![]()
Scale Efficiently: Evaluate and Optimize Your LLM Deployments for Real-World Inference
[](https://github.com/neuralmagic/guidellm/releases) [](https://github.com/neuralmagic/guidellm/tree/main/docs) [](https://github.com/neuralmagic/guidellm/blob/main/LICENSE) [](https://pypi.python.org/pypi/guidellm) [](https://pypi.python.org/pypi/guidellm-nightly) [](https://pypi.python.org/pypi/guidellm) [](https://github.com/neuralmagic/guidellm/actions/workflows/nightly.yml) ## Overview

 Notes:
- The `--target` flag specifies the server hosting the model. In this case, it is a local vLLM server.
- The `--model` flag specifies the model to evaluate. The model name should match the name of the model deployed on the server
- By default, GuideLLM will run a `sweep` of performance evaluations across different request rates, each lasting 120 seconds and the results are printed out to the terminal.
#### 3. Analyze the Results
After the evaluation is completed, GuideLLM will summarize the results, including various performance metrics.
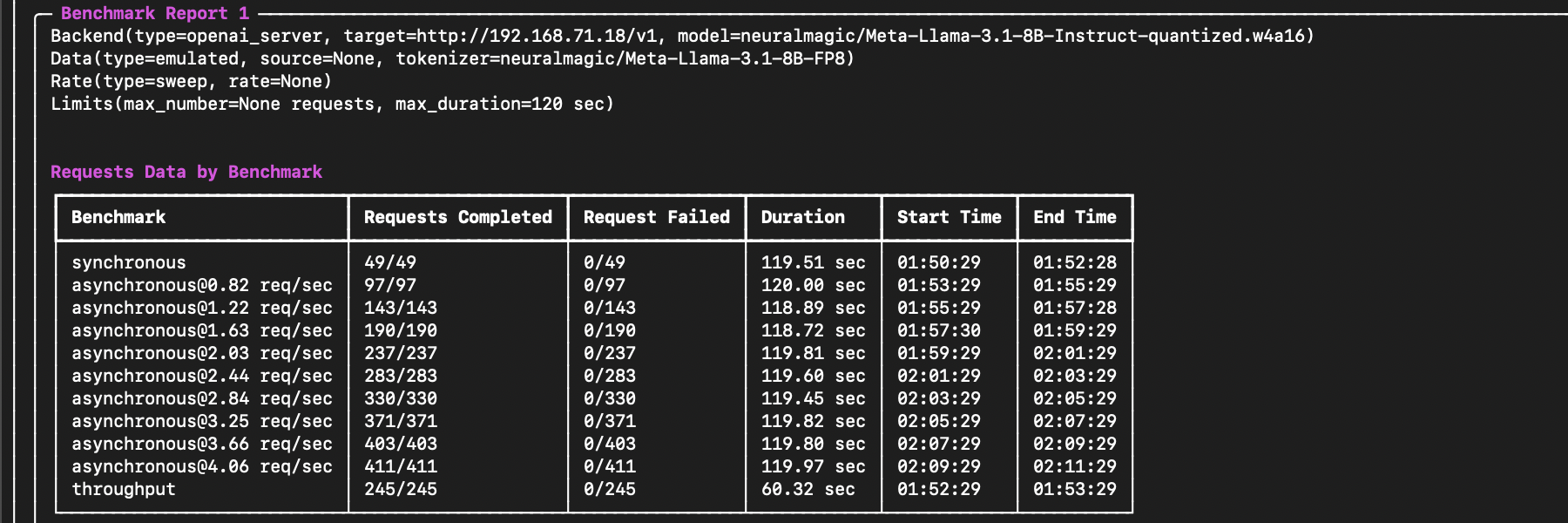
The output results will start with a summary of the evaluation, followed by the requests data for each benchmark run. For example, the start of the output will look like the following:
Notes:
- The `--target` flag specifies the server hosting the model. In this case, it is a local vLLM server.
- The `--model` flag specifies the model to evaluate. The model name should match the name of the model deployed on the server
- By default, GuideLLM will run a `sweep` of performance evaluations across different request rates, each lasting 120 seconds and the results are printed out to the terminal.
#### 3. Analyze the Results
After the evaluation is completed, GuideLLM will summarize the results, including various performance metrics.
The output results will start with a summary of the evaluation, followed by the requests data for each benchmark run. For example, the start of the output will look like the following:
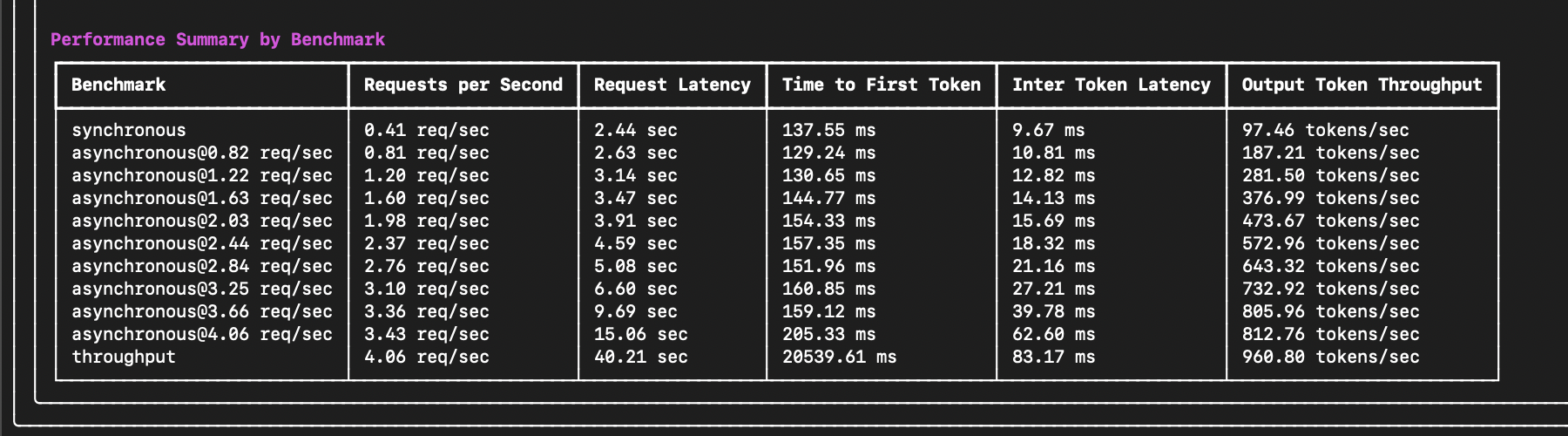
 The end of the output will include important performance summary metrics such as request latency, time to first token (TTFT), inter-token latency (ITL), and more:
The end of the output will include important performance summary metrics such as request latency, time to first token (TTFT), inter-token latency (ITL), and more:
 #### 4. Use the Results
The results from GuideLLM are used to optimize your LLM deployment for performance, resource efficiency, and cost. By analyzing the performance metrics, you can identify bottlenecks, determine the optimal request rate, and select the most cost-effective hardware configuration for your deployment.
For example, if we deploy a latency-sensitive chat application, we likely want to optimize for low time to first token (TTFT) and inter-token latency (ITL). A reasonable threshold will depend on the application requirements. Still, we may want to ensure time to first token (TTFT) is under 200ms and inter-token latency (ITL) is under 50ms (20 updates per second). From the example results above, we can see that the model can meet these requirements on average at a request rate of 2.37 requests per second for each server. If you'd like to target a higher percentage of requests meeting these requirements, you can use the **Performance Stats by Benchmark** section to determine the rate at which 90% or 95% of requests meet these requirements.
If we deploy a throughput-sensitive summarization application, we likely want to optimize for the maximum requests the server can handle per second. In this case, the throughput benchmark shows that the server maxes out at 4.06 requests per second. If we need to handle more requests, consider adding more servers or upgrading the hardware configuration.
### Configurations
GuideLLM provides various CLI and environment options to customize evaluations, including setting the duration of each benchmark run, the number of concurrent requests, and the request rate.
Some typical configurations for the CLI include:
- `--rate-type`: The rate to use for benchmarking. Options include `sweep`, `synchronous`, `throughput`, `constant`, and `poisson`.
- `--rate-type sweep`: (default) Sweep runs through the full range of the server's performance, starting with a `synchronous` rate, then `throughput`, and finally, 10 `constant` rates between the min and max request rate found.
- `--rate-type synchronous`: Synchronous runs requests synchronously, one after the other.
- `--rate-type throughput`: Throughput runs requests in a throughput manner, sending requests as fast as possible.
- `--rate-type constant`: Constant runs requests at a constant rate. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- `--rate-type poisson`: Poisson draws from a Poisson distribution with the mean at the specified rate, adding some real-world variance to the runs. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- `--data-type`: The data to use for the benchmark. Options include `emulated`, `transformers`, and `file`.
- `--data-type emulated`: Emulated supports an EmulationConfig in string or file format for the `--data` argument to generate fake data. Specify the number of prompt tokens at a minimum and optionally the number of output tokens and other parameters for variance in the length. For example, `--data "prompt_tokens=128"`, `--data "prompt_tokens=128,generated_tokens=128" `, or `--data "prompt_tokens=128,prompt_tokens_variance=10" `.
- `--data-type file`: File supports a file path or URL to a file for the `--data` argument. The file should contain data encoded as a CSV, JSONL, TXT, or JSON/YAML file with a single prompt per line for CSV, JSONL, and TXT or a list of prompts for JSON/YAML. For example, `--data "data.txt"` where data.txt contents are `"prompt1\nprompt2\nprompt3"`.
- `--data-type transformers`: Transformers supports a dataset name or file path for the `--data` argument. For example, `--data "neuralmagic/LLM_compression_calibration"`.
- `--max-seconds`: The maximum number of seconds to run each benchmark. The default is 120 seconds.
- `--max-requests`: The maximum number of requests to run in each benchmark.
For a complete list of supported CLI arguments, run the following command:
```bash
guidellm --help
```
For a full list of configuration options, run the following command:
```bash
guidellm-config
```
See the [GuideLLM Documentation](#Documentation) for further information.
## Resources
### Documentation
Our comprehensive documentation provides detailed guides and resources to help you get the most out of GuideLLM. Whether just getting started or looking to dive deeper into advanced topics, you can find what you need in our [full documentation](https://github.com/neuralmagic/guidellm/tree/main/docs).
### Core Docs
- [**Installation Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/install.md) - This guide provides step-by-step instructions for installing GuideLLM, including prerequisites and setup tips.
- [**Architecture Overview**](https://github.com/neuralmagic/guidellm/tree/main/docs/architecture.md) - A detailed look at GuideLLM's design, components, and how they interact.
- [**CLI Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/cli.md) - Comprehensive usage information for running GuideLLM via the command line, including available commands and options.
- [**Configuration Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/configuration.md) - Instructions on configuring GuideLLM to suit various deployment needs and performance goals.
### Supporting External Documentation
- [**vLLM Documentation**](https://vllm.readthedocs.io/en/latest/) - Official vLLM documentation provides insights into installation, usage, and supported models.
### Releases
Visit our [GitHub Releases page](https://github.com/neuralmagic/guidellm/releases) and review the release notes to stay updated with the latest releases.
### License
GuideLLM is licensed under the [Apache License 2.0](https://github.com/neuralmagic/guidellm/blob/main/LICENSE).
## Community
### Contribute
We appreciate contributions to the code, examples, integrations, documentation, bug reports, and feature requests! Your feedback and involvement are crucial in helping GuideLLM grow and improve. Below are some ways you can get involved:
- [**DEVELOPING.md**](https://github.com/neuralmagic/guidellm/blob/main/DEVELOPING.md) - Development guide for setting up your environment and making contributions.
- [**CONTRIBUTING.md**](https://github.com/neuralmagic/guidellm/blob/main/CONTRIBUTING.md) - Guidelines for contributing to the project, including code standards, pull request processes, and more.
- [**CODE_OF_CONDUCT.md**](https://github.com/neuralmagic/guidellm/blob/main/CODE_OF_CONDUCT.md) - Our expectations for community behavior to ensure a welcoming and inclusive environment.
### Join
We invite you to join our growing community of developers, researchers, and enthusiasts passionate about LLMs and optimization. Whether you're looking for help, want to share your own experiences, or stay up to date with the latest developments, there are plenty of ways to get involved:
- [**Neural Magic Community Slack**](https://neuralmagic.com/community/) - Join our Slack channel to connect with other GuideLLM users and developers. Ask questions, share your work, and get real-time support.
- [**GitHub Issues**](https://github.com/neuralmagic/guidellm/issues) - Report bugs, request features, or browse existing issues. Your feedback helps us improve GuideLLM.
- [**Subscribe to Updates**](https://neuralmagic.com/subscribe/) - Sign up for the latest news, announcements, and updates about GuideLLM, webinars, events, and more.
- [**Contact Us**](http://neuralmagic.com/contact/) - Use our contact form for general questions about Neural Magic or GuideLLM.
### Cite
If you find GuideLLM helpful in your research or projects, please consider citing it:
```bibtex
@misc{guidellm2024,
title={GuideLLM: Scalable Inference and Optimization for Large Language Models},
author={Neural Magic, Inc.},
year={2024},
howpublished={\url{https://github.com/neuralmagic/guidellm}},
}
```
#### 4. Use the Results
The results from GuideLLM are used to optimize your LLM deployment for performance, resource efficiency, and cost. By analyzing the performance metrics, you can identify bottlenecks, determine the optimal request rate, and select the most cost-effective hardware configuration for your deployment.
For example, if we deploy a latency-sensitive chat application, we likely want to optimize for low time to first token (TTFT) and inter-token latency (ITL). A reasonable threshold will depend on the application requirements. Still, we may want to ensure time to first token (TTFT) is under 200ms and inter-token latency (ITL) is under 50ms (20 updates per second). From the example results above, we can see that the model can meet these requirements on average at a request rate of 2.37 requests per second for each server. If you'd like to target a higher percentage of requests meeting these requirements, you can use the **Performance Stats by Benchmark** section to determine the rate at which 90% or 95% of requests meet these requirements.
If we deploy a throughput-sensitive summarization application, we likely want to optimize for the maximum requests the server can handle per second. In this case, the throughput benchmark shows that the server maxes out at 4.06 requests per second. If we need to handle more requests, consider adding more servers or upgrading the hardware configuration.
### Configurations
GuideLLM provides various CLI and environment options to customize evaluations, including setting the duration of each benchmark run, the number of concurrent requests, and the request rate.
Some typical configurations for the CLI include:
- `--rate-type`: The rate to use for benchmarking. Options include `sweep`, `synchronous`, `throughput`, `constant`, and `poisson`.
- `--rate-type sweep`: (default) Sweep runs through the full range of the server's performance, starting with a `synchronous` rate, then `throughput`, and finally, 10 `constant` rates between the min and max request rate found.
- `--rate-type synchronous`: Synchronous runs requests synchronously, one after the other.
- `--rate-type throughput`: Throughput runs requests in a throughput manner, sending requests as fast as possible.
- `--rate-type constant`: Constant runs requests at a constant rate. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- `--rate-type poisson`: Poisson draws from a Poisson distribution with the mean at the specified rate, adding some real-world variance to the runs. Specify the request rate per second with the `--rate` argument. For example, `--rate 10` or multiple rates with `--rate 10 --rate 20 --rate 30`.
- `--data-type`: The data to use for the benchmark. Options include `emulated`, `transformers`, and `file`.
- `--data-type emulated`: Emulated supports an EmulationConfig in string or file format for the `--data` argument to generate fake data. Specify the number of prompt tokens at a minimum and optionally the number of output tokens and other parameters for variance in the length. For example, `--data "prompt_tokens=128"`, `--data "prompt_tokens=128,generated_tokens=128" `, or `--data "prompt_tokens=128,prompt_tokens_variance=10" `.
- `--data-type file`: File supports a file path or URL to a file for the `--data` argument. The file should contain data encoded as a CSV, JSONL, TXT, or JSON/YAML file with a single prompt per line for CSV, JSONL, and TXT or a list of prompts for JSON/YAML. For example, `--data "data.txt"` where data.txt contents are `"prompt1\nprompt2\nprompt3"`.
- `--data-type transformers`: Transformers supports a dataset name or file path for the `--data` argument. For example, `--data "neuralmagic/LLM_compression_calibration"`.
- `--max-seconds`: The maximum number of seconds to run each benchmark. The default is 120 seconds.
- `--max-requests`: The maximum number of requests to run in each benchmark.
For a complete list of supported CLI arguments, run the following command:
```bash
guidellm --help
```
For a full list of configuration options, run the following command:
```bash
guidellm-config
```
See the [GuideLLM Documentation](#Documentation) for further information.
## Resources
### Documentation
Our comprehensive documentation provides detailed guides and resources to help you get the most out of GuideLLM. Whether just getting started or looking to dive deeper into advanced topics, you can find what you need in our [full documentation](https://github.com/neuralmagic/guidellm/tree/main/docs).
### Core Docs
- [**Installation Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/install.md) - This guide provides step-by-step instructions for installing GuideLLM, including prerequisites and setup tips.
- [**Architecture Overview**](https://github.com/neuralmagic/guidellm/tree/main/docs/architecture.md) - A detailed look at GuideLLM's design, components, and how they interact.
- [**CLI Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/cli.md) - Comprehensive usage information for running GuideLLM via the command line, including available commands and options.
- [**Configuration Guide**](https://github.com/neuralmagic/guidellm/tree/main/docs/guides/configuration.md) - Instructions on configuring GuideLLM to suit various deployment needs and performance goals.
### Supporting External Documentation
- [**vLLM Documentation**](https://vllm.readthedocs.io/en/latest/) - Official vLLM documentation provides insights into installation, usage, and supported models.
### Releases
Visit our [GitHub Releases page](https://github.com/neuralmagic/guidellm/releases) and review the release notes to stay updated with the latest releases.
### License
GuideLLM is licensed under the [Apache License 2.0](https://github.com/neuralmagic/guidellm/blob/main/LICENSE).
## Community
### Contribute
We appreciate contributions to the code, examples, integrations, documentation, bug reports, and feature requests! Your feedback and involvement are crucial in helping GuideLLM grow and improve. Below are some ways you can get involved:
- [**DEVELOPING.md**](https://github.com/neuralmagic/guidellm/blob/main/DEVELOPING.md) - Development guide for setting up your environment and making contributions.
- [**CONTRIBUTING.md**](https://github.com/neuralmagic/guidellm/blob/main/CONTRIBUTING.md) - Guidelines for contributing to the project, including code standards, pull request processes, and more.
- [**CODE_OF_CONDUCT.md**](https://github.com/neuralmagic/guidellm/blob/main/CODE_OF_CONDUCT.md) - Our expectations for community behavior to ensure a welcoming and inclusive environment.
### Join
We invite you to join our growing community of developers, researchers, and enthusiasts passionate about LLMs and optimization. Whether you're looking for help, want to share your own experiences, or stay up to date with the latest developments, there are plenty of ways to get involved:
- [**Neural Magic Community Slack**](https://neuralmagic.com/community/) - Join our Slack channel to connect with other GuideLLM users and developers. Ask questions, share your work, and get real-time support.
- [**GitHub Issues**](https://github.com/neuralmagic/guidellm/issues) - Report bugs, request features, or browse existing issues. Your feedback helps us improve GuideLLM.
- [**Subscribe to Updates**](https://neuralmagic.com/subscribe/) - Sign up for the latest news, announcements, and updates about GuideLLM, webinars, events, and more.
- [**Contact Us**](http://neuralmagic.com/contact/) - Use our contact form for general questions about Neural Magic or GuideLLM.
### Cite
If you find GuideLLM helpful in your research or projects, please consider citing it:
```bibtex
@misc{guidellm2024,
title={GuideLLM: Scalable Inference and Optimization for Large Language Models},
author={Neural Magic, Inc.},
year={2024},
howpublished={\url{https://github.com/neuralmagic/guidellm}},
}
```