
What is Milvus?
Milvus is a high-performance vector database built for scale. It is used by AI applications to organize and search through large amount of unstructured data, such as text, images, and multi-modal information.
Milvus is implemented with Go and C++ and employs CPU/GPU instruction-level optimization for best vector search performance. With fully-distributed architecture on K8s, it can handle tens of thousands of search queries on billions of vectors, scale horizontally and maintain data freshness by processing streaming updates in real-time. For smaller use cases, Milvus supports Standalone mode that can run on Docker. In addition, Milvus Lite is a lightweight version suitable for quickstart in python, with simply pip install.
The easiest way to try out Milvus is to use Zilliz Cloud with free trial. Milvus is available as a fully managed service on Zilliz Cloud, with Serverless, Dedicated and BYOC options available.
The Milvus open-source project is under LF AI & Data Foundation, distributed with Apache 2.0 License.
Quickstart
$ pip install -U pymilvusThis installs pymilvus, the Python SDK for Milvus. Use MilvusClient to create a client:
from pymilvus import MilvusClient-
pymilvusalso includes Milvus Lite for quickstart. To create a local vector database, simply instantiate a client with a local file name for persisting data:client = MilvusClient("milvus_demo.db") -
You can also specify the credentials to connect to your deployed Milvus server or Zilliz Cloud:
client = MilvusClient( uri="<endpoint_of_self_hosted_milvus_or_zilliz_cloud>", token="<username_and_password_or_zilliz_cloud_api_key>")
With the client, you can create collection:
client.create_collection(
collection_name="demo_collection",
dimension=768, # The vectors we will use in this demo has 768 dimensions
)Ingest data:
res = client.insert(collection_name="demo_collection", data=data)Perform vector search:
query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?", "What is AI?"])
res = client.search(
collection_name="demo_collection", # target collection
data=query_vectors, # a list of one or more query vectors, supports batch
limit=2, # how many results to return (topK)
output_fields=["vector", "text", "subject"], # what fields to return
)Why Milvus
Milvus is designed to handle vector search at scale. Users can store vectors, which are numerical representations of unstructured data, together with other scalar data types such as integers, strings, and JSON objects, to conduct efficient vector search with metadata filtering or hybrid search. Here are why users choose Milvus as vector database:
High Performance at Scale and High Availability
- Milvus features a distributed architecture that separates compute and storage. Milvus can horizontally scale and adapt to diverse traffic patterns, achieving optimal performance by independently increasing query nodes for read-heavy workload and data node for write-heavy workload. The stateless microservices on K8s allow quick recovery from failure, ensuring high availability. The support for replicas further enhances fault tolerance and throughput by loading data segments on multiple query nodes. See benchmark for performance comparison.
Support for Various Vector Index Types and Hardware Acceleration
- Milvus separates the system and core vector search engine, allowing it to support all major vector index types that are optimized for different scenarios, including HNSW, IVF, FLAT (brute-force), SCANN, and DiskANN, with quantization-based variations and mmap. Milvus optimizes vector search for advanced features such as metadata filtering and range search. Additionally, Milvus implements hardware acceleration to enhance vector search performance and supports GPU indexing, such as NVIDIA's CAGRA.
Flexible Multi-tenancy and Hot/Cold Storage
- Milvus supports multi-tenancy with flexible strategies for organizing data in AI applications such as Retrieval-Augmented Generation (RAG). By using databases, collections, partitions, and partition keys, Milvus can handle hundreds to millions of tenants in a single instance. This helps businesses to save resources while handling many tenant, ensuring data isolation, optimized search performance, and flexible access control. Incorporating hot/cold data storage further enhances cost efficiency and performance. Users can config storing frequently accessed hot data on memory or SSD for better performance while less accessed cold data is kept on cost-effective, slower storage. This separation optimizes resource allocation, reduces costs, and maintains high performance for critical tasks. By combining flexible multi-tenancy with hot/cold storage, Milvus helps businesses scale, optimize resources, and manage data efficiently, leading to significant cost savings while still keep high performance.
Sparse Vector for Full Text Search and Hybrid Search
- Milvus supports full text search with sparse vector. Users can combine sparse vector and dense vector in the same collection, and define functions to rerank results from multiple search requests. For details, refer to Hybrid Search.
Data Security and Fine-grain Access Control
- Milvus ensures data security by implementing mandatory user authentication, TLS encryption, and Role-Based Access Control (RBAC). User authentication ensures that only authorized users with valid credentials can access the database, while TLS encryption secures all communications within the network. Additionally, RBAC allows for fine-grained access control by assigning specific permissions to users based on their roles. These features make Milvus a robust and secure choice for enterprise applications, protecting sensitive data from unauthorized access and potential breaches.
Milvus is trusted by AI developers to build applications such as text and image search, Retrieval-Augmented Generation (RAG), and recommendation systems. Milvus powers many mission-critical business for startups and enterprises.
Demos and Tutorials
Here is a selection of demos and tutorials to show how to build various types of AI applications made with Milvus:
| Tutorial | Use Case | Related Milvus Features |
|---|---|---|
| Build RAG with Milvus | RAG | vector search |
| Multimodal RAG with Milvus | RAG | vector search, dynamic field |
| Image Search with Milvus | Semantic Search | vector search, dynamic field |
| Hybrid Search with Milvus | Hybrid Search | hybrid search, multi vector, dense embedding, sparse embedding |
| Multimodal Search using Multi Vectors | Semantic Search | multi vector, hybrid search |
| Recommender System | Recommendation System | vector search |
| Video Similarity Search | Semantic Search | vector search |
| Audio Similarity Search | Semantic Search | vector search |
| DNA Classification | Classification | vector search |
| Graph RAG with Milvus | RAG | vector search |
| Contextual Retrieval with Milvus | RAG, Semantic Search | vector search |
| HDBSCAN Clustering with Milvus | Clustering | vector search |
| Use ColPali for Multi-Modal Retrieval with Milvus | RAG, Semantic Search | vector search |
| Vector Visualization | Data Visualization | vector search |
|
|
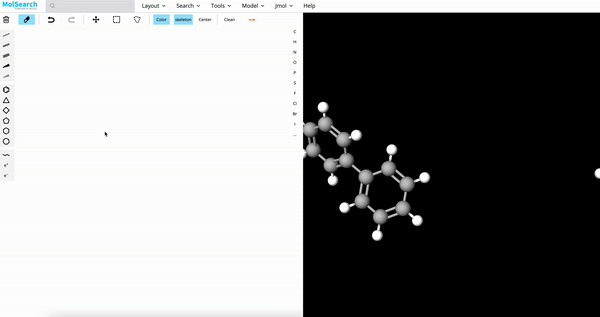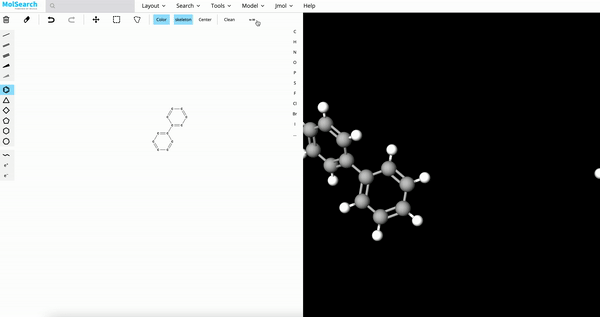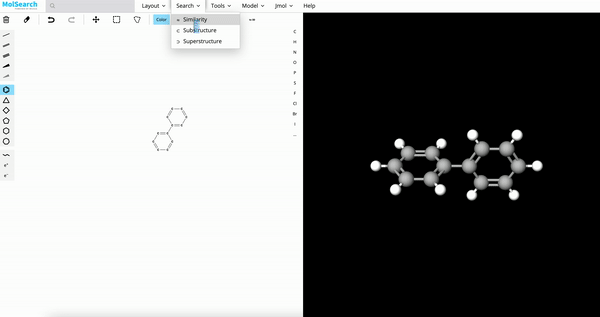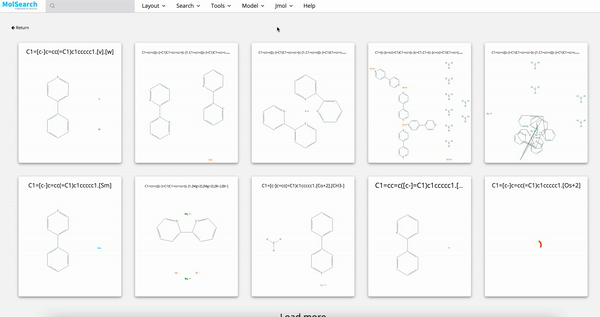
|
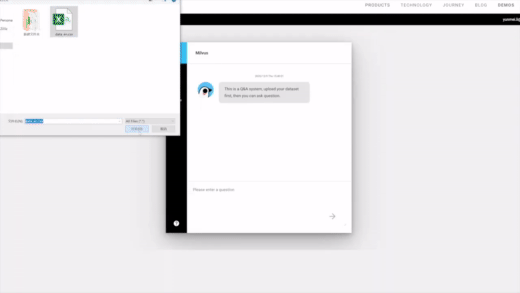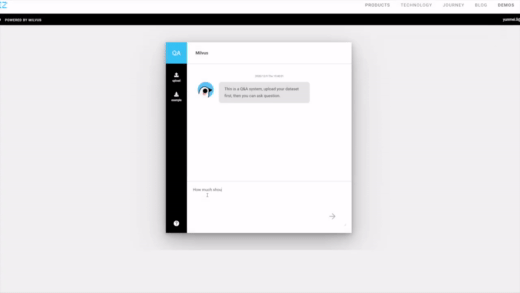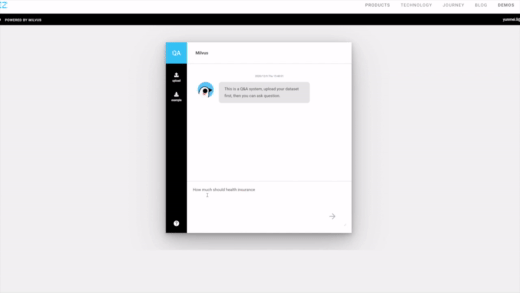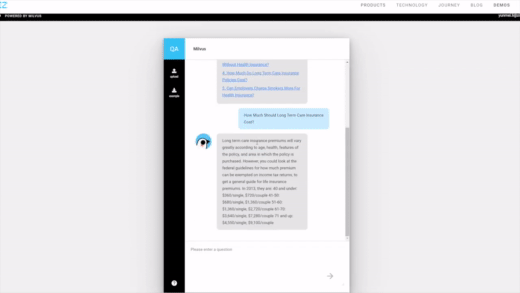
| Image Search | RAG | Drug Discovery |
|---|
Ecosystem and Integration
Milvus integrates with a comprehensive suite of AI development tools, such as LangChain, LlamaIndex, OpenAI and HuggingFace, making it an ideal vector store for GenAI applications such as Retrieval-Augmented Generation (RAG). Milvus works with both open-source embedding models and embedding service, in text, image and video modalities. Milvus also provides a convenient util pymilvus[model], users can use the simple wrapper code to transform unstructured data into vector embeddings and leverage reranking models for optimized search results. The Milvus ecosystem also includes Attu for GUI-based administration, Birdwatcher for system debugging, Prometheus/Grafana for monitoring, Milvus CDC for data synchronization, VTS for data migration and data connectors for Spark, Kafka, Fivetran, and Airbyte to build search pipelines.
Check out https://milvus.io/docs/integrations_overview.md for more details.
Documentation
For guidance on installation, usage, deployment, and administration, check out Milvus Docs. For technical milestones and enhancement proposals, check out issues on GitHub.
Contributing
The Milvus open-source project accepts contribution from everyone. See Guidelines for Contributing for details on submitting patches and the development workflow. See our community repository to learn about project governance and access more community resources.
Build Milvus from Source Code
Requirements:
-
Linux systems (Ubuntu 20.04 or later recommended):
go: >= 1.21 cmake: >= 3.26.4 gcc: 9.5 python: > 3.8 and <= 3.11 -
MacOS systems with x86_64 (Big Sur 11.5 or later recommended):
go: >= 1.21 cmake: >= 3.26.4 llvm: >= 15 python: > 3.8 and <= 3.11 -
MacOS systems with Apple Silicon (Monterey 12.0.1 or later recommended):
go: >= 1.21 (Arch=ARM64) cmake: >= 3.26.4 llvm: >= 15 python: > 3.8 and <= 3.11
Clone Milvus repo and build.
# Clone github repository.
$ git clone https://github.com/milvus-io/milvus.git
# Install third-party dependencies.
$ cd milvus/
$ ./scripts/install_deps.sh
# Compile Milvus.
$ makeFor full instructions, see developer's documentation.
Community
Join the Milvus community on Discord to share your suggestions, advice, and questions with our engineering team.
You can also check out our FAQ page to discover solutions or answers to your issues or questions.
Subscribe to Milvus mailing lists:
Follow Milvus on social media:
Reference
Reference to cite when you use Milvus in a research paper:
@inproceedings{2021milvus,
title={Milvus: A Purpose-Built Vector Data Management System},
author={Wang, Jianguo and Yi, Xiaomeng and Guo, Rentong and Jin, Hai and Xu, Peng and Li, Shengjun and Wang, Xiangyu and Guo, Xiangzhou and Li, Chengming and Xu, Xiaohai and others},
booktitle={Proceedings of the 2021 International Conference on Management of Data},
pages={2614--2627},
year={2021}
}
@article{2022manu,
title={Manu: a cloud native vector database management system},
author={Guo, Rentong and Luan, Xiaofan and Xiang, Long and Yan, Xiao and Yi, Xiaomeng and Luo, Jigao and Cheng, Qianya and Xu, Weizhi and Luo, Jiarui and Liu, Frank and others},
journal={Proceedings of the VLDB Endowment},
volume={15},
number={12},
pages={3548--3561},
year={2022},
publisher={VLDB Endowment}
}

































































































































































































































































































































































































































