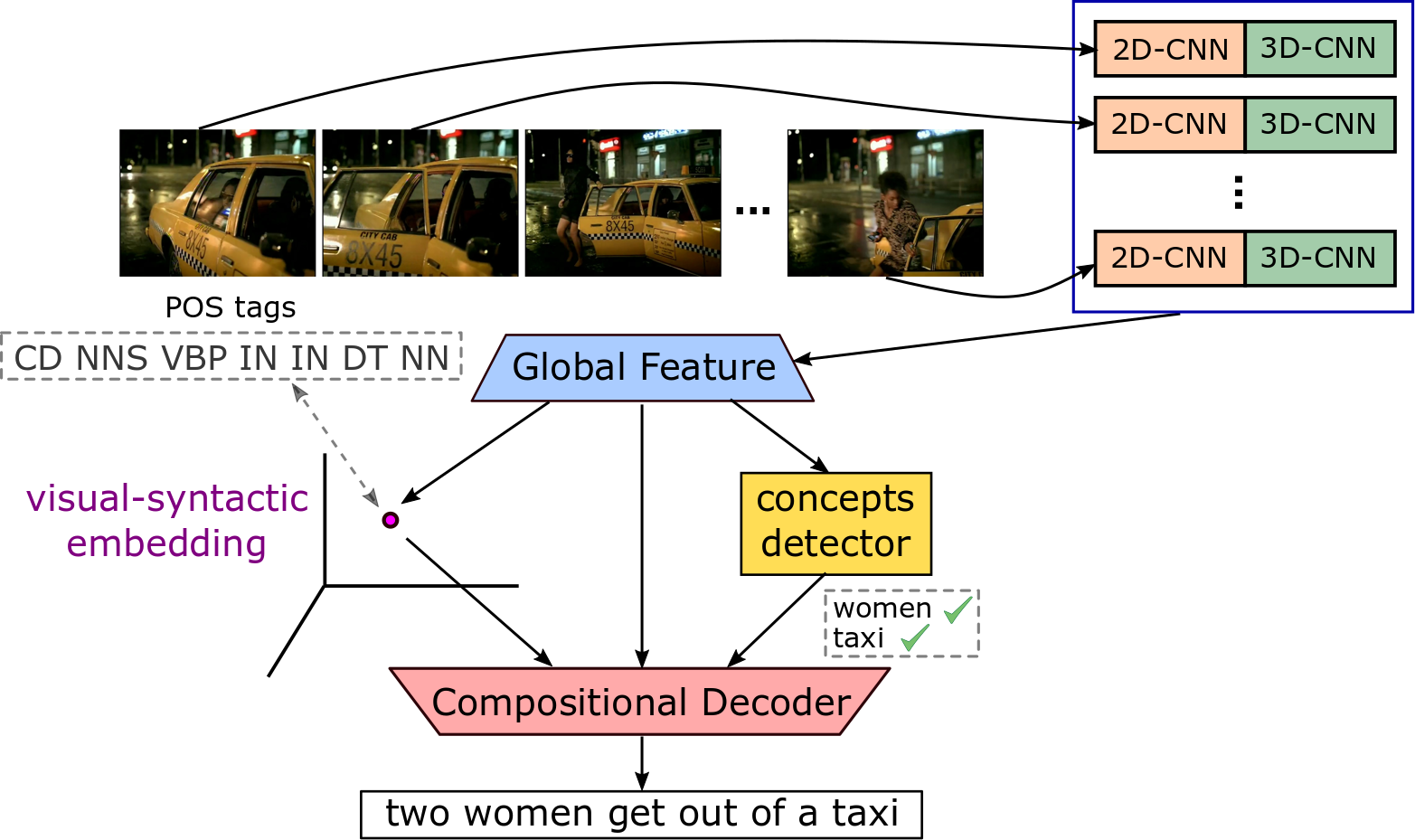 |
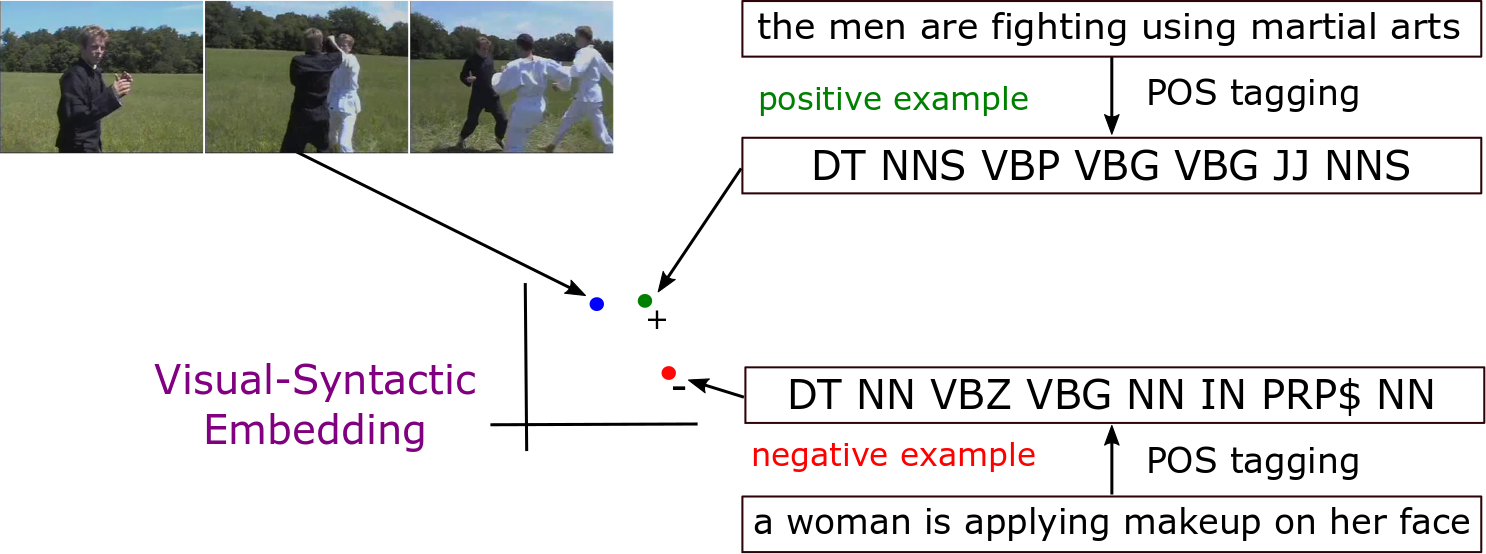 |
| Video Captioning with Visual-Syntactic Embedding (SemSynAN) | Visual-Syntactic Embedding |
Requirements
- Python 3.6
- PyTorch 1.2.0
- NumPy
- h5py
Manual
git clone --recursive https://github.com/jssprz/visual_syntactic_embedding_video_captioning.gitDownload Data
mkdir -p data/MSVD && wget -i msvd_data.txt -P data/MSVD
mkdir -p data/MSR-VTT && wget -i msrvtt_data.txt -P data/MSR-VTTFor extracting your own visual features representations you can use our visual-feature-extracotr module.
Training
If you want to train your own models, you can reutilize the datasets' information stored and tokenized in the corpus.pkl files.
For constructing these files you can use the scripts we provide in video_captioning_dataset module.
Basically, the content of these files is organized as follow:
0: train_data: captions and idxs of training videos in format [corpus_widxs, vidxs], where:
corpus_widxsis a list of lists with the index of words in the vocabularyvidxsis a list of indexes of video features in the features file
1: val_data: same format of train_data.
2: test_data: same format of train_data.
3: vocabulary: in format {'word': count}.
4: idx2word: is the vocabulary in format {idx: 'word'}.
5: word_embeddings: are the vectors of each word. The i-th row is the word vector of the i-th word in the vocabulary.
We use the val_references.txt and test_references.txt files for computing the evaluation metrics only.
Testing
1. Download pre-trained models at epochs 41 (for MSVD) and 12 (for MSR-VTT)
wget https://s06.imfd.cl/04/github-data/SemSynAN/MSVD/captioning_chkpt_41.pt -P pretrain/MSVD
wget https://s06.imfd.cl/04/github-data/SemSynAN/MSR-VTT/captioning_chkpt_12.pt -P pretrain/MSR-VTT2. Generate captions for test samples
python test.py -chckpt pretrain/MSVD/captioning_chkpt_41.pt -data data/MSVD/ -out results/MSVD/
python test.py -chckpt pretrain/MSR-VTT/captioning_chkpt_12.pt -data data/MSR-VTT/ -out results/MSR-VTT/3. Metrics
python evaluate.py -gen results/MSVD/predictions.txt -ref data/MSVD/test_references.txt
python evaluate.py -gen results/MSR-VTT/predictions.txt -ref data/MSR-VTT/test_references.txtQualitative Results

Quantitative Results
| Dataset | epoch | B-4 | M | C | R |
|---|---|---|---|---|---|
| MSVD | 100 | 64.4 | 41.9 | 111.5 | 79.5 |
| MSR-VTT | 60 | 46.4 | 30.4 | 51.9 | 64.7 |
Citation
@InProceedings{Perez-Martin_2021_WACV,
author = {Perez-Martin, Jesus and Bustos, Benjamin and Perez, Jorge},
title = {Improving Video Captioning With Temporal Composition of a Visual-Syntactic Embedding},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
month = {January},
year = {2021},
pages = {3039-3049}
}