基于 unidiffusers 的微调(1)—— dreambooth
以 midjourney 和 stable diffusion 为代表的图像生成取得了很好的效果,图像生成进入一个更为火热的时期。 unidiffusers 是国产领先的图像生成算法,是由清华大学朱军老师团队创造。dreambooth 是对图像生成模型在少量图片上进行微调,以很少的训练成本,满足用户个性化的需求。
下面将简要介绍下 unidiffusers 模型框架,以及 dreambooth 算法(了解更多的细节,读者可以仔细阅读原论文和官方代码),并且在 unidiffusers 模型上实现 dreambooth 方法,实验代码放在 .
一, unidiffusers 简介
unidiffusers 在一个算法框架下实现了多个生成任务,包括文本生成( t ),图片生成( i ),文本图片联合生成( joint ),基于图片生成文本( i2t ),基于文本生成图片( t2i ). 在这里,我们主要关注基于文本生成图片的任务。
unidiffusers 模型主要可以分成几个部分:
- vae 图像变分自编码器,主要将图片编码成隐变量,和将隐变量解码成图片。
- image_encoder 是一个 CLIP 的图像编码器,主要编码图像的语义特征。
- text_encoder 是一个 CLIP 的文本编码器,主要编码输入prompt的语义。
- unet 是 unidiffusers 的扩散模型,她的输入是图像隐变量(将vae编码的图像特征和image_encoder 的图像特征拼接得来),文本的特征(prompt 经过 text_encoder 得来),以及 timestamp .
在文本生成图像时,有一个 guidance_scale 值得注意,unet 模型最终输出结果是带 prompt 信息的预测结果和不带 prompt 信息的预测结果的带系数求和。而 guidance_scale 和 1-guidance_scale 则是这两个预测结果的系数。 以下是 unidiffusers 的扩散模型 unet 的图示:
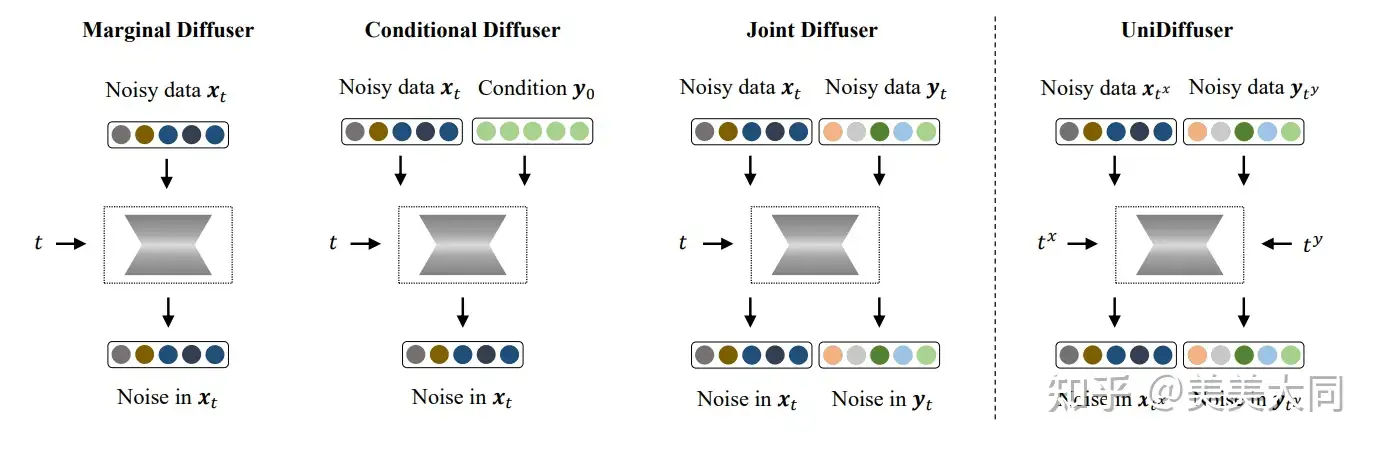
二, dreambooth 简介
dreambooth 主要是对文本生成图片模型进行微调,它使用户可以用几张个性化的图片(比如个人照片,自家宠物照片),以很少的训练成本就可以训练一个专属的模型。
对于这一组个性化的图片,首先需要定义一个专属的 prompt,比如 a [V] dog, [V] 是一个罕见没有什么含义的符号组合。在训练的过程中,首先用文本编码器 text_encoder 提取这个专属 prompt 的文本特征,然后用图像编码器提取图片的特征,以文本特征,图像特征,timestamp 作为扩散模型的输入,输出是当前时刻的噪声。
在实验过程中,除了扩散模型 unet 训练之外,文本编码器 text_encoder 可以固定,也可以参与训练。
为了防止过拟合,在训练过程中,可以先用模型生成与专属图片类别相似的图片,将这些生成图片和相应的 prompt 加入到模型的训练过程中。 dreambooth 的算法如下图所示。
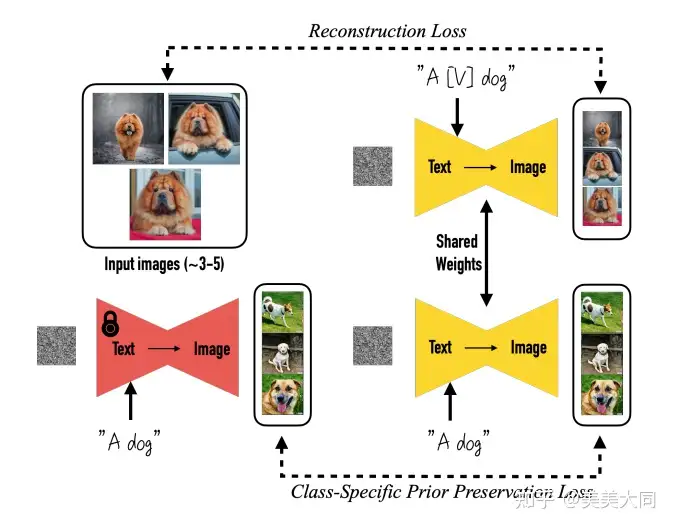
三, 代码与实验
3.1 实验介绍
本部分实验代码放在 https://github.com/mmdatong/unidiffusers-finetune . 实验的显存占用为 28GB 左右,需要在 v100 机器上进行训练。
本部分的实验主要基于开源代码 diffusers,尤其是 train_dreambooth.py 和 UniDiffuserPipeline .
实验使用 5 张狗的图片就行训练,训练 prompt 定义为 a photo of sks dog。
3.2 实验操作
a. 安装环境
git clone https://github.com/huggingface/diffusers/
cd diffusers
python setup.py install
pip install xformers==0.0.16
pip install triton
git clone https://github.com/mmdatong/unidiffusers-finetune/
cd unidiffusers-finetune/dreambooth
pip install -r requirements.txt
accelarate config default
b. 训练脚本
export MODEL_NAME="thu-ml/unidiffuser-v1"
export INSTANCE_DIR="dog"
export OUTPUT_DIR="outputs"
accelerate launch main.py \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--model_id_or_path $MODEL_NAME \
--output_dir=$OUTPUT_DIR \
--lr_warmup_steps=0 \
--max_train_steps=1500 \
--train_text_encoder
这里如果去掉 --train_text_encoder,则只训练 unet 部分,否则同时训练 unet 和 text_encoder。
c. 推断脚本
python infer.py
d. 实验效果
以下是只训练 unet 部分,不同 epoch 下模型的生成图片(100, 200, 300 epoch)。



四, 后续
- 显存优化,使用 lora 等技巧,减少显存占用,在24GB 以内显卡上实验。
- 同时微调 unet 和 text_encoder
- 加入正则化损失( Class-specific Prior Preservation Loss)
- 对比试验比较
- ... (敬请关注)
参考资料
[1] One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale https://arxiv.org/pdf/2303.06555.pdf
[2] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation https://arxiv.org/pdf/2208.12242.pdf
[3] https://github.com/huggingface/diffusers/tree/main/examples/dreambooth