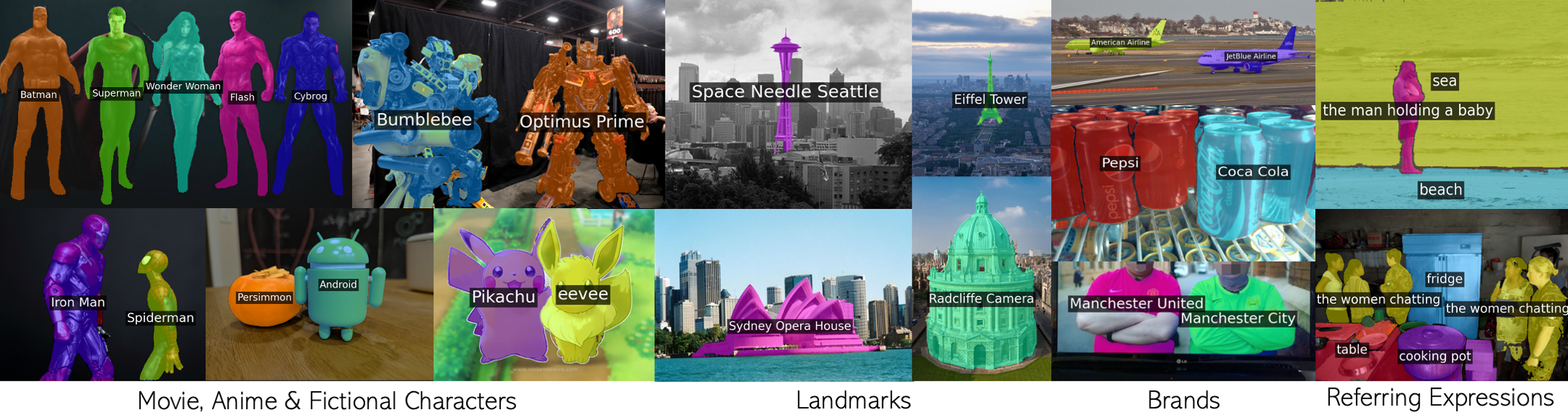
CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor
Shuyang Sun*, Runjia Li*, Philip Torr, Xiuye Gu, Siyang Li
[arXiv] [Project] [Code] [Demo]
The code is fully released at Google Research.
## Installation ### Requirements - Anaconda 3 - PyTorch ≥ 1.7 and [torchvision](https://github.com/pytorch/vision/) that matches the PyTorch installation. Install them together at [pytorch.org](https://pytorch.org) to make sure of this. - `conda env create --name ENV_NAME --file=env.yml` ## Getting Started ### Demo We have set up an online demo. Currently, the web demo does not support SAM since it's just a CPU-only server. You can check it out at: [here](https://huggingface.co/spaces/kevinssy/CLIP_as_RNN?logs=container) ### Run Demo Locally If you want to test an image locally, you can simply run `python3 demo.py --cfg-path=YOUR_CFG_PATH --output_path=SAVE_PATH` ### Evaluation with Benchmarks - Data preparation: See [Preparing Datasets for CaR](DATA.md) - Evaluate: `python3 evaluate.py --cfg-path=CFG_PATH` You can find configs for each dataset under `configs`. ## Citing CaR ``` @inproceedings{clip_as_rnn, title = {CLIP as RNN: Segment Countless Visual Concepts without Training Endeavor}, author = {Sun, Shuyang and Li, Runjia and Torr, Philip and Gu, Xiuye and Li, Siyang}, year = {2024}, booktitle = {CVPR}, } ```