TSM: Temporal Shift Module for Efficient Video Understanding [Website] [arXiv][Demo]
@inproceedings{lin2019tsm,
title={TSM: Temporal Shift Module for Efficient Video Understanding},
author={Lin, Ji and Gan, Chuang and Han, Song},
booktitle={Proceedings of the IEEE International Conference on Computer Vision},
year={2019}
} News
-
TSM is featured by MIT News / MIT Technology Review / WIRED / Engadget / NVIDIA News
-
(09/2020) We update the environment setup for the
online_demo, and should be much easier to set up. Check the folder for a try! -
(01/2020) We have released the pre-trained optical flow model on Kinetics. We believe the pre-trained weight will help the training of two-stream models on other datasets.
-
(10/2019) We scale up the training of the TSM model to 1,536 GPUs, finishing Kinetics pre-training in 15 minutes. See tech report here.
-
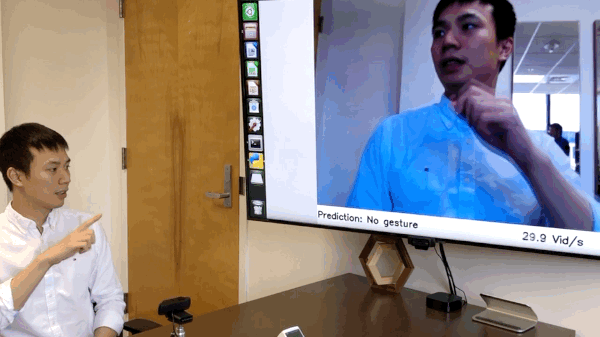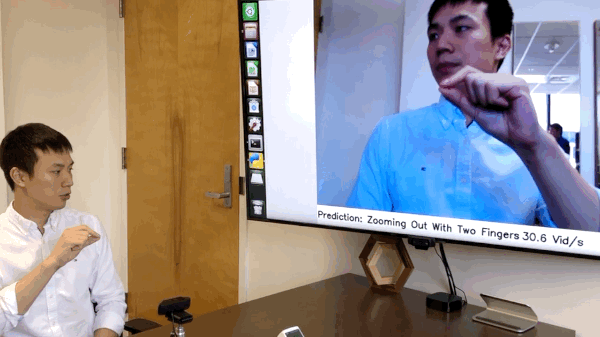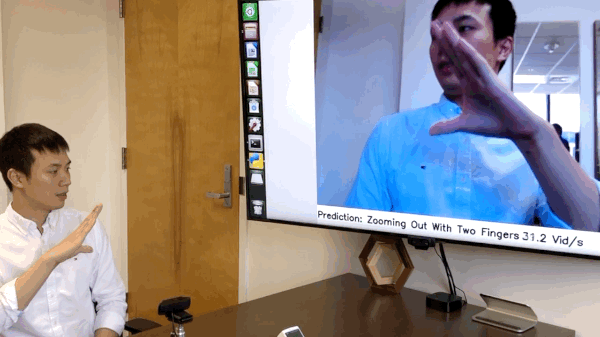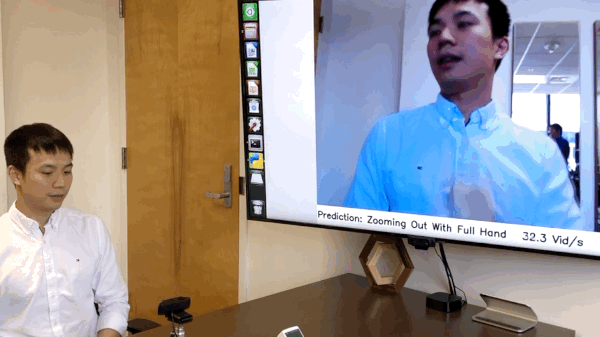
(09/2019) We have released the code of online hand gesture recognition on NVIDIA Jeston Nano. It can achieve real-time recognition at only 8 watts. See
online_demofolder for the details. [Full Video]
Overview
We release the PyTorch code of the Temporal Shift Module.
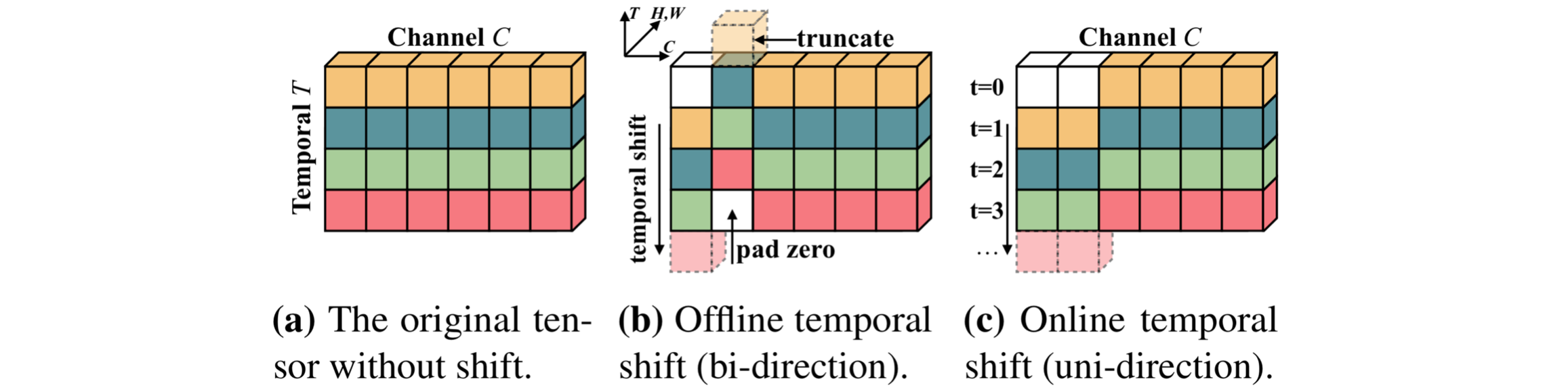
Content
- Prerequisites
- Data Preparation
- Code
- Pretrained Models
- Testing
- Training
- Live Demo on NVIDIA Jetson Nano
Prerequisites
The code is built with following libraries:
- PyTorch 1.0 or higher
- TensorboardX
- tqdm
- scikit-learn
For video data pre-processing, you may need ffmpeg.
Data Preparation
We need to first extract videos into frames for fast reading. Please refer to TSN repo for the detailed guide of data pre-processing.
We have successfully trained on Kinetics, UCF101, HMDB51, Something-Something-V1 and V2, Jester datasets with this codebase. Basically, the processing of video data can be summarized into 3 steps:
- Extract frames from videos (refer to tools/vid2img_kinetics.py for Kinetics example and tools/vid2img_sthv2.py for Something-Something-V2 example)
- Generate annotations needed for dataloader (refer to tools/gen_label_kinetics.py for Kinetics example, tools/gen_label_sthv1.py for Something-Something-V1 example, and tools/gen_label_sthv2.py for Something-Something-V2 example)
- Add the information to ops/dataset_configs.py
Code
This code is based on the TSN codebase. The core code to implement the Temporal Shift Module is ops/temporal_shift.py. It is a plug-and-play module to enable temporal reasoning, at the cost of zero parameters and zero FLOPs.
Here we provide a naive implementation of TSM. It can be implemented with just several lines of code:
# shape of x: [N, T, C, H, W]
out = torch.zeros_like(x)
fold = c // fold_div
out[:, :-1, :fold] = x[:, 1:, :fold] # shift left
out[:, 1:, fold: 2 * fold] = x[:, :-1, fold: 2 * fold] # shift right
out[:, :, 2 * fold:] = x[:, :, 2 * fold:] # not shift
return outNote that the naive implementation involves large data copying and increases memory consumption during training. It is suggested to use the in-place version of TSM to improve speed (see ops/temporal_shift.py Line 12 for the details.)
Pretrained Models
Training video models is computationally expensive. Here we provide some of the pretrained models. The accuracy might vary a little bit compared to the paper, since we re-train some of the models.
Kinetics-400
Dense Sample
In the latest version of our paper, we reported the results of TSM trained and tested with I3D dense sampling (Table 1&4, 8-frame and 16-frame), using the same training and testing hyper-parameters as in Non-local Neural Networks paper to directly compare with I3D.
We compare the I3D performance reported in Non-local paper:
| method | n-frame | Kinetics Acc. |
|---|---|---|
| I3D-ResNet50 | 32 * 10clips | 73.3% |
| TSM-ResNet50 | 8 * 10clips | 74.1% |
| I3D-ResNet50 NL | 32 * 10clips | 74.9% |
| TSM-ResNet50 NL | 8 * 10clips | 75.6% |
TSM outperforms I3D under the same dense sampling protocol. NL TSM model also achieves better performance than NL I3D model. Non-local module itself improves the accuracy by 1.5%.
Here is a list of pre-trained models that we provide (see Table 3 of the paper). The accuracy is tested using full resolution setting following here. The list is keeping updating.
| model | n-frame | Kinetics Acc. | checkpoint | test log |
|---|---|---|---|---|
| TSN ResNet50 (2D) | 8 * 10clips | 70.6% | link | link |
| TSM ResNet50 | 8 * 10clips | 74.1% | link | link |
| TSM ResNet50 NL | 8 * 10clips | 75.6% | link | link |
| TSM ResNext101 | 8 * 10clips | 76.3% | TODO | TODO |
| TSM MobileNetV2 | 8 * 10clips | 69.5% | link | link |
Uniform Sampling
We also provide the checkpoints of TSN and TSM models using uniform sampled frames as in Temporal Segment Networks paper, which is more sample efficient and very useful for fine-tuning on other datasets. Our TSM module improves consistently over the TSN baseline.
| model | n-frame | acc (1-crop) | acc (10-crop) | checkpoint | test log |
|---|---|---|---|---|---|
| TSN ResNet50 (2D) | 8 * 1clip | 68.8% | 69.9% | link | link |
| TSM ResNet50 | 8 * 1clip | 71.2% | 72.8% | link | link |
| TSM ResNet50 | 16 * 1clip | 72.6% | 73.7% | link | - |
Optical Flow
We provide the optical flow model pre-trained on Kinetics. The model is trained using uniform sampling. We did not carefully tune the training hyper-parameters. Therefore, the model is intended for transfer learning on other datasets but not for performance evaluation.
| model | n-frame | top-1 acc | top-5 acc | checkpoint | test log |
|---|---|---|---|---|---|
| TSM ResNet50 | 8 * 1clip | 55.7% | 79.5% | link | - |
Something-Something
Something-Something V1&V2 datasets are highly temporal-related. TSM achieves state-of-the-art performnace on the datasets: TSM achieves the first place on V1 (50.72% test acc.) and second place on V2 (66.55% test acc.), using just ResNet-50 backbone (as of 09/28/2019).
Here we provide some of the models on the dataset. The accuracy is tested using both efficient setting (center crop 1clip) and accuate setting (full resolution 2clip)
Something-Something-V1
| model | n-frame | acc (center crop * 1clip) | acc (full res * 2clip) | checkpoint | test log |
|---|---|---|---|---|---|
| TSM ResNet50 | 8 | 45.6 | 47.2 | link | link1 link2 |
| TSM ResNet50 | 16 | 47.2 | 48.4 | link | link1 link2 |
| TSM ResNet101 | 8 | 46.9 | 48.7 | link | link1 link2 |
Something-Something-V2
On V2 dataset, the accuracy is reported under the accurate setting (full resolution * 2clip).
| model | n-frame | accuracy | checkpoint | test log |
|---|---|---|---|---|
| TSM ResNet50 | 8 * 2clip | 61.2 | link | link |
| TSM ResNet50 | 16 * 2lip | 63.1 | link | link |
| TSM ResNet101 | 8 * 2clip | 63.3 | link | link |
Testing
For example, to test the downloaded pretrained models on Kinetics, you can run scripts/test_tsm_kinetics_rgb_8f.sh. The scripts will test both TSN and TSM on 8-frame setting by running:
# test TSN
python test_models.py kinetics \
--weights=pretrained/TSM_kinetics_RGB_resnet50_avg_segment5_e50.pth \
--test_segments=8 --test_crops=1 \
--batch_size=64
# test TSM
python test_models.py kinetics \
--weights=pretrained/TSM_kinetics_RGB_resnet50_shift8_blockres_avg_segment8_e50.pth \
--test_segments=8 --test_crops=1 \
--batch_size=64Change to --test_crops=10 for 10-crop evaluation. With the above scripts, you should get around 68.8% and 71.2% results respectively.
To get the Kinetics performance of our dense sampling model under Non-local protocol, run:
# test TSN using non-local testing protocol
python test_models.py kinetics \
--weights=pretrained/TSM_kinetics_RGB_resnet50_avg_segment5_e50.pth \
--test_segments=8 --test_crops=3 \
--batch_size=8 --dense_sample --full_res
# test TSM using non-local testing protocol
python test_models.py kinetics \
--weights=pretrained/TSM_kinetics_RGB_resnet50_shift8_blockres_avg_segment8_e100_dense.pth \
--test_segments=8 --test_crops=3 \
--batch_size=8 --dense_sample --full_res
# test NL TSM using non-local testing protocol
python test_models.py kinetics \
--weights=pretrained/TSM_kinetics_RGB_resnet50_shift8_blockres_avg_segment8_e100_dense_nl.pth \
--test_segments=8 --test_crops=3 \
--batch_size=8 --dense_sample --full_resYou should get around 70.6%, 74.1%, 75.6% top-1 accuracy, as shown in Table 1.
For the efficient (center crop and 1 clip) and accurate setting (full resolution and 2 clip) on Something-Something, you can try something like this:
# efficient setting: center crop and 1 clip
python test_models.py something \
--weights=pretrained/TSM_something_RGB_resnet50_shift8_blockres_avg_segment8_e45.pth \
--test_segments=8 --batch_size=72 -j 24 --test_crops=1
# accurate setting: full resolution and 2 clips (--twice sample)
python test_models.py something \
--weights=pretrained/TSM_something_RGB_resnet50_shift8_blockres_avg_segment8_e45.pth \
--test_segments=8 --batch_size=72 -j 24 --test_crops=3 --twice_sampleTraining
We provided several examples to train TSM with this repo:
-
To train on Kinetics from ImageNet pretrained models, you can run
scripts/train_tsm_kinetics_rgb_8f.sh, which contains:# You should get TSM_kinetics_RGB_resnet50_shift8_blockres_avg_segment8_e50.pth python main.py kinetics RGB \ --arch resnet50 --num_segments 8 \ --gd 20 --lr 0.02 --wd 1e-4 --lr_steps 20 40 --epochs 50 \ --batch-size 128 -j 16 --dropout 0.5 --consensus_type=avg --eval-freq=1 \ --shift --shift_div=8 --shift_place=blockres --npbYou should get
TSM_kinetics_RGB_resnet50_shift8_blockres_avg_segment8_e50.pthas downloaded above. Notice that you should scale up the learning rate with batch size. For example, if you use a batch size of 256 you should set learning rate to 0.04. -
After getting the Kinetics pretrained models, we can fine-tune on other datasets using the Kinetics pretrained models. For example, we can fine-tune 8-frame Kinetics pre-trained model on UCF-101 dataset using uniform sampling by running:
python main.py ucf101 RGB \ --arch resnet50 --num_segments 8 \ --gd 20 --lr 0.001 --lr_steps 10 20 --epochs 25 \ --batch-size 64 -j 16 --dropout 0.8 --consensus_type=avg --eval-freq=1 \ --shift --shift_div=8 --shift_place=blockres \ --tune_from=pretrained/TSM_kinetics_RGB_resnet50_shift8_blockres_avg_segment8_e50.pth -
To train on Something-Something dataset (V1&V2), using ImageNet pre-training is usually better:
python main.py something RGB \ --arch resnet50 --num_segments 8 \ --gd 20 --lr 0.01 --lr_steps 20 40 --epochs 50 \ --batch-size 64 -j 16 --dropout 0.5 --consensus_type=avg --eval-freq=1 \ --shift --shift_div=8 --shift_place=blockres --npb
Live Demo on NVIDIA Jetson Nano
We have build an online hand gesture recognition demo using our TSM. The model is built with MobileNetV2 backbone and trained on Jester dataset.
- Recorded video of the live demo [link]
- Code of the live demo and set up tutorial:
online_demo