![]()
![]()
![]()
![]()
Pytorch Implementation of the ES-RNN
Pytorch implementation of the ES-RNN algorithm proposed by Smyl, winning submission of the M4 Forecasting Competition. The class wraps fit and predict methods to facilitate interaction with Machine Learning pipelines along with evaluation and data wrangling utility. Developed by Autonlab’s members at Carnegie Mellon University.
Installation Prerequisites
- numpy>=1.16.1
- pandas>=0.25.2
- pytorch>=1.3.1
Installation
This code is a work in progress, any contributions or issues are welcome on GitHub at: https://github.com/kdgutier/esrnn_torch
You can install the released version of ESRNN from the Python package index with:
pip install ESRNNUsage
Input data
The fit method receives X_df, y_df training pandas dataframes in long format. Optionally X_test_df and y_test_df to compute out of sample performance.
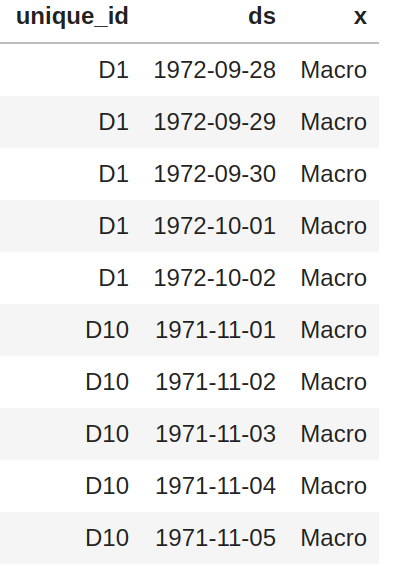
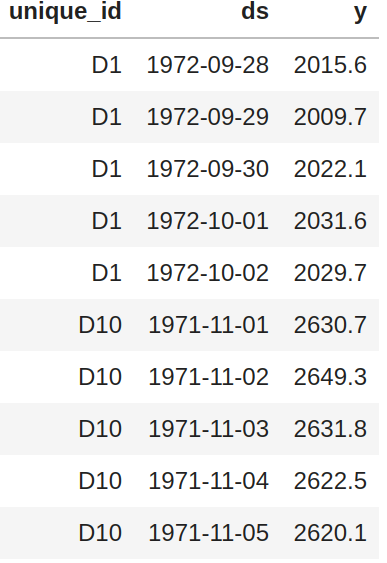
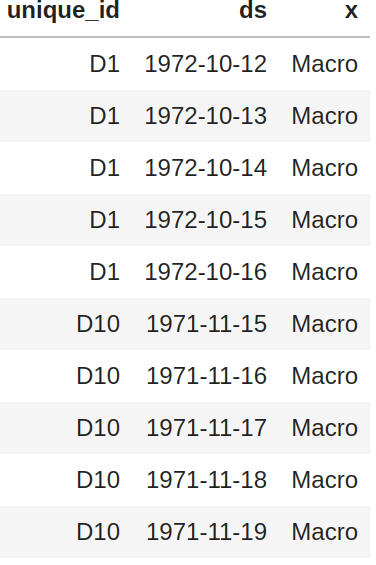
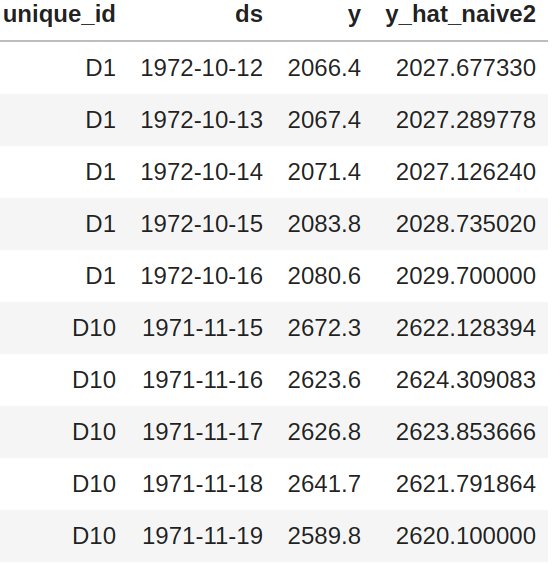
X_dfmust contain the columns['unique_id', 'ds', 'x']y_dfmust contain the columns['unique_id', 'ds', 'y']X_test_dfmust contain the columns['unique_id', 'ds', 'x']y_test_dfmust contain the columns['unique_id', 'ds', 'y']and a benchmark model to compare against (default'y_hat_naive2').
For all the above:
- The column
'unique_id'is a time series identifier, the column'ds'stands for the datetime. - Column
'x'is an exogenous categorical feature. - Column
'y'is the target variable. - Column
'y'does not allow negative values and the first entry for all series must be grater than 0.
The X and y dataframes must contain the same values for 'unique_id', 'ds' columns and be balanced, ie.no gaps between dates for the frequency.
 |
|  |
|  |
|  |
|
M4 example
from ESRNN.m4_data import prepare_m4_data
from ESRNN.utils_evaluation import evaluate_prediction_owa
from ESRNN import ESRNN
X_train_df, y_train_df, X_test_df, y_test_df = prepare_m4_data(dataset_name='Yearly',
directory = './data',
num_obs=1000)
# Instantiate model
model = ESRNN(max_epochs=25, freq_of_test=5, batch_size=4, learning_rate=1e-4,
per_series_lr_multip=0.8, lr_scheduler_step_size=10,
lr_decay=0.1, gradient_clipping_threshold=50,
rnn_weight_decay=0.0, level_variability_penalty=100,
testing_percentile=50, training_percentile=50,
ensemble=False, max_periods=25, seasonality=[],
input_size=4, output_size=6,
cell_type='LSTM', state_hsize=40,
dilations=[[1], [6]], add_nl_layer=False,
random_seed=1, device='cpu')
# Fit model
# If y_test_df is provided the model
# will evaluate predictions on
# this set every freq_test epochs
model.fit(X_train_df, y_train_df, X_test_df, y_test_df)
# Predict on test set
y_hat_df = model.predict(X_test_df)
# Evaluate predictions
final_owa, final_mase, final_smape = evaluate_prediction_owa(y_hat_df, y_train_df,
X_test_df, y_test_df,
naive2_seasonality=1)Overall Weighted Average
A metric that is useful for quantifying the aggregate error of a specific model for various time series is the Overall Weighted Average (OWA) proposed for the M4 competition. This metric is calculated by obtaining the average of the symmetric mean absolute percentage error (sMAPE) and the mean absolute scaled error (MASE) for all the time series of the model and also calculating it for the Naive2 predictions. Both sMAPE and MASE are scale independent. These measurements are calculated as follows:
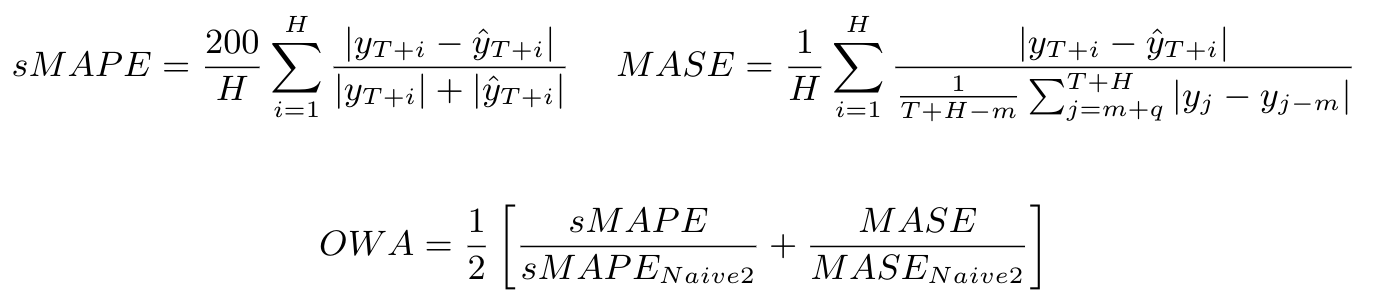
Current Results
Here we used the model directly to compare to the original implementation. It is worth noticing that these results do not include the ensemble methods mentioned in the ESRNN paper.
Results of the M4 competition.
| DATASET | OUR OWA | M4 OWA (Smyl) |
|---|---|---|
| Yearly | 0.785 | 0.778 |
| Quarterly | 0.879 | 0.847 |
| Monthly | 0.872 | 0.836 |
| Hourly | 0.615 | 0.920 |
| Weekly | 0.952 | 0.920 |
| Daily | 0.968 | 0.920 |
Replicating M4 results
Replicating the M4 results is as easy as running the following line of code (for each frequency) after installing the package via pip:
python -m ESRNN.m4_run --dataset 'Yearly' --results_directory '/some/path' \
--gpu_id 0 --use_cpu 0Use --help to get the description of each argument:
python -m ESRNN.m4_run --helpAuthors
This repository was developed with joint efforts from AutonLab researchers at Carnegie Mellon University and Orax data scientists.
- Kin Gutierrez - kdgutier
- Cristian Challu - cristianchallu
- Federico Garza - FedericoGarza - mail
- Max Mergenthaler - mergenthaler
License
This project is licensed under the MIT License - see the LICENSE file for details.
REFERENCES
- A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting
- The M4 Competition: Results, findings, conclusion and way forward
- M4 Competition Data
- Dilated Recurrent Neural Networks
- Residual LSTM: Design of a Deep Recurrent Architecture for Distant Speech Recognition
- A Dual-Stage Attention-Based recurrent neural network for time series prediction