hadoop-gpu
Koichi Shirahata optimized Hadoop Distribution, especially with high performance of MapReduce with GPGPU.
Here is our paper: Koichi Shirahata, Hitoshi Sato, and Satoshi Matsuoka. "Hybrid Map Task Scheduling for GPU-based Heterogeneous Clusters" In Proceedings of the 1st International Workshop on Theory and Practice of MapReduce (MAPRED'2010), pp. 466-471, Indianapolis, USA, November 2010.
This software modified and includes Hadoop-0.20.1, The Apache Software Foundation
Features:
- Add CPU and GPU hybrid executable feature on Hadoop pipes (in hadoop-gpu-0.20.1/src/mapred/org/apache/hadoop/mapred)
- Add dynamic hybrid task scheduling feature on Hadoop (in hadoop-gpu-0.20.1/src/mapred/org/apache/hadoop/mapred)
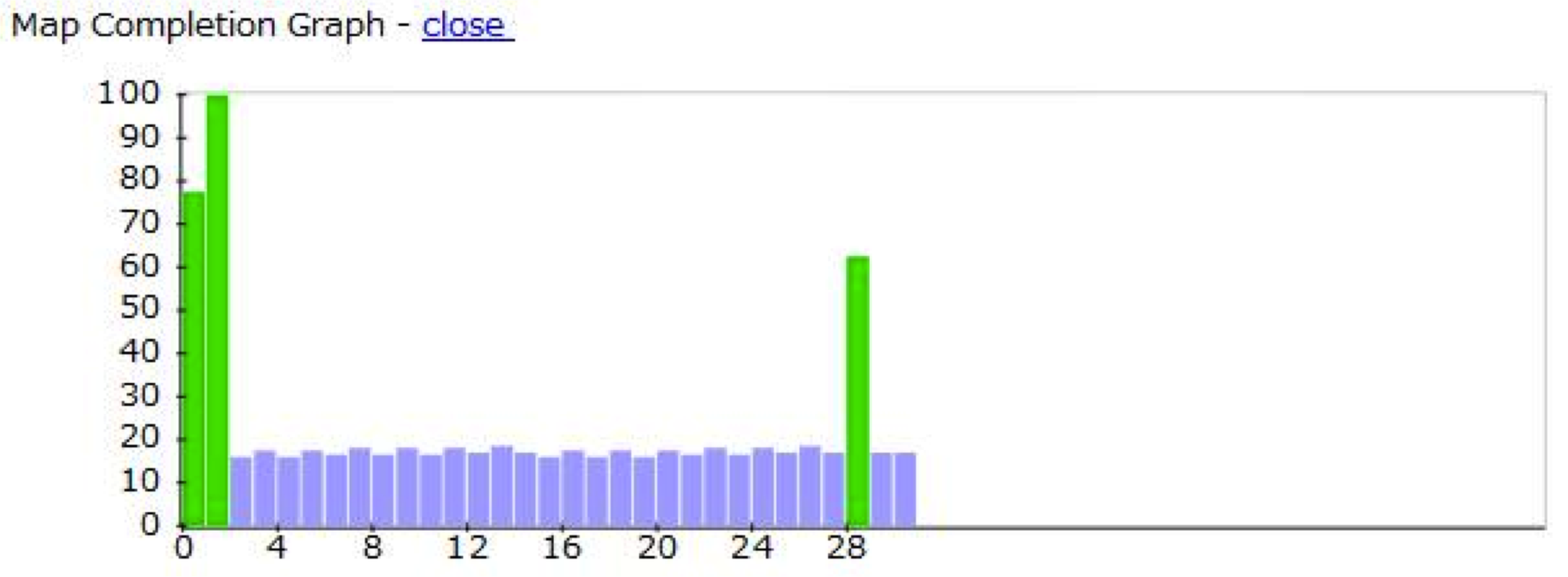
You can watch a demo which shows k-means application is running on both CPU and GPU from the following URL. http://www.youtube.com/watch?v=4CFGR0TFcNA
The image is our customized web interface, in which blue bars show tasks running on CPU, and green bars show tasks running on GPU.
Please read CHANGES.txt to find more detailed modifications.
Installation and Setup
Make sure you have installed CUDA, Java, and ant
Set environment variables
- set HADOOP_HOME to hadoop-gpu-{version} directory
- set JAVA_HOME in $HADOOP_HOME/conf/hadoop-env.sh
- set configuration files (core-site.xml, hdfs-site.xml, mapred-site.xml, masters, slaves),
- specify the number of CPU cores / GPU devices in mapred-site.xml
Build system and apps
-
build hadoop-gpu
$ cd $HADOOP_HOME
$ ant compile -
build apps (show kmeans2D app as an example)
$ cd $HADOOP_HOME/../apps/pipes/kmeans/cpu-kmeans2D
$ make
$ cd $HADOOP_HOME/../apps/pipes/kmeans/gpu-kmeans2D
$ make
Run apps
-
start hadoop-gpu (same as standard hadoop)
$ cd $HADOOP_HOME
$ bin/hadoop namenode -format
$ bin/start-all.sh -
put binary and input files into HDFS
$ bin/hadoop dfs -mkdir bin
$ bin/hadoop dfs -mkdir input
$ bin/hadoop dfs -put $HADOOP_HOME/../apps/pipes/kmeans/cpu-kmeans2D/cpu-kmeans2D bin
$ bin/hadoop dfs -put $HADOOP_HOME/../apps/pipes/kmeans/gpu-kmeans2D/gpu-kmeans2D bin
$ bin/hadoop dfs -put $HADOOP_HOME/../data/kmeans/input2D/ik2_sample input -
run apps (show kmeans2D app as an example)
$ ./kmeans2D.sh input/ik2_sample
or
$ hadoop accel ¥
-D hadoop.pipes.java.recordreader=true ¥
-D hadoop.pipes.java.recordwriter=true ¥
-output output ¥
-cpubin bin/cpu-kmeans ¥
-gpubin bin/gpu-kmeans ¥
-input input/ik2_sample- if you want to run with either single binary, please set the same (cpu or gpu) binary both at cpubin and gpubin
Open Source License
All Koichi Shirahata offered code is licensed under the Apache License, Version 2.0. And others follow the original license announcement.
Copyright
- Copyright (C) 2013 - 2014 Koichi Shirahata All Rights Reserved.