
SEPAL
![]()

SEPAL is a cloud computing platform for geographical data processing. It enables users to quickly process large amount of data without high network bandwidth requirements or need to invest in high-performance computing infrastructure.
Currently available in the following languages:
| English | Français | Español |
|---|
You can contribute to the translation effort on our crowdin project.
Background
Reducing Emissions from Deforestation and Forest Degradation (REDD) is an effort to create a financial value for the carbon stored in forests, offering incentives for developing countries to reduce emissions from forested lands and invest in low-carbon paths to sustainable development. "REDD+" goes beyond deforestation and forest degradation, and includes the role of conservation, sustainable management of forests and enhancement of forest carbon stocks. The UN-REDD Programme is the United Nations collaborative initiative on Reducing Emissions from Deforestation and forest Degradation (REDD) in developing countries.
FAO, as a member of the UN-REDD Programme, is responsible for assisting countries in developing robust national forest monitoring systems (NFMS) and operational satellite land monitoring systems (SLMS) to help them to meet the measurement, reporting and verification (MRV) requirements of the REDD+. Furthermore, countries need help in establishing and maintaining a SLMS capable of producing the information required to make consequential decisions about forest management; decisions that promote sustainable forest management and can potentially mitigate the effects of global climate change on society. Specifically, a solution is needed to address the existing challenges countries face when developing forest monitoring systems, due to difficulties accessing and processing remotely sensed data; a key source of information for monitoring forest area and forest area change over large, often remote areas.
To tackle the problems mentioned above, FAO and Norway are collaborating on the System for Earth Observation Data Access, Processing and Analysis for Land Monitoring (SEPAL).
It consists of the following components:
- A powerful, cloud-based computing platform for big data processing and storage.
- Facilitated access to remote sensing data sources through a direct-access-interface to earth observation data repositories.
- A set of open-source software tools, capable of efficient data processing
- Related capacity development and technology transfer activities
The computing platform enables FAO national partners to process data quickly without locally maintained high performance computing infrastructures. The direct link to data repositories allows fast access to satellite imagery and other earth observation data for processing. The software tools, such as FAO’s Open Foris Geospatial Toolkit perform powerful image processing, are completely customizable and function similarly ‘on the cloud’ or on the desktop.
Screenshots





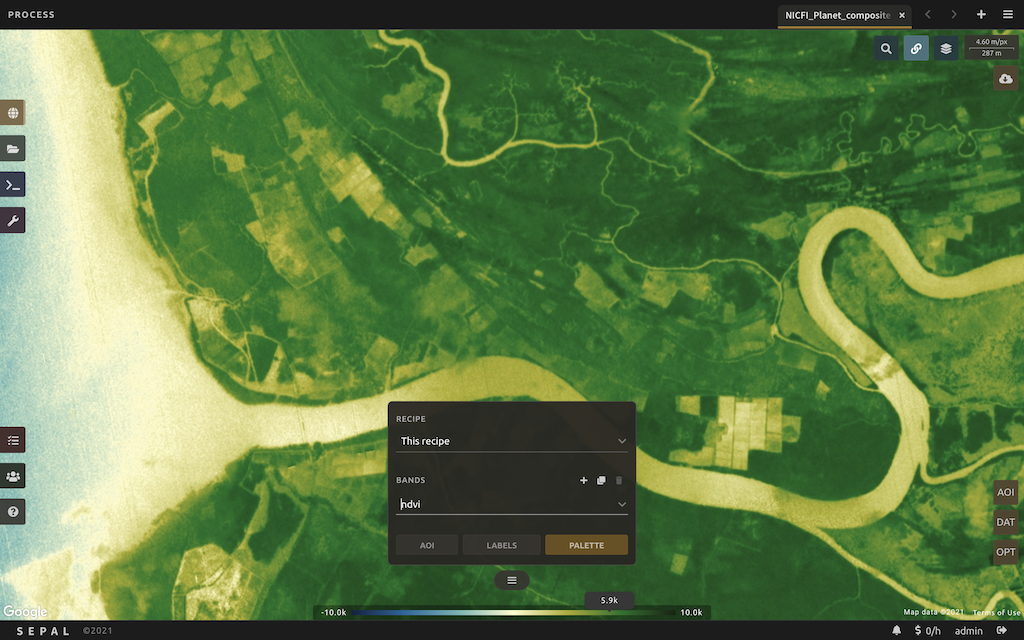


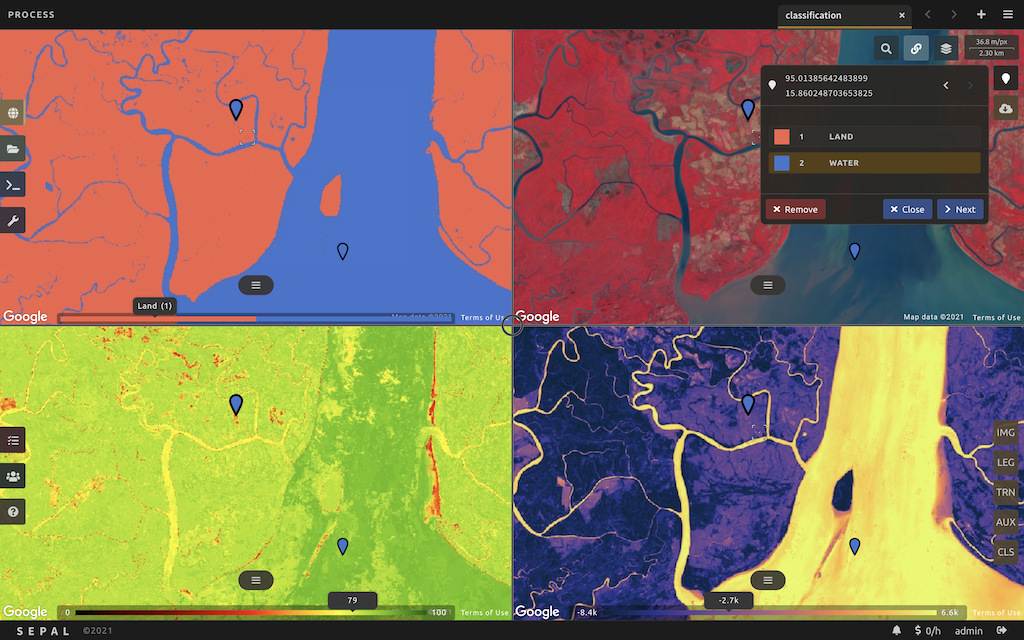




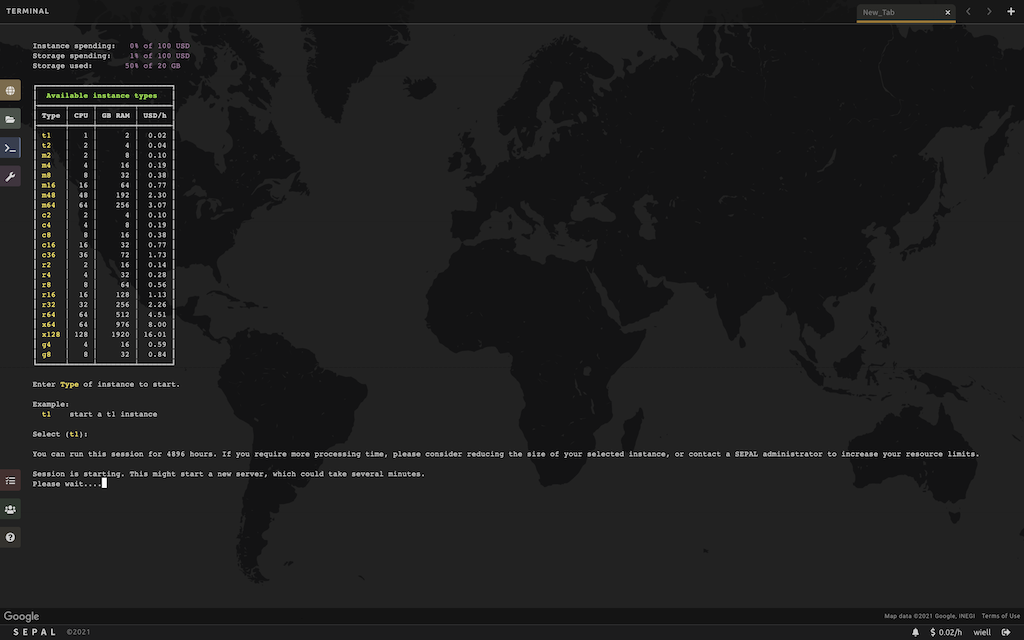

Architectural overview
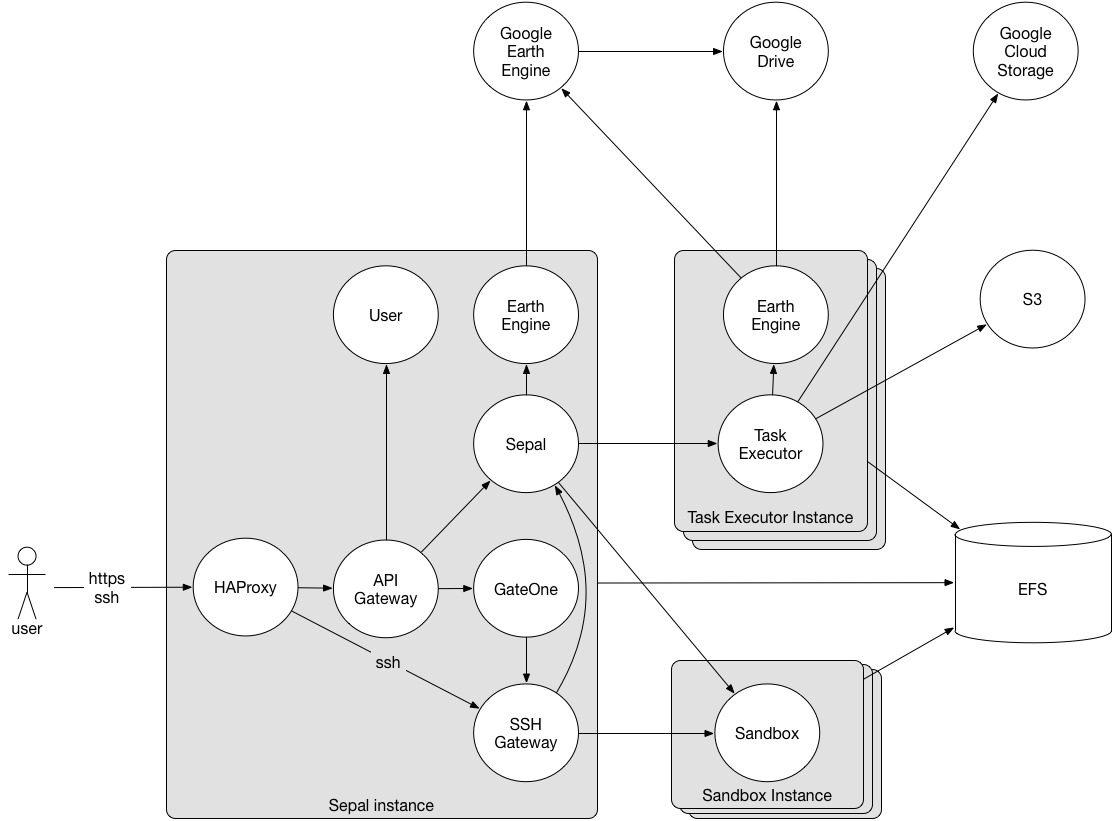
The core of the system is the SEPAL server and the user sandboxes. SEPAL server provides a web-based user-interface, where geospatial data from multiple providers can be searched, processing chains composed and executed, and geospatial data products visualized.
The user sandboxes are spaces where users get access to a number of geospatial data processing tools, such as those included in Open Foris Geospatial Toolkit and Orfeo Toolbox, and their own dedicated storage. SEPAL provides users SSH access to their respective sandbox. This can either be done directly with an SSH client, or through a provided web-based terminal. Web-based sandbox tools can be accessed over HTTP.
Sandboxes are implemented as Docker containers, which in addition to providing isolation between users, allows for very flexible deployment. Sandboxes are started when needed, and stopped when not used. This enables them to be deployed in a cluster of worker server instances, which can be dynamically scaled up and down based on demand.
Default AWS deployment
There are three types of server instances:
-
SEPAL servers, constantly running, one in each region where SEPAL is deployed. In addition to the features described above, they also are the entry points for user sandboxes. These instances can be fairly small and cheap, and don’t require much storage.
-
Worker instances, running user sandboxes and retrieving data (Landsat, Sentinel etc.). These instances are automatically launched when users access their sandboxes, and terminated when users disconnect. Users get to decide which instance type each sandbox session will be running on.
-
Operation server, one single instance. It tests and deploys the software, monitors the health of the system, and provides a user interface where user usage can be monitored, and disk/instance use quotas can be configured. This instance can be fairly small.
Users can at times require a lot of processing power and memory for their processing jobs. The large instances needed for this type of jobs are quite expensive. For instance, an r3.8xlarge (32 CPUs, 244 GiB memory) costs over 3 USD an hour, which adds up to more than 2,300 USD a month. When using such expensive instances, care have to be taken to use them efficiently, and not have them sitting idle at any time. To maximize the utility of the worker instances, SEPAL will automatically launch them when they are requested, and terminate them when they're not used anymore. For instance, if a user run a 10 hours processing job on an r3.8xlarge, the total cost would be 30 USD, with no money spent on an idling instance.
To limit the cost of operating SEPAL, each user has a configurable monthly budget to spend on sandbox sessions. For instance, given a monthly budget of 100 USD a user might have used 32 hours of r3.8xlarge, or 250 hours r3.large and 450 hours t2.large.
Another costly component is storage, where 1TB of EFS storage costs 300 USD a month. To limit storage costs, each user have configurable disk quota.
Components and services part of a SEPAL deployment
HAProxy - Off-the-shelf load balancer, allowing SEPAL to be clustered for availability. Run both SSH and HTTPS on port 443, to prevent firewalls from blocking SSH.
nginx - Off-the-shelf HTTP and reverse proxy server, proxying all SEPAL HTTP endpoints.
Xterm.js - Off-the-shelf web-based SSH client. Gives users SSH access to their Sandbox in a web browser.
Sepal server - Provides the system user interface.
Data provider - Service retrieving geospatial data from various external data providers.
Sandbox lifecycle manager - Service managing the user sandboxes. It deploys them on demand when users requests access, and un-deploys them as soon as a user disconnects from them.
Sandbox SSH gateway - Service responsible for dynamically tunnelling SSH connections to users sandbox, while notifying the sandbox lifecycle manager on connects and disconnects.
Sandbox web proxy - Service proxying HTTP connections to user sandboxes. It maintains HTTP sessions, and notifies the sandbox lifecycle manager on session creation and expiry.
Sandbox - The user sandboxes are spaces where users get access to a number of geospatial data processing tools. See table below for provided tools.
Software deployed on each users sandbox:
Open Foris Geospatial Toolkit - A collection of command-line utilities for processing of geospatial data.
GDAL - A translator library for raster and vector geospatial data formats.
R - Language for statistical computing and graphics.
RStudio Server - An IDE for R in a web browser.
Orfeo ToolBox - Library for remote sensing image processing.
OpenSARKit - Tools for Automatic Preprocessing of SAR Imagery.
Build and Release
The project is under active development, and the build and release process is still in flux, so these instructions will change, and improve, over time.
Prerequisites
In order to build and run the SEPAL system, a Linux or macOS installation is needed. The end-users on the other hand, are of course free to use whatever Operating system they prefer, including Windows.
In addition to this, the following software must be installed:
Java, Maven, and Ansible. If you want to run the system locally, you need Vagrant, and to deploy on Amazon Web Services EC2 instances, you need an AWS account.
Configuration
TBD
Build
TBD
Deploy
TBD