Wine2Vec
This project attempts to find similar wines based on user-written "tasting notes" from the website CellarTracker. Tasting notes are similar to wine reviews, but the idea is for each user to describe their experience drinking the wine and try to verbalize what they thought the the wine tasted like. Using TFIDF and Word2Vec I project the tasting notes written for each wine into a vector, and can then compare wine similarities based on the cosine distance between vectors. With a lack of "ground truth" for wine similarity I relied on unsupervised learning techniques to verify that my results were logical and matched real-world experience.
Please see the presentation final slides at the following link:
Data Collection
I used ParseHub's web scraping platform to scrape data from cellartracker.com, then used Python's Pandas package for data cleaning and storage. I used ~730 thousand wine tasting notes written for ~30,800 wines scraped from CellarTracker.
Modeling
Term Frequency - Inverse Document Frequency
I started with TF-IDF "bag of words" analysis of the wine tasting notes. I found that many people were mentioning varietal and region names in their tasting notes contributing to some target leakage. Using K-means clustering I found that wines were clustering very neatly along their varietal types. For example most of the Pinot Noirs ended up in one cluster and most of the Cabernets in another cluster. After removing stopwords specific to wine eg. "Kirsch", "Crus", "Cab", and "Pinot", I found that clusters were still sensible with white wines and red wines cleanly separating, but particular varietals were not homogeneously due to leakage.
Word2Vec
I wanted to incorporate Word2Vec due to the property that word vectors encode semantic meaning and would enable me to search using compositions. Another property of Word2Vec word vectors allow for simple vector arithmetic operations that encode meaning. For instance I could create a vector for "XYZ Cabernet" - "red" + "white" to find the most similar white wine to a particular bottle of Cabernet. I used the gensim package and used the "skipgram" architecture, which trains a single-layer neural network to find word vectors that can predict nearby words ("context words") well. Because word vectors are trained to maximize the prediction of context words, words that are used in similar contexts will have similar word vectors eg. "outstanding" and "fantastic."
After training Word2Vec on my entire corpus I had a unique vector for each word. To create "wine vectors" I needed a way to aggregate word vectors that composed each tasting note. Using TF-IDF had already produced relative word importances within each tasting note, so rather than simply averaging or averaging by raw counts, I used the TF-IDF weights to create a weighted sum of the word vectors for the words that appeared in each tasting note. This weighted sum created wine vectors that were in the same dimensional space as word vectors, which meant vector arithmetic could be used to combine wine and word vectors.
Validation
T-SNE and NMF
To verify that these wine vectors made sense I relied on two methods: visualization and varietal-vs-varietal cosine distance comparison. To visualize my high-dimensional wine vectors I used the T-Distributed Stochastic Neighbor Estimation (T-SNE) algorithm. T-SNE attempts to find low dimensional representation of the data set which has the property that pairwise probability distributions in the low dimensional projection are close to those in high-dimensions. It does this by randomly moving points around in the low dimensional space until a satisfactory representation is found.
I then used Non-Negative Matrix Factorization to model latent topics in the wine tasting notes and looked at the top terms associated with each latent topic. Based on the top terms by topic, I found that these topics were very logical divisions in wine types: White Wines, Tannic Reds, Dark Reds, and Light Reds.
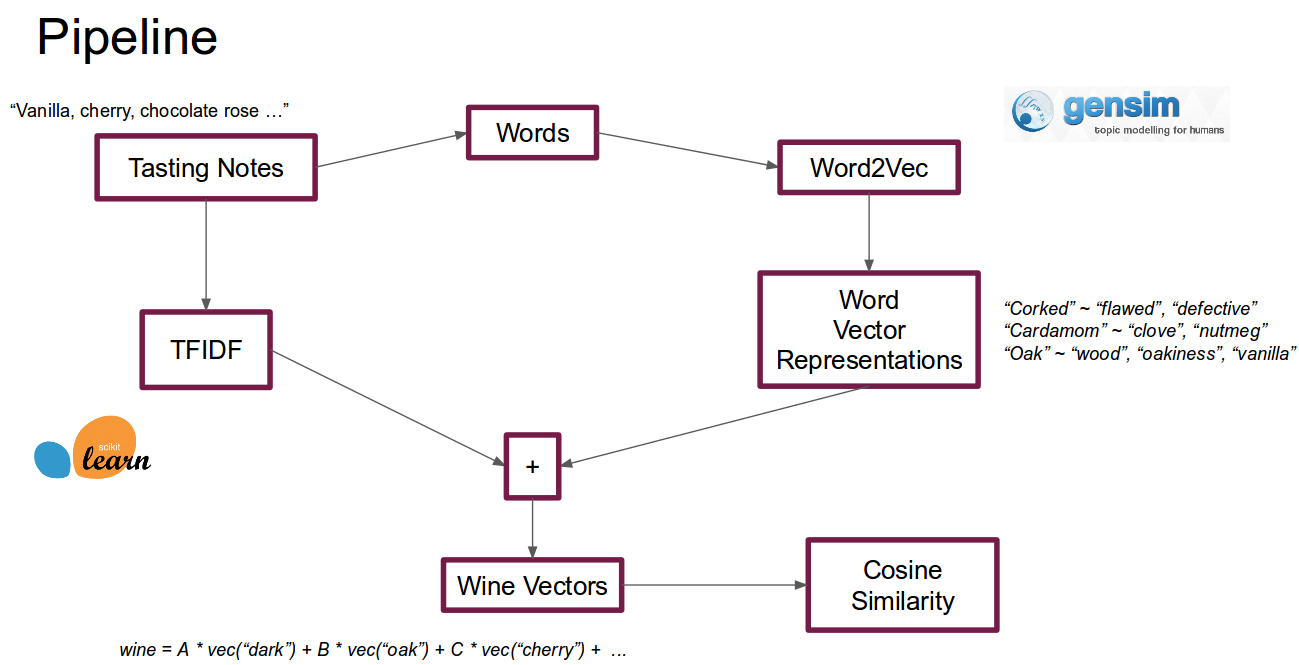
I overlayed the T-SNE 2-dimensional projections with the top NMF topic for each wine:
What I found was that white wines and red wines formed distinct clusters, the red wine cluster was far less homoegenous than the white wine cluster, and the different red wine "flavors" occupied different zones of the red wine cluster, but there was quite a bit of overlap. All of these matched my prior expectations, which gave me confidence there was logic to the resulting wine vectors.
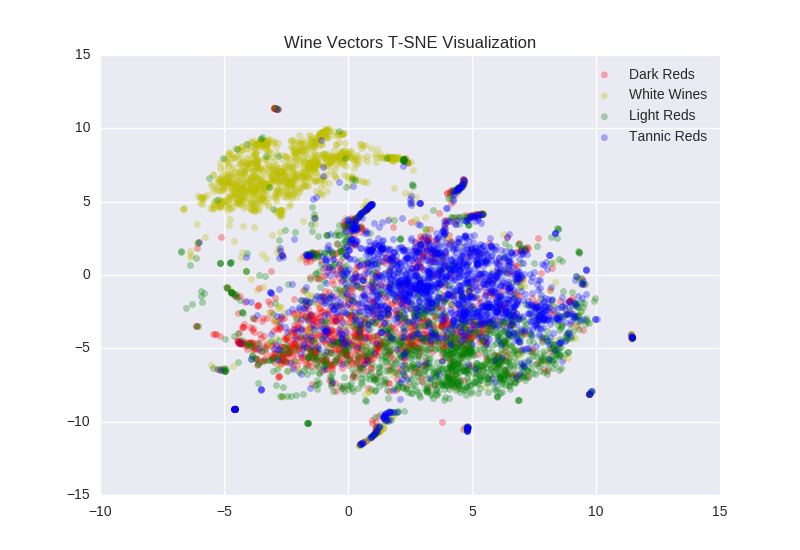
Varietal-vs-Varietal Cosine Distances
The next quality check I did on the wine vectors was to test a hypothesis I expected to be true. I expected varietals that are commonly accepted to be similar to have much smaller cosine distances than varietals which are accepted to be quite different. This is exactly what I saw, for example here are the cosine distances between two French red wine varietals which are commonly thought to be similar in taste:
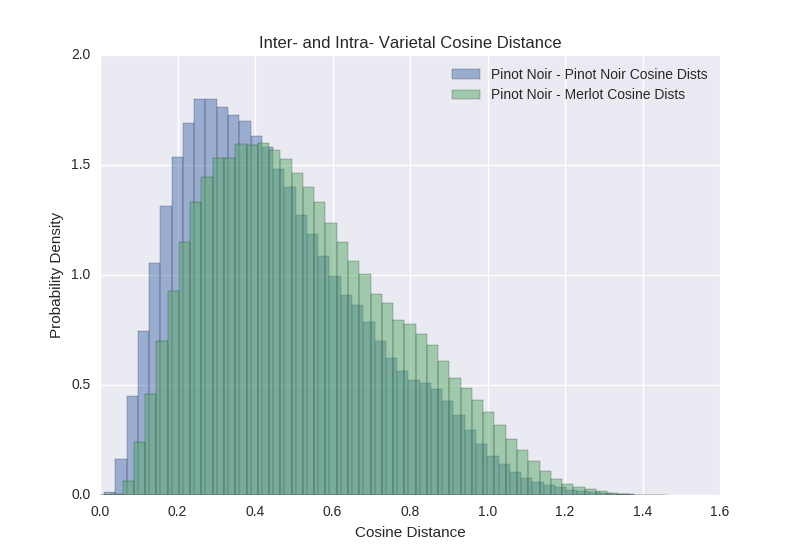
And cosine distances for two varietals which we would expect to taste quiet different, two French grapes one red and one white:
Application
https://phuse2.shinyapps.io/wine2vec/
With each wine converted into a vector, and the results validated using visualization and a common sense check on the inter-varietal cosine distances, I could then use item-item similarity to make recommendations. The simplest application is to just simply search for the most similar wines to a given wine.
Since the wines and words are projected into the same vector space, and Word2Vec vectors have the property that compositions of vectors generally obey syntactic and grammatical rules, the 'cooler' search you can do is on compositions.
For example let's say I really enjoyed an expensive French grape red wine - the 1990 Caymus Cabernet Sauvignon - but I wanted to try the most similar white wine to it. Adding the vector for 'white' and subtracting 'red' I can then find the most similar wine vectors to the composite vector. I find that the 2011 Kistler Chardonnay, 2005 S.A. Prum Graacher Riesling, and 2008 Kistler Chardonnay are the most similar white wines to my 1990 Caymus.