ChatGPT 
ChatGPT playwright api,not openai api
一个不怎么使用网页的ChatGPT playwright api
待填坑 feature
- [x] 使用网页版 chatgpt | use chatgpt
- [x] 多人格预设与切换 | Multiple personality presets and switching
- [x] 聊天记录存储与导出 | Chat history storage and export
- [x] 自定义人设 | Customized persona
- [x] 重置聊天或回到某一时刻 | Reset a chat or go back to a certain moment
- [x] 多账号并发聊天 | Concurrent chatting with multiple accounts
- [x] 使用账号登录(暂不支持苹果)| Log in with your account (Apple is not supported yet)
- [x] GPT4 and PLUS
- [x] GPT4 upload file
- [ ] GPT4 download file
- [ ] 代码过于混乱等优化 | The code is too confusing and other optimizations
- [ ] 抽空完善readme | Take the time to improve the readme
安装/Install
linux & Windows
pip install ChatGPTWeb
playwright install firefoxMsgData() 数据类型
from ChatGPTWeb.config import MsgData
class MsgData():
status: bool = False,
msg_type: typing.Optional[typing.Literal["old_session","back_loop","new_session"]] = "new_session",
msg_send: str = "hi",
# your msg
gpt_model: typing.Literal["text-davinci-002-render-sha", "gpt-4", "gpt-4o"] = "text-davinci-002-render-sha",
# if you use gpt4o by gptplus
msg_recv: str = "",
# gpt's msg
conversation_id: str = "",
# old session's conversation_id
p_msg_id: str = "",
# p_msg_id : the message's parent_message_id in this conversation id / 这个会话里某条消息的 parent_message_id
next_msg_id: str = "",
post_data: str = ""
arkose_data: str = "",
arkose_header: dict[str,str] = {},
arkose: str|None = ""
# if chatgpt use arkose简单使用 / Simple practice
copy main.py or this code to start / 复制 main.py 或者以下code来开始
import asyncio
from ChatGPTWeb import chatgpt
from ChatGPTWeb.config import Personality, MsgData
import aioconsole
sessions = [
{
"session_token": ""
},
{
"email": "xxx@hotmail.com",
"password": "",
# "mode":"openai" ,
"session_token": "",
},
{
"email": "xxx@outlook.com",
"password": "",
"mode": "microsoft",
"help": "xxxx@xx.com"
},
{
"email": "xxx@gmail.com",
"password": "",
"mode": "google"
},
,
{
"email": "xxx@hotmail.com",
"password": "",
"gptplus": True
}
]
# please remove account if u don't have | 请删除你不需要的登录方式
# if you only use session_token, automatic login after expiration is not supported | 仅使用session_token登录的话,不支持过期后的自动登录
# if you use an openai account to log in,
# pleases manually obtain the session_token in advance and add it together to reduce the possibility of openai verification
# 使用openai账号登录的话,请提前手动获取 session_token并一同添加,降低 openai 验证的可能性
personality_definition = Personality(
[
{
"name": "Programmer",
'value': 'You are python Programmer'
},
])
chat = chatgpt(sessions=sessions, begin_sleep_time=False, headless=True, stdout_flush=True)
# "begin_sleep_time=False" for testing only
# Make sure "headless=True" when using
async def main():
c_id = await aioconsole.ainput("your conversation_id if you have:")
# if u don't have,pleases enter empty
p_id = await aioconsole.ainput("your parent_message_id if you have:")
# if u don't have,pleases enter empty
data:MsgData = MsgData(conversation_id=c_id,p_msg_id=p_id)
while 1:
print("------------------------------")
data.msg_send = await aioconsole.ainput("input:")
print("------------------------------")
if data.msg_send == "quit":
break
elif data.msg_send == "gpt4o":
if data.gpt_model != "gpt-4o":
data.gpt_model = "gpt-4o"
data.conversation_id = ""
data.p_msg_id = ""
data.msg_send = await aioconsole.ainput("reinput:")
if data.msg_send == "what's the png":
with open("1.png","rb") as f:
file = IOFile(
content=f.read(),
name="1.png"
)
data.upload_file.append(file)
elif data.msg_send == "gpt3.5":
if data.gpt_model != "text-davinci-002-render-sha":
data.gpt_model = "text-davinci-002-render-sha"
data.conversation_id = ""
data.p_msg_id = ""
data.msg_send = await aioconsole.ainput("reinput:")
elif data.msg_send == "re":
data.msg_type = "back_loop"
data.p_msg_id = await aioconsole.ainput("your parent_message_id if you go back:")
elif data.msg_send == "reset":
data = await chat.back_init_personality(data)
print(f"ChatGPT:{data.msg_recv}")
continue
elif data.msg_send == "init_personality":
data.msg_send = "your ..."
data = await chat.init_personality(data)
print(f"ChatGPT:{data.msg_recv}")
continue
elif data.msg_send == "history":
print(await chat.show_chat_history(data))
continue
elif data.msg_send == "status":
print(await chat.token_status())
continue
data = await chat.continue_chat(data)
if data.msg_recv == '':
print(f"error:{data.error_info}")
else:
print(f"ChatGPT:{data.msg_recv}")
data.error_info = ""
data.msg_recv = ""
data.p_msg_id = ""
loop = asyncio.get_event_loop()
loop.run_until_complete(main()) chatgpt 类参数 / class chatgpt parameters
sessions: list[dict] = [],
# 参考 简单使用 ,暂不支持苹果账号,不写mode默认为openai账号
# Refer to Simple practice. Apple accounts are not supported for the time being.
# If you do not write "mode", the default is openai account.
proxy: typing.Optional[str] = None,
# proxy = "http://127.0.0.1:1090"
# proxy = "http://user:pass@127.0.0.1:1090"
# chatgpt(proxy=proxy)
# 要用代理的话就像这样 | proxy like it if u need use
chat_file: Path = Path("data", "chat_history", "conversation"),
# 聊天记录保存位置,一般不需修改
# The location where the chat history is saved, generally does not need to be modified.
personality: Optional[Personality] = Personality([{"name": "cat", "value": "you are a cat now."}]),
# 默认人格,用于初始化,推荐你使用类方法去添加你个人使用的
# The default personality is used for initialization. It is recommended that you use class methods to add your own personal
log_status: bool = True,
# 是否启用日志,默认开启,推荐在使用__main__.py进行测试时关闭
# Whether to enable logging. It is enabled by default. It is recommended to turn it off when using __main__.py for testing.
plugin: bool = False,
# 是否作为一个nonebot2插件使用(其实是插入进一个已经创建了的协程程序里)
# Whether to use it as a nonebot2 plug-in (actually inserted into an already created coroutine program)
headless: bool = True,
# 无头浏览器模式 | Headless browser mode
begin_sleep_time: bool = True,
# 启动时的随即等待时间,默认开启,推荐仅在少量账号测试时关闭
# The immediate waiting time at startup is enabled by default. It is recommended to turn it off only when testing with a small number of accounts.
logger_level: Literal["DEBUG", "INFO", "WARNING", "ERROR"] = "INFO"
# 日志等级,默认INFO
# logger_level
stdout_flush: bool = False
# shell流式传输
# command shell refresh output
chatgpt 类方法 / class chatgpt method
chat = chatgpt(sessions=sessions)async def continue_chat(self, msg_data: MsgData) -> MsgData
# 聊天处理入口,一般用这个
# Message processing entry, please use this
msg_data = MsgData()
msg_data.msg_send = "your msg"
msg_data = await chat.continue_chat(msg_data)
print(msg_data.msg_recv) async def show_chat_history(self, msg_data: MsgData) -> list
# 获取保存的聊天记录
# Get saved chat history
msg_data = MsgData()
msg_data.conversation_id = You want to read the conversation_id of the record | 你想要读取记录的conversation_id
chat_history_list:list = await chat.show_chat_history(msg_data) async def back_chat_from_input(self, msg_data: MsgData) -> MsgData
# You can enter the text that appeared last time, or the number of dialogue rounds starts from 1 , or p_msg_id
# 通过输入来回溯,你可以输入最后一次出现过的文字,或者对话回合序号(从1开始),或者最后一次出现在聊天中的关键词,或者 p_msg_id
# Note: backtracking will not reset the recorded chat files,
# please pay attention to whether the content displayed in the chat records exists when backtracking again
# 注意:回溯不会重置记录的聊天文件,请注意再次回溯时聊天记录展示的内容是否存在
msg_data = MsgData()
...
msg_data.msg_send = "pleases call me Tom"
# 如果这是第5条消息 | If this is the 5th message
...
# 通过序号 | by index
msg_data.msg_send = "5"
# 通过关键词 | by keyword
msg_data.msg_send = "Tom"
msg_data.conversation_id = "xxx"
msg_data = await chat.back_chat_from_input(msg_data)async def init_personality(self, msg_data: MsgData) -> MsgData
# 使用指定的人设创建一个新会话
# Create a new conversation with the specified persona
msg_data = MsgData()
person_name = "你保存的人设名|Your saved persona name"
msg_data.msg_send = person_name
msg_data = await chat.init_personality(msg_data)
print(msg_data.msg_recv)async def back_init_personality(self, msg_data: MsgData) -> MsgData
# 回到刚初始化人设之后
# Go back to just after initializing the character settings
msg_data = MsgData()
msg_data.conversation_id = "xxx"
msg_data = await chat.back_init_personality()
print(msg_data.msg_recv)async def add_personality(self, personality: dict)
# add personality,please input json just like this.
# 添加人格 ,请传像这样的json数据
personality: dict = {"name":"cat1","value":"you are a cat now1."}
await chat.add_personality(personality)async def show_personality_list(self) -> str
# show_personality_list | 展示人格列表
name_list: str = await chat.show_personality_list()async def del_personality(self, name: str) -> str
# del_personality by name | 删除人格根据名字
pserson_name = "xxx"
name_list: str = await chat.del_personality(person_name)async token_status(self) -> dict
# get work status|查看session token状态和工作状态
status: dict = await chat.token_status()
# cid_num may not match the number of sessions, because it only records sessions with successful sessions, which will be automatically resolved after a period of time.
# cid_num 可能和session数量对不上,因为它只记录会话成功的session,这在允许一段时间后会自动解决在协程中使用 | use in Coroutine
chat = chatgpt(sessions=sessions, begin_sleep_time=False, headless=True, log_status=False, plugin=True)
async def any_async_method():
loop = asyncio.get_event_loop()
asyncio.run_coroutine_threadsafe(chat.__start__(loop),loop)手动获取 session_token 的方法 | How to manually obtain session_token
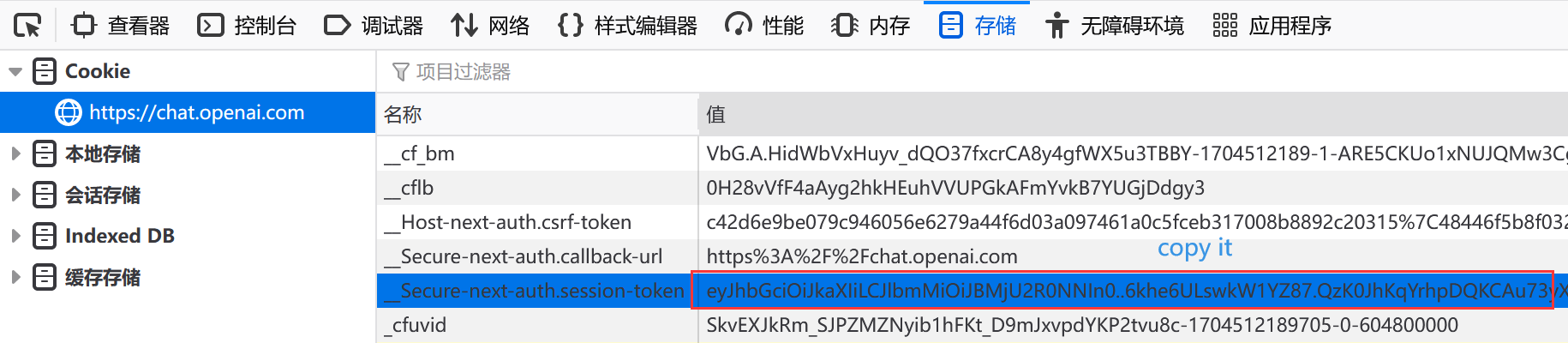
After opening chat.openai.com and logging in, press F12 on the browser to open the developer tools and find the following cookies
打开chat.openai.com登录后,按下浏览器的F12以打开开发者工具,找到以下Cookie
可能遇到的问题 | possible problems
微软登录辅助邮箱验证 | microsoft email verify code
A file will be generated in the startup directory. Please put the verification code into it and save it. Pay attention to the log prompts.
启动目录下会生成文件,请将验证码放入其中并保存,注意日志提示
谷歌登录 | google login
Please log in to chatgpt manually using Google from your browser once, then visit https://myaccount.google.com/ and use the browser plug-in Cookie-Editor to export the cookies of this page in json format.
When the "{email_address}_google_cookie.txt" file appears, paste the copied json into it and save it.
请先从你的浏览器手动使用google登录chatgpt一次,然后访问https://myaccount.google.com/,使用浏览器插件Cookie-Editor导出该页面的Cookie为json格式。 当"{email_address}_google_cookie.txt"文件出现时,将复制的json粘贴进去并保存。