react-native-vosk - React ASR (Automated Speech Recognition)
Speech recognition module for react native using Vosk library
Installation
Library
npm install -S react-native-voskModels
Vosk uses prebuilt models to perform speech recognition offline. You have to download the model(s) that you need on Vosk official website Avoid using too heavy models, because the computation time required to load them into your app could lead to bad user experience. Then, unzip the model in your app folder. If you just need to use the iOS version, put the model folder wherever you want, and import it as described below. If you need both iOS and Android to work, you can avoid to copy the model twice for both projects by importing the model from the Android assets folder in XCode.
Experimental: Loading a model dynamically into the app storage, aside from the main bundle is a new and experimental feature. Would love for you all to test, and let us know if it is a viable option. If you choose to download a model to your app’s storage (preferably internal), you can pass the model directory path when calling vosk.loadModel(path).
To download and load a model as part of an app's Main Bundle, just do as follows:
Android
In Android Studio, open the project manager, right-click on your project folder and go to New > Folder > Assets folder.
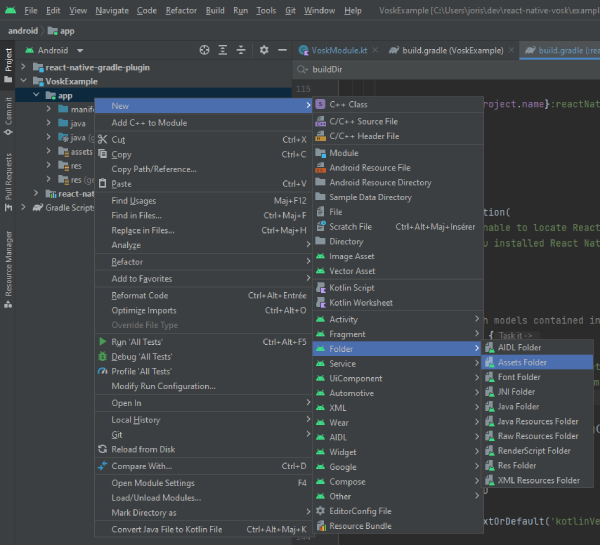
Then put the model folder inside the assets folder created. For our tests with the react-native-test-app module, we used the value ../../../../src/main/assets to let the asset folder live outside our node_modules. Adapt the path to your own needs.
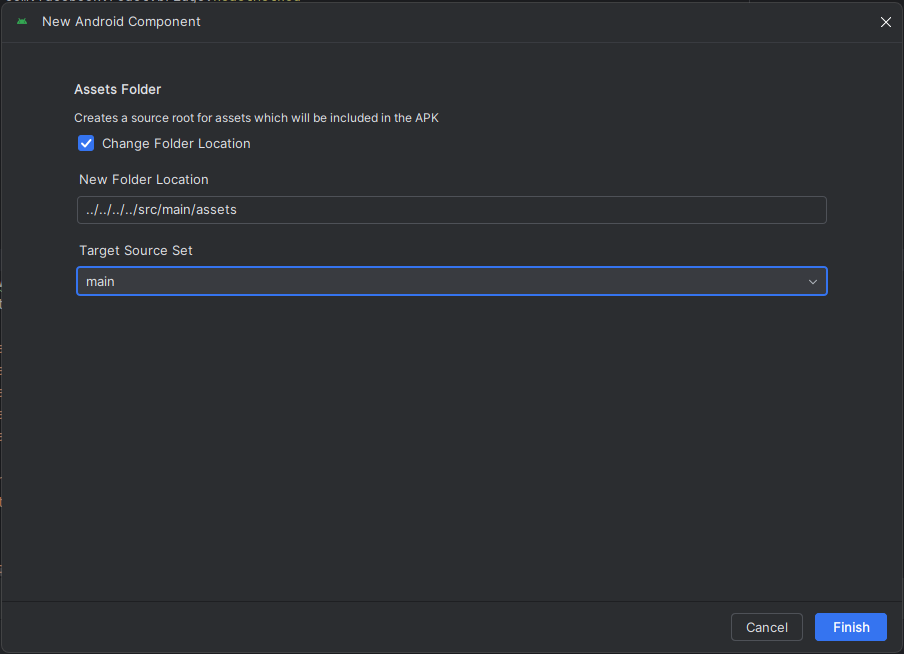
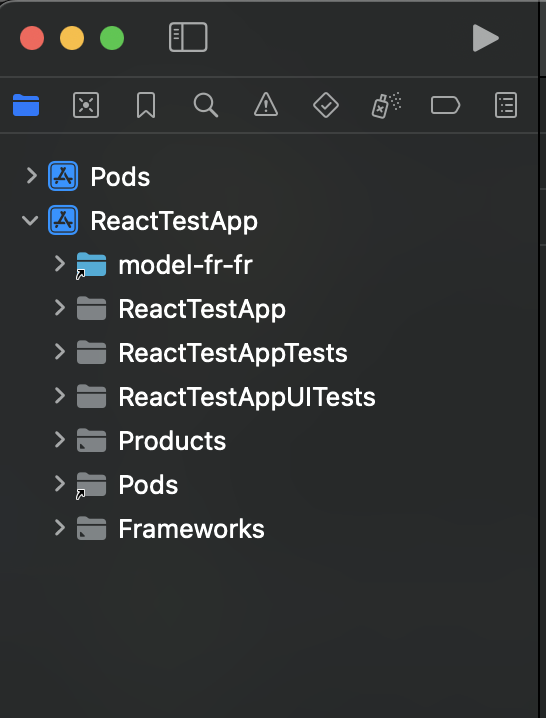
In your file tree it could be located in android\app\src\main\assets. So, if you downloaded the french model named model-fr-fr, you should access the model by going to android\app\src\main\assets\model-fr-fr. In Android studio, your project structure should be like that:
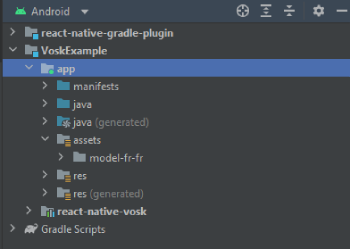
You can import as many models as you want.
iOS
In XCode, click on your App on the projects pannel, then go to the Build phases tab of settings pannel. Scroll down to the Copy bundle resources accordion. Click on the + button at the end of the list. Click on the Add other... button at the bottom of the prompt window.
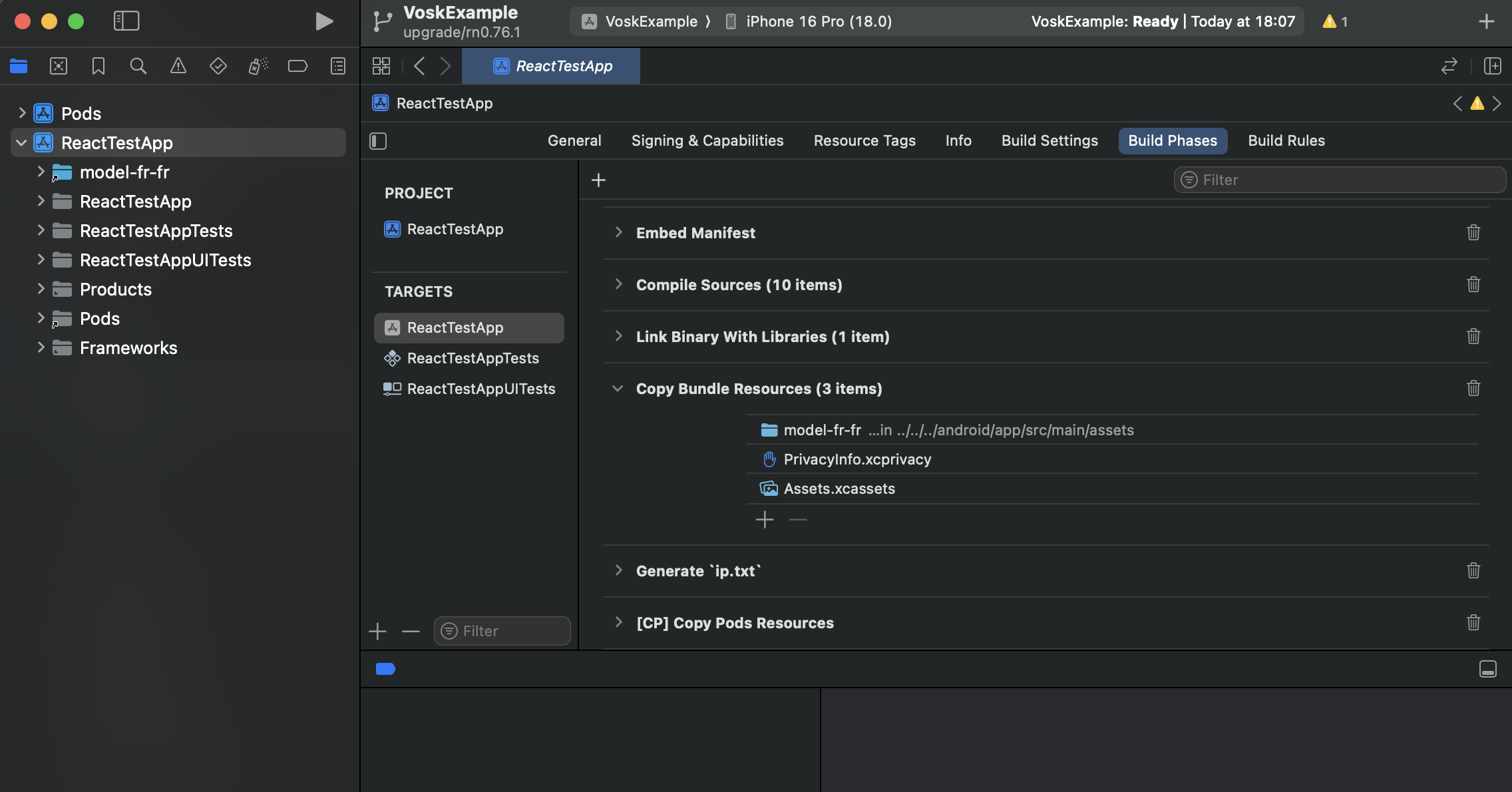
Then navigate to your model folder. You can navigate to your Android assets folder as mentionned before, and chose your model here. It will avoid to have the model copied twice in your project. If you don't use the Android build, you can just put the model wherever you want, and select it. Click on Open.
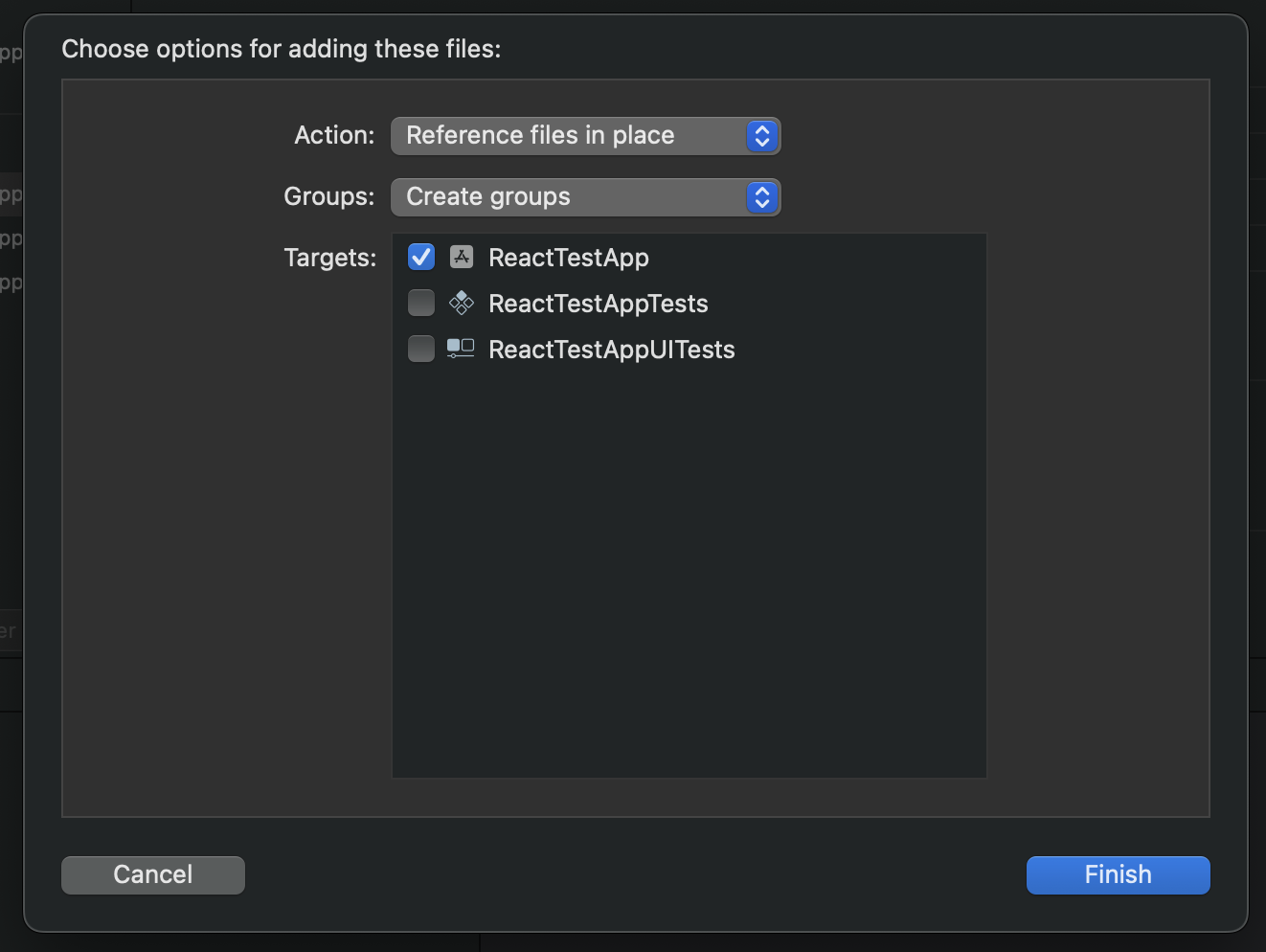
Check Copy items if needed. If you want to avoid having the model living twice in your app folders in order to reduce your bundle size, select Create folder references. That's all. The model folder should appear in your project. When you click on it, your project target should be checked (see below).
Usage
import Vosk from 'react-native-vosk';
// ...
const vosk = new Vosk();
vosk
.loadModel('model-en-en')
.then(() => {
const options = {
grammar: ['left', 'right', '[unk]'],
};
vosk
.start(options)
.then(() => {
console.log('Recognizer successfuly started');
})
.catch((e) => {
console.log('Error: ' + e);
});
const resultEvent = vosk.onResult((res) => {
console.log('A onResult event has been caught: ' + res);
});
// Don't forget to call resultEvent.remove(); to delete the listener
})
.catch((e) => {
console.error(e);
});Note that start() method will ask for audio record permission.
Experimental Loading via Path
- Primarily intended for models that are not included in the app’s Main Bundle.
Preliminary Steps
- Use a file system package to download and store a model from remote location
- react-native-file-access is one that we found to be stable, but this is a personal preference based on use
import Vosk from 'react-native-vosk';
// ...
const vosk = new Vosk();
const path = 'some/path/to/model/directory';
vosk
.loadModel(path)
.then(() => {
const options = {
grammar: ['left', 'right', '[unk]'],
};
vosk
.start(options)
.then(() => {
console.log('Recognizer successfuly started');
})
.catch((e) => {
console.log('Error: ' + e);
});
const resultEvent = vosk.onResult((res) => {
console.log('A onResult event has been caught: ' + res);
});
// Don't forget to call resultEvent.remove(); to delete the listener
})
.catch((e) => {
console.error(e);
});Methods
| Method | Argument | Return | Description |
|---|---|---|---|
loadModel |
path: string |
Promise<void> |
Loads the voice model used for recognition, it is required before using start method. |
start |
options: VoskOptions or none |
Promise<void> |
Starts the recognizer, an onResult() event will be fired. |
stop |
none |
none |
Stops the recognizer. Listener should receive final result if there is any. |
unload |
none |
none |
Unloads the model, also stops the recognizer. |
Types
| VoskOptions | Type | Required | Description |
|---|---|---|---|
grammar |
string[] |
No | Set of phrases the recognizer will seek on which is the closest one from the record, add "[unk]" to the set to recognize phrases striclty. |
timeout |
int |
No | Timeout in milliseconds to listen. |
Events
| Method | Promise return | Description |
|---|---|---|
onPartialResult |
The recognized word as a string |
Called when partial recognition result is available. |
onResult |
The recognized word as a string |
Called after silence occured. |
onFinalResult |
The recognized word as a string |
Called after stream end, like a stop() call |
onError |
The error that occured as a string or exception |
Called when an error occurs |
onTimeout |
void |
Called after timeout expired |
Examples
Default
vosk.start().then(() => {
const resultEvent = vosk.onResult((res) => {
console.log('A onResult event has been caught: ' + res);
});
});
// when done, remember to call resultEvent.remove();Using grammar
vosk
.start({
grammar: ['left', 'right', '[unk]'],
})
.then(() => {
const resultEvent = vosk.onResult((res) => {
if (res === 'left') {
console.log('Go left');
} else if (res === 'right') {
console.log('Go right');
} else {
console.log("Instruction couldn't be recognized");
}
});
});
// when done, remember to call resultEvent.remove();Using timeout
vosk
.start({
timeout: 5000,
})
.then(() => {
const resultEvent = vosk.onResult((res) => {
console.log('An onResult event has been caught: ' + res);
});
const timeoutEvent = vosk.onTimeout(() => {
console.log('Recognizer timed out');
});
});
// when done, remember to clean all listeners;Complete example
Contributing
See the contributing guide to learn how to contribute to the repository and the development workflow.
License
MIT