
[Why use it](#-why-use-it) • [How to use it](#-how-to-use-it) • [FAQ](#-frequently-asked-questions) • [Who uses it](#-who-uses-it) • [Who we are](#-who-we-are) • [How to contribute](#%EF%B8%8F-how-to-contribute) • [License](#%EF%B8%8F-license) • [Spread the word!](#-spread-the-word)
🥘 Why use it
Many Search teams struggle with understanding "Why is my user doing this". They have great understanding of an incoming query and the documents returned, but no ability to connect that dot with an indicator of success, such as a click through event or add to cart event.
There are A LOT of tools out there for tracking events, Google Analytics, Snowplow, etc, but each is a bit different, and each tends to lock you in. None of them think about the needs of Search teams specifically either.
The User Behavior Insights standard attempts to provide a search focused standard that can operate across many platforms. There are implementations for
🪛 How to use it
UBI requires coordination between the client (a browser, a mobile app, etc) and the backend, which is documented using JSON Schema.
| JSON Schema | HTML Docs |
|---|---|
| query.request.schema.json | query.request.schema.html |
| query.response.schema.json | query.response.schema.html |
| event.schema.json | event.schema.html |
You just need to copy, download or reference one of the schema files to validate a UBI data structure, built as a JSON file from scratch, or a JSON generated previously (for example, these samples).
To get started, you can copy both schema and sample in an online validator like jsonschemavalidator.net or liquid-technologies.com/online-json-schema-validator. Make sure to just copy the UBI related portions, and not any of the search engine specific code. Here is the UBI portion from the file query-solr.json for example:
{
"ubi": "true",
"query_id": "xyz890",
"user_query": {
"query": "RAM memory",
"experiment": "supersecret",
"page": 1,
"filter": "productStatus:available"
}
}You also have implementations to validate a JSON file programmatically in almost every coding language.
:warning: The current UBI Schema has been designed using the 2020-12 Specification Draft: When choosing a validator, please, check if it's compliant with the 2020-12 Draft. You can get much more information about the JSON Schema Specification in json-schema.org.
The Schema is documented by itself, but it's much easier to get "the big picture" with a graphical representation:
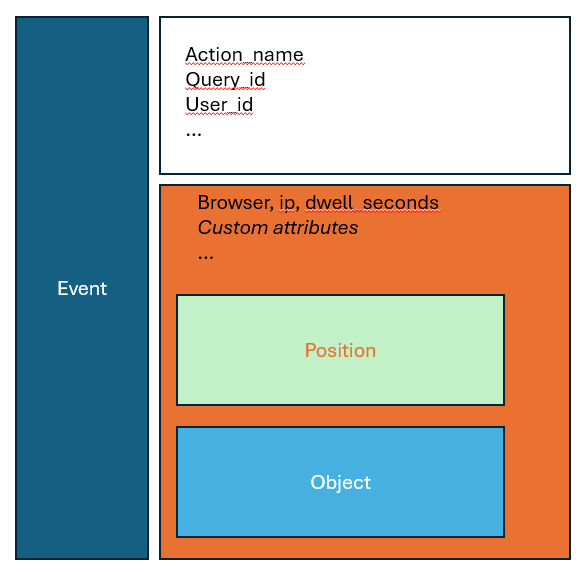
🤔 Frequently Asked Questions
How do I handle anonymous users?
We often want to track a specific identifer for a user, but then realize that we also want to connect those events to previously unauthenticated events. Therefore, we can't just plop in a explicit user id as the client_id attribute. Instead, you want to track something that is permanent, across the anonymous AND logged in session as the client_id. To make processing simpler you can store the explicit user identifier in the Event --> Event Attributes --> Additional Properties hash. Here is an example of user "abc" who clicked on item with sku "1234":
{
"action_name": "item_click",
"query_id": "00112233-4455-6677-8899-aabbccddeeff",
"message_type": "INFO",
"message": "User abc clicked sku 1234",
"event_attributes": {
"position":{},
"object": {
"object_id":"1234"
"object_id_field": "sku",
"user_id":"abc"
}
}
}In post processing, you can use the Client ID field to connect queries and events from the anonymous user to queries and events after they are logged in, and pluck the explicit user id from the detailed event_attributes information.
Where do I record my user id and item id?
If your user identification is stable, then feel free to use the Query Request --> Client ID and Event --> Client ID. Otherwise, see the above FAQ entry for how to handle it. The item ID is tracked for an event in the Event --> Object datastructure.
How can I correlate private sensitive data with public event tracking?
We often have sensitive data that is returned as part of the search process that changes quickly, and we would not want to expose that information in front end, even hidden!
For example, in ecommerce, we might want to track the margin that is earned on a product, but not pass that data back to the browser, just to collect it later in the events.
To do that, we introduce a cache into our architecture for this sensitive data:
sequenceDiagram
actor Alice
Alice ->> Browser: "I want a mobile phone"
Browser ->> API: "{user_search_query:mobile phone}"
API ->> SearchEngine: "q=mobile phone"
SearchEngine ->> UBI_db: Store queryId and SKUs of phones returned to user
SearchEngine->>API: Return QueryId and list of mobile phones by SKU with price and profit margin
API ->> Cache: Store Margins per Phone under QueryId and SKU
API->> Browser: QueryID and list of mobile phones by SKU with price
Alice->> Browser: "Click iPhone 15 Pro"
Browser->> API: Click Event with SKU and QueryId
API->> Cache: Look up Margin based on QueryId and SKU
API->> UBI_db: Store queryId and SKU and MarginAnother common reason is to have rich events, but reduce the volume of data passed over the wire to the client.
We sometimes refer to this shortcut architecture as "the Panama Canal", as in taking an extreme shortcut!
🏫 Learn More
- OpenSearchCon EU - User Behavior Insights
- Haystack Conf 2024 - Your Search Engine Needs a Memory
🎨 Who uses it
We are trialing UBI as an interchangeable format to simplify understanding of what users are doing and are looking for more collaborators.
🤓 Who we are
As common in new projects, the individual or group who started the project also administers the project, establishes its vision, and controls permissions to merge code into it. We are thinking about how to establish a more robust governance structure.
⚙️ How to contribute
UBI is an open-source project. We are committed to a fully transparent development process and appreciate highly any contributions. Whether you are helping us fix bugs, proposing new features, improving our documentation or spreading the word - we would love to have you as part of the UBI community.
Please refer to our Contribution Guidelines and Code of Conduct.
⚖️ License
UBI is available under the Apache Software License, version 2.
🌟 Spread the word!
If you want to say thank you and/or support active development of UBI:
- Add a GitHub Star to the project!
- Contact Eric at epugh@opensourceconnections.com or Stavros at macrakis@gmail.com
Thanks so much for your interest in growing the reach of UBI!
This site was inspired by https://github.com/getmanfred/mac. Thank you!