技术选型
前端
- React 开发框架
- 前端工程化:ESLint + Prettier + TypeScript + OpenAPI
- Ant Design 组件库
后端
- Java Spring Boot + MySQL + MyBatis Plus
- Picocli Java 命令行应用开发
- FreeMarker 模板引擎
- Caffeine + Redis 多级缓存
- 分布式任务调度系统
- 多种设计模式(命令模式、模板方法模式、双检锁单例模式)
- 项目优化(可移植性、可扩展性、健壮性、圈复杂度优化)
- 腾讯云 COS 对象存储
项目三步走
第一阶段:代码生成器(给用户的生成器)
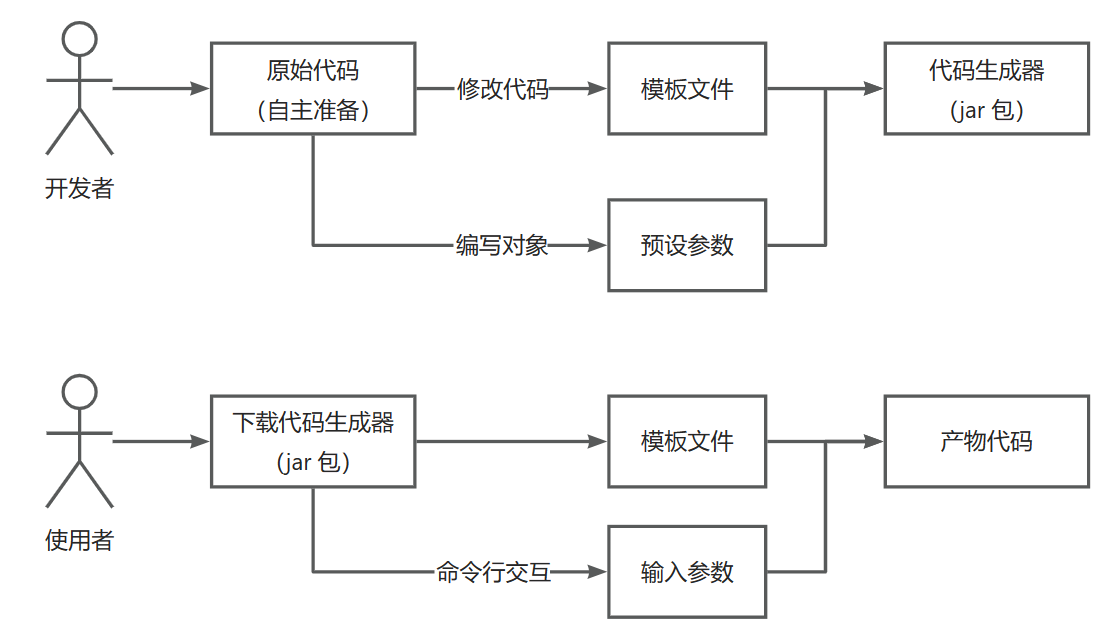
业务流程 1)准备用于制作代码生成器的原始代码(比如 Java ACM 模板项目),用于后续生成 2)开发者基于原始代码,设置参数、编写动态模板 3)制作可交互的命令行工具,支持用户输入参数,得到代码生成器 jar 包 4)用户得到代码生成器 jar 包,执行程序并输入参数,从而生成完整代码(eg. 若依)
第二阶段:(给开发者的生成器)
第三阶段:线上平台(在线分享)
第一阶段
使用Hutool:静态文件生成、进行文件复制等操作。
使用FreeMarker模板引擎:用"模板+数据模型"进行动态文件的生成。
使用Picocli:利用注解,开发基于命令行的代码生成器。支持可交互式输入。
使用命令模式:对generate、config、list三个参数的进行封装。优点:解耦请求发送者和接受者,让系统更加灵活、可扩展。由于每个操作都是一个独立的命令类,所以我们需要新增命令操作时,不需要改动现有代码。
使用定制化打包方式maven-assembly-plugin和脚本文件:可以在命令行运行jar包的Main类,生成所有代码文件。
阶段总结:得到一个基于命令行的代码生成器。
第二阶段
实现流程
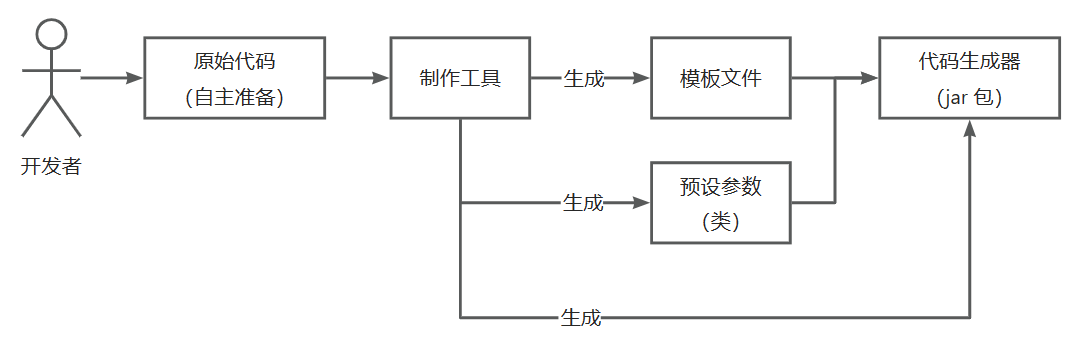
1.制作一个”可以生成acm-template项目的生成器”的生成器(给开发者的)
- 将所有在第一阶段的代码文件,都转换成模板文件和元信息的模式。
- 将Maven打包,脚本封装都用代码完成
2.功能优化
可移植性:元信息增加一个源文件路径,用来复制模板代码到代码生成器。
健壮性:增加校验类,自定义异常类。对输入的元信息进行校验。(MetaValidator类,主要是做了判空和赋默认值)
可扩展性:定义枚举类代替硬编码字符串(魔法值),使用模板方法定义生成器流程(父类定义一套流程,子类有不同的实现细节)
3.制作一个springboot-init项目的代码生成器(一个博客模板项目)
需要实现的需求:
- 替换生成的代码包名(已经实现)
- 控制是否生成帖子相关功能
- 控制是否需要开启跨域
- 自定义 Knife4jConfig 接口文档配置
- 自定义 MySQL 配置信息
- 控制是否开启 Redis
- 控制是否开启 Elasticsearch
这些需求所对应的功能:
- 一个模型参数对应某个文件是否生成
- 一个模型参数对应多个文件是否生成
- 一个模型参数同时控制多处代码修改以及文件是否生成(通过文件分组功能实现)
- 定义一组相关的模型参数,控制代码修改或文件生成
- 定义一组相关的模型参数,并能够通过其他的模型参数控制是否需要输入该组参数(通过模型分组功能实现)
4.功能优化
1)分布制作:根据雪花算法生成唯一ID,多次生成时追踪这个ID
2)文件筛选:设置过滤规则,在模型参数中使用,可以帮助用户筛选文件。
- 过滤范围:根据文件名称(fileName)、或者文件内容(fileContent)过滤。
- 过滤规则:包含 contains、前缀匹配 startsWith、后缀匹配 endsWith、正则 regex、相等 equals。
3)文件/模型分组
阶段总结
第二阶段除了大量的功能优化以外,还修复了10个左右的bug(幺蛾子)。比如FreeMarker和Mybatis的变量命名冲突、动态文件被重新生成为静态等。详细内容记录在定制化-流程与问题.md。
这一阶段,项目实现:根据一或多个json文件生成“ftl项目模板”,并用代码生成相应的“生成器”(Generator,将第一阶段做的内容定制化得到)。两者结合得到最终的定制化springboot-init项目。
第三阶段
需求分析
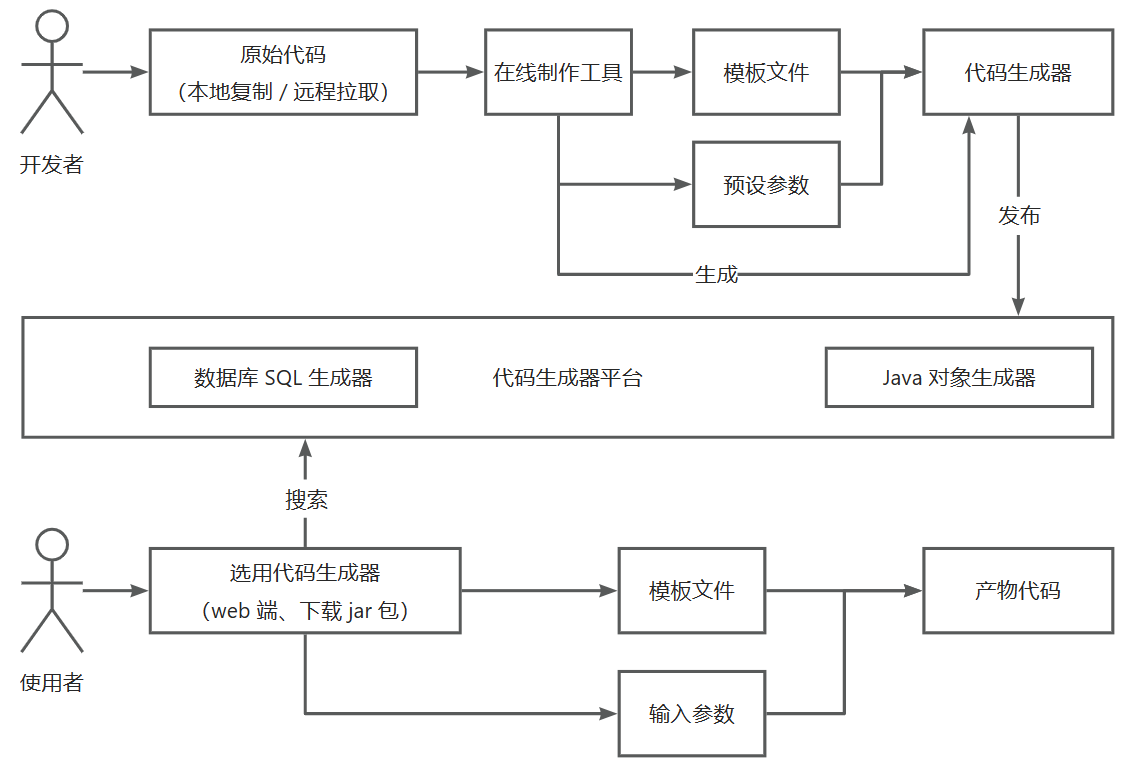
经过了前两个阶段本地项目的开发,其实绝大多数复杂的业务逻辑已经完成,接下来我们要实现项目的线上化就很简单了。 首先思考,我们要对哪些内容进行线上化?要让用户线上使用哪些能力呢? 主要分为 2 个方面: 1)数据线上化 包括:
- 元信息线上化,即把元信息配置保存到数据库中。
- 项目模板线上化,即把静态文件和模板文件保存到存储服务上
- 代码生成器线上化,即把代码生成器产物包保存到存储服务上
2)功能线上化 包括:
- 在线查看生成器的信息
- 在线使用生成器
- 在线使用生成器制作工具
总结一下,我们本阶段要开发的在线代码生成平台,支持用户在线搜索、使用、制作和分享各类代码生成器,帮助开发者提高定制化开发效率。
需要我们开发的功能如下:
- 用户注册、登录
- 管理员功能:用户管理、代码生成器管理(增删改查)
- 代码生成器搜索
- 代码生成器详情查看
- 代码生成器创建
- 代码生成器下载
- 代码生成器在线使用
- 代码生成器在线制作
大致的流程如下:
- 先完成库表设计,让数据库能支持存储代码生成器信息
- 实现基本的用户注册登录、增删改查等功能,让用户能够浏览代码生成器信息
- 实现文件上传下载功能,让用户能够上传和下载代码生成器产物包
- 实现在线使用代码生成器功能,让用户直接在线生成代码
- 实现在线制作代码生成器功能,提高用户制作生成器效率
- 项目优化,包括性能优化、存储优化等
性能优化
除了根据实际场景和性能瓶颈进行针对性优化,也可以根据用户访问流程进行通用优化:
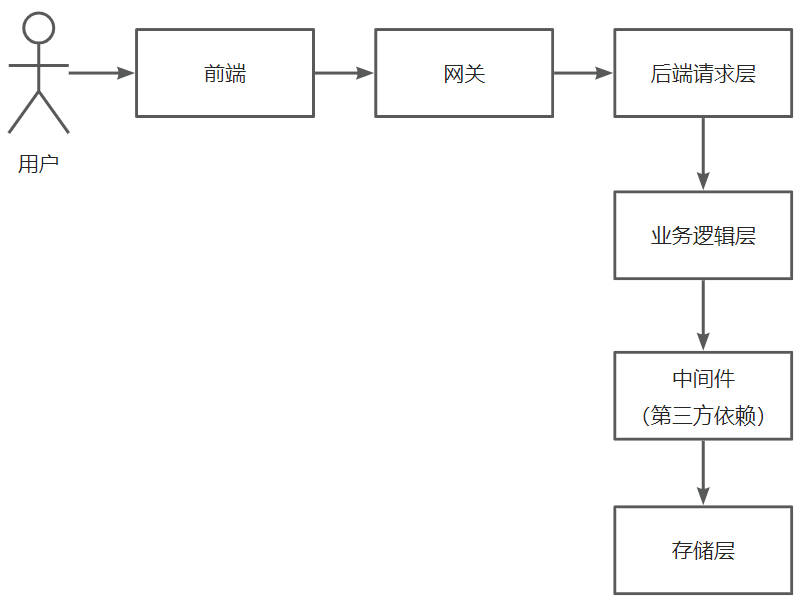
通用优化方法可分为
1)前端: 离线缓存:利用浏览器的缓存机制,请求过一次的资源就不用重复请求,提高页面加载速度。 请求合并:页面请求过多时,将多个小请求合并成一个大请求,减少网络开销。 懒加载:延迟加载页面的图片等元素,提高首屏加载速度。
2)网关: 负载均衡:负责接受请求,根据一定的路由算法转发到对应的后端系统,实现多个后端服务器分摊请求,增大并发量。 缓存:将后端返回的数据进行缓存,下次前端请求时,直接从网关获取数据,减少后端调用、提高数据获取速度。
3)后端请求层: 服务器优化:根据业务特性,选择性能更高的服务器并调整参数,比如 Nginx、Undertow 等。 微服务:将大型服务拆分为小型服务,并通过微服务网关进行转发,增大各服务的并发处理能力。
4)业务逻辑层: 异步化:将同步的业务逻辑改为异步,尽早响应,提高并发处理能力。 多线程:将复杂的操作拆分成多个任务,通过多线程并发执行,提高任务处理效率。
5)中间件(第三方依赖): 缓存:将数据库查询出的结果数据缓存到性能更高的服务(比如基于内存的 Redis 或本地),减少数据库的压力、并提高数据查询性能。 队列:使用消息队列,对系统进行解耦、或者将操作异步化,实现流量的削峰填谷。
6)存储层: 分库分表:数据量极大时,对数据库进行垂直或水平切分,提高数据库并发处理能力。 数据清理:定期清理无用或过期的数据,减少存储压力,必要时可以对数据进行备份转储。
阶段总结
这一阶段主要是将各种功能制作成一个线上的分享平台,也就是前后端开发
主要的工作为:开发后端接口,前端页面。实现对象存储,挖坑与填坑的功能线上化
第四阶段
项目上线与优化
上线后,为了提高网站的性能,优化存储方式,进行了如下操作