homework1_SW
명령어 정리, 실습 for README.md
명령어
Ⅰ쉘 스크립트 관련
getopt 명령어 & getopts 명령어
1. 역사
원래 getopt에는 몇가지 문제가 있었다. 인수의 공백이나 쉘 메타 문자를 처리 할 수 없었고, 오류 메세지 출력을 비활성화 하는 기능이 없었다.
getopts는 1986년 Unix SVR3와 함께 제공되는 Bourne shell에서 처음 도입되었다. 셸 자체 변수를 사용하여 현재 및 인수 위치, POTIND 와 OPTARG의 위치를 추적하고 셸 변수에 옵션 이름을 반환하였다. Bourne Shell 초기 버전에는 getopts가 없었다.
1995년, getopts는 Single UNIX Specification version 1 / X/Open Portability Guidelines Issue 4dp 포함되었다. 그 결과, getopts는 지금 Bourne shell, KornShell, Almquist shell, Bash 그리고 Zsh을 포함한 쉘에서 사용가능하다.
getopts 명령어는 IBM i 운영체제로 포트되었다.
getopt의 현대적인 사용법은 util-linux 의 향상된 구현으로 인해 부분적으로 활성화 되었다. BSD기반으로 한 getopt 버전은 getopt 대한 두 가지 불만 사항을 수정했을 뿐만 아니라 GNU스타일의 긴 옵션과 옵션에 대한 선택적 인수를 구문 분석하는 기능을 도입했다. 그러나 다양한 BSD 배포판은 여전히 이전 구현을 고수했다.
2.향상
-
다양한 getopts
2004년 봄 (Solaris 10 beta 개발), getopt() 에 대한 libc 구현이 long 옵션을 지원하도록 향상되었다. 결과적으로, 새로운 기능은 Bourne Shell 의 기본 제공 명령에서도 사용할 수 있었다. 이것은 long aliases을 지정 하는 optstring의 괄호로 묶인 접미사에 의해 트리거된다.
KornShell 과 Zsh는 모두 long 인수에 대한 확장을 가지고 있다. KornShell 은 Solaris에서와 같이 정의되고, Zsh는 별도의 zparseopts 명령을 통해 구현된다. KornShell 은 - 대신 + 으로 시작하는 옵션에 대해 optstring확장을 추가로 구현한다.
-
Linux getopt
getopts에 대한 대안은 getop의 향상된 Linux 버전(external command line program)이다.
getopt의 Linux 고급 버전은 getopts의 추가 안전성과 고급 기능들이 있다. 예를 들어, --help 등의 long option name을 지원한다. 그리고 옵션이 모든 피연산자 앞에 나타날 필요가 없다. 예를 들어, command operand1 operand2 -a operand3 -b. 이것은 getopt의 Linux 확장 버전에서는 허용되지만 , getopts는 작동되지 않는다. 또한, tcsh와 POSIX 같은 쉘과 선택적 인수를 위해 이스케이트 메타문자를 지원한다.
3. 비교
| Feature\Program | POSIX getopts | Solaris getopts | Unix/BSD getopt | Linux getopt |
|---|---|---|---|---|
| 쉬운 parsing을 위한 분할 옵션 | 예 | 예 | 예 | 예 |
| 오류 메시지 억제 허용 | 예 | 예 | 아니요 | 예 |
| 공백 및 메타 문자로 안전 | 예 | 예 | 아니요 | 예 |
| 피연산자를 옵션과 혼합할 수 있습니다. | 아니요 | 예 | 아니요 | 예 |
| 긴 옵션 지원 | Emulation | 예 | 아니요 | 예 |
| 선택적 인수 | 오류 | 오류 | 아니요 | 예 |
**Emulation: 모방
4. Option string 과 $OPTIND이용 예

getopt은 getopts builtin 명령과 비슷한데 /usr/bin/getopt 에 위치한 외부 명령이다. 이 명령은 기본적으로 short, long 옵션을 모두 지원한다. 옵션 인수를 가질 경우 ":" 문자를 사용하는 것은 getopts builtin 명령과 동일하다.
#!/bin/bash
set -- -abc hello world
echo $OPTIND
getopts abc opt "$@"
echo $opt, $OPTIND
getopts abc opt #args부분을 생략하면 default값은 "$@"
echo $opt, $OPTIND
getopts abc opt
echo $opt, $OPTIND
shift $(( OPTIND - 1 ))
echo "$@"<출력 결과>

5.getopts이용 예
loop문 이용해 처리
#!/bin/bash
while getopts "a:bc" opt; do case $opt in a) echo >&2 "-a was triggered!, OPTARG: $OPTARG" ;; b) echo >&2 "-b was triggered!" ;; c) echo >&2 "-c was triggered!" ;; esac done
shift $(( OPTIND - 1 )) echo "$@"

**6. getopt 이용 예**
short 옵션 지정은 -o 옵션으로 한다.
':'에 따라 옵션 -a는 옵션 인수는 갖는다.
getopt -o a:bc
long 옵션 지정은 -l 옵션으로 하고 옵션명은 ',' 로 구분한다.
':' 에 따라서 옵션 --path 와 --name 은 옵션 인수를 갖는다.
명령 라인에서 옵션 인수 사용은 "--name foo" 또는 "--name=foo" 두 가지 모두 가능하다.
getopt -l help,path:,name:
명령 마지막에는 -- 와 함께 "$@" 를 붙인다.
getopt -o a:bc -l help,path:,name: -- "$@"
*위를 토대로 bash 파일을 작성해봄 ↓*
* getopt
>↓설정하지 않은 옵션이 사용되거나 옵션 인수가 빠질 경우 오류메시지를 출력해준다.↓
!/bin/bash
options=$( getopt -o a:bc -l help,path:,name: -- "$@" ) echo "$options"
<출력결과>

>↓getopt 명령의 특징은 사용자가 입력한 옵션들을 case 문에서 사용하기 좋게 정렬해준다.↓
!/bin/bash
options=$( getopt -o a:bc -l help,path:,name: -- "$@" ) echo "$options"
<출력결과>

<출력 결과 설명>
>첫번째 명령
>> 1. -a123 옵션이 -a '123' 로 분리.
>> 2. -bc 옵션이 -b -c 로 분리.
>> 3. 옵션에 해당하지 않는 hello.c 는 '--' 뒤로 이동
>두번째 명령
>> --path=/usr/bin 옵션이 --path '/usr/bin' 로 분리
>>'--' 는 항상 끝부분에 붙는다.
>세번째 명령
>>'--' ( end of options ) 처리도 해준다.
* getopt builtin
!/bin/bash
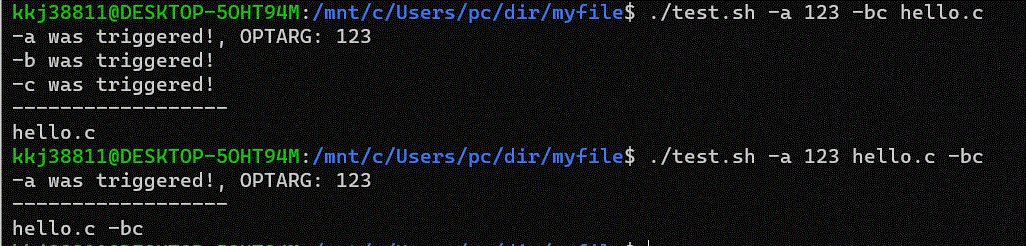
while getopts "a:bc" opt; do case $opt in a) echo >&2 "-a was triggered!, OPTARG: $OPTARG" ;; b) echo >&2 "-b was triggered!" ;; c) echo >&2 "-c was triggered!" ;; esac done
shift $(( OPTIND - 1 )) echo ------------------ echo "$@"
<출력 결과>
## Ⅱ리눅스 명령어 관련
### ⅰ)sed 명령어
**1. 소개**
**sed**(stream editor)는 유닉스에서 텍스트를 분해하거나 변환하기 위한 프로그램이다. sed는 벨 연구소의 Lee E. McMahon이 1973년부터 1974년까지 개발하였고, 현재 유닉스 등의 여러가지 운영 체제에서 사용 가능하다.
|sed| |
|---|---|
|paradigm| scripting|
|Designed| Lee E.McMahon|
|첫 등장 |1974 ; 47 years ago|
|구현 언어 | C |
|웹 사이트 | [GNU sed](https://www.gnu.org/software/sed/) |
|Influenced | ed |
|Incluenced|Perl, AWK|
**2. 역사**
유닉스 7 버전이 처음 등장한, sed는 데이터 파일의 명령 줄 처리를 위해 개발된 초기 유닉스 명령어들 가운데 하나이다. 대중적인 *grep* 명령어의 뒤를 자연스럽게 이을 정도로 발전하였다. 원래는 치환을 목적으로 한 grep(g/re/p)의 상이형인 *"g/re/s"*이었다. 개별 명령어를 위해 추가적인 특수 목적의 프로그램들이 등장할 것으로 예견하면서 맥마흔은 범용 목적의 라인 지향 스트림 편집기를 작성하였으며, 이것이 sed로 되었다.
**3. sed 개념**
**SED(Stream Editor)**
**SED는 Stream Editor의 약자로 sed라는 명령어로 원본 텍스트 파일을 편집하는 유용한 명령어이다.** 리눅스의 editor라하면 vi 편집기가 대표적인데, 여러분들이 vi편집기로 편집할때는 vi filename의 명령을 이용해서 파일을 열고 난 이후에 각종 vi 명령어를 통해서 이리 저리 움직여 추가, 삭제, 변경 등의 편집을 하게 된다. 그리고 작업이 다 끝나게 되면 저장 후 나가게 된다. 이때 원래의 파일을 변경하여 저장하기 때문에 원본은 변경된다. 그리고 vi는 실시간 저장할 수가 있다. 여기서 sed는 vi 편집기와는 다르게 이런 차이점이 있다.
1. **sed**와 **vi**가 다른 점은 **sed**는 명령어 형태로 편집이 되며 **vi**처럼 실시간 편집이 아니다.
2. **원본을 건드리지 않고 편집**하기 때문에 작업이 완료되었어도 기본적으로 원본에는 전혀 영향이 없다.**(단, sed옵션에서 -i 옵션을 지정한다면 원본을 바꾸게 된다.)** 그래서 내부적으로 특수한 저장 공간인 버퍼를 사용한다. 두 가지 버퍼는 **패턴 버퍼**(패턴 스페이스라고도 합니다)와 **홀드 버퍼**(홀드 스페이스라고도 합니다)입니다.
아래의 그림을 보면 sed는 **InputStream**으로 파일의 내용을 가져온다. 그리고 난 후에 패턴 버퍼에 그 내용을 담고 있으며 데이터의 변형과 추가를 위해 다시 임시 버퍼를 사용하게 되는데, 그게 **홀드 버퍼**이다. 그리고 작업이 전부 완료되었다면 패턴 버퍼에 그 내용이 담기는데, 그 내용을 **OutputStream**으로 보내주게 되면 비로소 원하는 결과가 출력되는것이다. 기본적으로 OutputStream은 콜솔화면인 stdout이다. 우리는 그냥 sed가 내부적으로 2개의 버퍼를 가지고 있다고 보면 된다.

**3. sed 사용 예**
1) 특정 행을 출력 - p (print)
> 전체 내용을 출력 : 기본적으로 전체의 줄을 출력하려면 command에 /$/p 또는 1,$p로 출력해볼 수 있다.
sed -n -e '1,$p' sed_test_file.txt sed -n -e '/$/p' sed_test_file.txt

> 첫번째 줄 출력
sed -n -e '1p' ./sed_test_file.txt

> 1-3 줄 출력
start ~ end 줄까지 출력 : 그렇다면 첫째줄부터 4번째줄을 출력하기를 원한다면 쉼표로 구분된 출력하길 원하는 줄, 마지막 줄 p 의 형태를 사용하면 된다.
sed -n -e '1,4p' sed_test_file.txt

2) 특정 행 삭제 -d (delete)
행삭제에 관한 명령어는 d를 사용하면 된다. d를 사용하는 것외에는 위의 줄 출력을 해주는 명령어 형태로 사용하면 된다.
> 2~6번째 줄을 삭제하고 나머지 모든 내용을 출력sed -n -e '2,6d' -e '1,$p' sed_test_file.txt

3) 단어 치환(Substitute) - s (substitute)
> 단어 s는 **substitute**(치환)의 약자, 그리고 /로 구분하여 old는 단어를 치환할 문자열, new는 새롭게 치환한 문자열인데 비어있으면 그 문자열을 삭제한 효과를 가질 수 있다. g는 global의 약자로 전체에 적용됨을 의미한다.
두번째의 i는 ignore case의 약자로 old의 단어를 검색할때 대소문자 구분하지 않겠다는 것을 의미한다.
아래 명령의 결과를 보고 차이점을 확인.
sed -n -e 's/reakwon/reak/g' -e '2p' sed_test_file.txt sed -n -e 's/reakwoN/reak/g' -e '2p' sed_test_file.txt sed -n -e 's/reakwoN/reak/gi' -e '2p' sed_test_file.txt

### ⅱ)awk 명령어
**1. 역사**
**AWK**는 1977년 Alfred Aho ( egrep의 저자 ), Peter J. Weinberger (작은 관계형 데이터베이스를 작업 했던) 및 *Brian Kernighan*에 의해 처음 개발되었고, 각각의 이니셜에서 이름을 따왔다. *Kernighan*에 따르면 **AWK**의 목표 중 하나는 숫자와 문자열을 모두 쉽게 조작할 수 있는 도구를 만드는 것이었다. **AWK**는 또한 입력 데이터에서 패턴을 검색하는 데 사용 되는 **Marc Rochkind**의 프로그래밍 언어에서 영감을 받았으며 yacc를 사용하여 구현되었다.
**2.awk 개념**
**AWK**(Aho Weinberger Kernighan)
리눅스의 어떤 다른 명령어보다 명령어 이름이 매우 직관적이지 않은 명령어이다. 이 명령어를 개발한 사람들의 이름 약자(Aho Weinberger Kernighan)이기 때문에 mkdir(make directory), rm(remove) 같은 의미를 축약하여 만든 명령어와는 명령어 이름이 다르다. 이 명령어를 읽을때는 주로 오크라고 읽는다. AWK는 유닉스에서 개발된 스크립트 언어로 텍스트가 저장되어 있는 파일을 원하는 대로 필터링하거나 추가해주거나 기타 가공을 통해서 나온 결과를 행과 열로 출력해주는 프로그램이다. 엄청나게 막강하고 다양한 기능을 담고 있다.
그 전에 간단하게 기본 용어를 보자면, 아래는 하나의 텍스트 파일에 기록된 내용을 보여주고 있다. 여기서 각 단어들은 공백으로 구분되어진다. 각 줄(line)은 레코드(Record)라고 칭한다. 그리고 그 안에 각각의 단어들이 필드(Field)가 된다.

AWK에서는 레코드가 $0, 그리고 $1, ..., $N 은 필드를 나타내는 열을 나타냅니다. 우리들이 사용할 파일은 위 내용은 아니고 아래의 내용을 담고 있습니다.
**file : awk_test_file.txt**name phone birth sex score reakwon 010-1234-1234 1981-01-01 M 100 sim 010-4321-4321 1999-09-09 F 88 nara 010-1010-2020 1993-12-12 M 20 yut 010-2323-2323 1988-10-10 F 59 kim 010-1234-4321 1977-07-17 M 69 nam 010-4321-7890 1996-06-20 M 75
1) 열만 출력하기
각 $1, $2, $3 ... 은 열에 대응한다. 그리고 $0는 레코드에 대응한다. 여기서 이름만 모두 출력하겠다고 한다면 아래와 같이 awk 명령을 수행하면 된다.
awk '{ print $1 }' ./awk_test_file.txt
awk '{ print $1,$2 }' ./awk_test_file.txt #여러줄 출력

2) 특정 pattern이 포함된 레코드 출력
다음의 awk 명령은 rea라는 문자열이 포함된 레코드를 출력해주는 명령이다.awk '/rea/' ./awk_test_file.txt

3) 출력의 내용 첨가
awk는 print에 문자열을 추가하여 출력물의 내용에 문자열을 추가할 수 있다. 만약 이름을 명시적으로 나타내기 위해 "name : " , 그리고 휴대폰 번호를 명시적으로 나타내려고 "phone : " 를 추가해서 출력하고 싶다면 아래의 awk 명령을 사용하면 된다.awk '{ print ("name : " $1, ", " "phone : " $2) }' ./awk_test_file.txt
>아래 출력에서 맨 윗줄은 무시하면 된다.

4) 특정 Record를 검색하기 - if 구문
**~이상 , ~ 이하의 레코드 출력**
만약 위의 파일에서 점수가 80점 이상인 사람들의 레코드를 알고 싶다면 어떻게 하면 좋을까? 이거는 pattern을 써야할까요, action을 써야할까? action에서는 if 구문이 존재한다. 그래서 이렇게 사용하면 80점 이상인 record를 출력할 수 있다.awk '{ if ( $5 >= 80 ) print ($0) }' ./awk_test_file.txt

## Ⅲ참고 사이트
[Getopts](https://en.wikipedia.org/wiki/Getopts "Getopts")
[Getopts2](https://mug896.github.io/bash-shell/getopts.html)
[sed](https://en.wikipedia.org/wiki/Sed)
[awk]( https://en.wikipedia.org/wiki/AWK#History )