 jonnywilliamson
commented
5 years ago
jonnywilliamson
commented
5 years ago I've spend a few hours on this trying to debug.
I found out that for every job I fired, telescope DID pick it and assign it a UUID.
I found out that the recordProcessedJob method in JobWatcher.php WAS being hit for EVERY job that was processed (but still didn't change from PENDING).
Where everything broke down was here in the DatabaseEntriesRepository.php update function.
https://github.com/laravel/telescope/blob/2.0/src/Storage/DatabaseEntriesRepository.php#L183-L191
When the entry was attempted to be found, IF it was a sub job (ie in my case SendUpdate) it COULD NOT be found, so the $entry variable returned null/false and the method ended.
If the job was the LongJob etc, it was ALWAYS found and so the status was changed successfully.
That's as far as I could go because I don't understand when or how the 'telescope_entries' table gets populated in the entire Telescope app cycle.
It would appear this bug appears when the status update happens before the original entry has had a chance to get saved to the database.
Hope that helps somewhat.
 johnpaulmedina
johnpaulmedina spielfigur
spielfigur amosmos
amosmos damms005
damms005 sadhakbj
sadhakbj stotes
stotes drfraker
drfraker baykier
baykier driesvints
driesvints SilvioDoMine
SilvioDoMine rodrigopedra
rodrigopedra trevorgehman
trevorgehman karlshea
karlshea bram-pkg
bram-pkg ejntaylor
ejntaylor legreco
legreco hose1021
hose1021 Without Horizon
Without Horizon redhedded1
redhedded1 grenaria
grenaria erickneverson
erickneverson adhityairvan
adhityairvan denissceluiko
denissceluiko rforced
rforced
 miaotiao
miaotiao
 isaackearl
isaackearl tuktukvlad
tuktukvlad
@themsaid
So I have seen the previous issues related to this https://github.com/laravel/telescope/issues/507 https://github.com/laravel/telescope/issues/503 https://github.com/laravel/telescope/issues/411
And I'm suffering the same problem. Some of my jobs are reporting as PENDING even though I know they have completed successfully, and also HORIZON shows the same job as being done correctly.
I've spent a lot of time trying to recreate this using as minimal amount of code as possible, and I hope I've succeeded in providing you with an example that will replicate on your system.
Very quickly as an overall picture.
Here's some code.
I have started horizon, and ensured that it is processing jobs from "default" and "broadcast" queues.
Now when I start the whole process job (hitting "/test" in the browser) I'll get the following:
But in horizon it's perfect: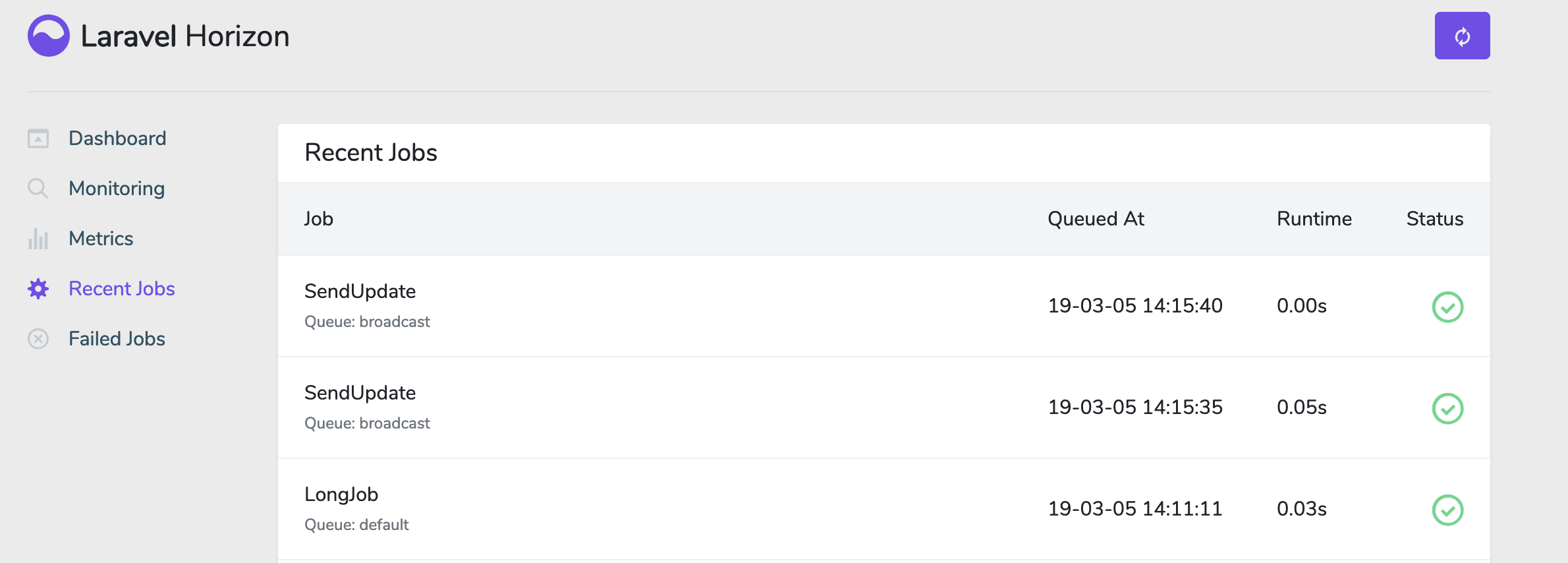
The next post is some info on my debugging attempts.