Enhancing Novel Object Detection via Cooperative Foundational Models
![]()
![]()
Rohit K Bharadwaj, Muzammal Naseer, Salman Khan, Fahad Khan
![]()
Official code for our paper "Enhancing Novel Object Detection via Cooperative Foundational Models"
:rocket: News
- (Feb 19, 2024)
- Added inference code to detect LVIS class vocab (1203 classes) on custom images.
- (Dec 24, 2023)
- Project website with additional qualitative visualizations is now live at https://rohit901.github.io/coop-foundation-models/
- (Dec 19, 2023)
- Code for our method on novel object detection, and open-vocabulary detection setting has been released.
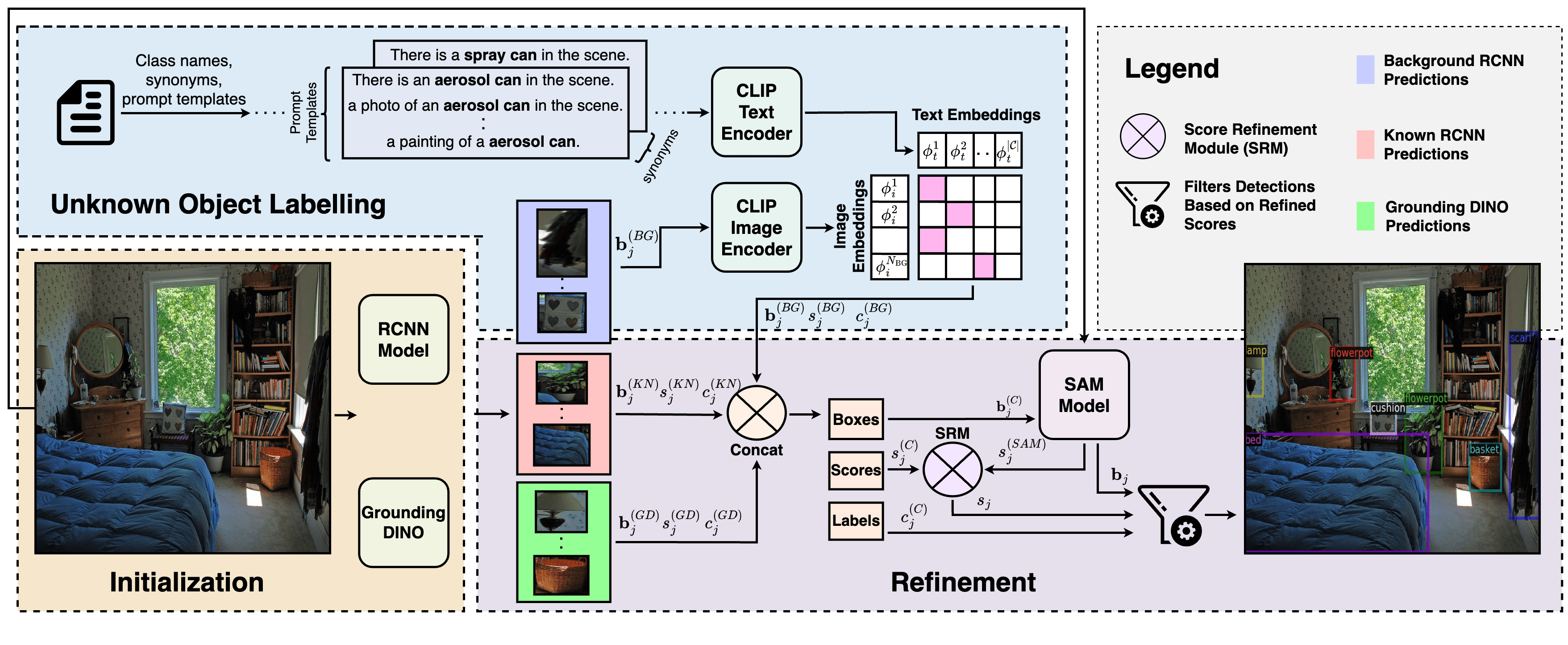
Abstract: In this work, we address the challenging and emergent problem of novel object detection (NOD), focusing on the accurate detection of both known and novel object categories during inference. Traditional object detection algorithms are inherently closed-set, limiting their capability to handle NOD. We present a novel approach to transform existing closed-set detectors into open-set detectors. This transformation is achieved by leveraging the complementary strengths of pre-trained foundational models, specifically CLIP and SAM, through our cooperative mechanism. Furthermore, by integrating this mechanism with state-of-the-art open-set detectors such as GDINO, we establish new benchmarks in object detection performance. Our method achieves 17.42 mAP in novel object detection and 42.08 mAP for known objects on the challenging LVIS dataset. Adapting our approach to the COCO OVD split, we surpass the current state-of-the-art by a margin of 7.2 AP50 for novel classes.
:trophy: Achievements and Features
- We establish state-of-the-art results (SOTA) in novel object detection on LVIS, and open-vocabulary detection benchmark on COCO.
- We propose a simple, modular, and training-free approach which can detect (i.e. localize and classify) known as well as novel objects in the given input image.
- Our approach easily transforms any existing closed-set detectors into open-set detectors by leveraging the complimentary strengths of foundational models like CLIP and SAM.
- The modular nature of our approach allows us to easily swap out any specific component, and further combine it with existing SOTA open-set detectors to achieve additional performance improvements.
:hammer_and_wrench: Setup and Installation
We have used python=3.8.15, and torch=1.10.1 for all the code in this repository. It is recommended to follow the below steps and setup your conda environment in the same way to replicate the results mentioned in this paper and repository.
- Clone this repository into your local machine as follows:
git clone git@github.com:rohit901/cooperative-foundational-models.gitor
git clone https://github.com/rohit901/cooperative-foundational-models.git - Change the current directory to the main project folder (cooperative-foundational-models):
cd cooperative-foundational-models - To install the project dependencies and libraries, use conda and install the defined environment from the .yml file by running:
conda env create -f environment.yml - Activate the newly created conda environment:
conda activate coop_foundation_models - Install the Detectron2 v0.6 library via pip:
python -m pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu113/torch1.10/index.html
Datasets
To download and setup the required datasets used in this work, please follow these steps:
- Download the COCO2017 dataset from their official website: https://cocodataset.org/#download. Specfically, download
2017 Train images,2017 Val images,2017 Test images, and their annotation files2017 Train/Val annotations. - Download the LVIS v1.0 annotations from: https://www.lvisdataset.org/dataset. There is no need to download images from this website as LVIS uses the same COCO2017 images. Specifically download the annotation files corresponding to the training set (1GB), and validation set (192 MB).
- Download extra/custom annotation files for COCO open-vocabulary splits from: COCO-OVD-Annotations, specifically download both
ovd_instances_train2017_base.json, andovd_instances_val2017_basetarget.json. - Download extra/custom annotation file for
lvis_val_subsetdataset from: LVIS-Val-Subset, specifically downloadlvis_v1_val_subset.json. -
Detectron2 requires you to setup the datasets in a specific folder format/structure, for that it uses the environment variable
DETECTRON2_DATASETSwhich is set equal to the path of the location containing all the different datasets. The file structure ofDETECTRON2_DATASETSshould be as follows:coco/annotations/instances_train2017.jsoninstances_val2017.jsonovd_instances_train2017_base.jsonovd_instances_val2017_basetarget.json..other coco annotation json files (optional)..train2017/val2017/test2017/lvis/lvis_v1_val.jsonlvis_v1_train.jsonlvis_v1_val_subset.json
The above file structure can also be seen from this onedrive link: link. Thus, the value for
DETECTRON2_DATASETSordetectron2_dirin our code file should be the absolute path to thedatasetsdirectory which follows the above structure.Model Weights
All the pre-trained model weights can be downloaded from this link: model weights. The folder contains the following model weights:
- GDINO_weights.pth: Grounding DINO model weights used in both Novel Object Detection, and Open Vocabulary Detection tasks. Edit the key corresponding to
gdino_checkpointinparams.jsonfile to point to this file. - SAM_weights.pth Segment Anything Model (SAM) weights used in both Novel Object Detection, and Open Vocabulary Detection tasks. Edit the key corresponding to
sam_checkpointinparams.jsonfile to point to this file. - maskrcnn_v2 Folder containing the weights of trained Mask-RCNN V2 model on COCO datset. These weights are used only in Novel Object Detection task. Do not rename the folder name or the model weight inside the folder, edit the key corresponding to
rcnn_weight_dirinscripts/novel_object_detection/params.jsonfile to point to this folder. - moco_v2_800ep_pretrain.pkl Initial pre-trained checkpoint for Mask-RCNN. These are used when training Mask-RCNN from scratch on the COCO OVD data split, and thus only used in Open Vocabulary Detection task. Edit the value of
CHECKPOINT_PATHinscripts/open_vocab_detection/train_mask_rcnn/train.batchto point to this file. - MaskRCNN_COCO_OVD Folder containing the weights of trained Mask-RCNN model on COCO OVD data split. These weights are used only to evaluate performance in Open Vocabulary Detection task. Do not rename folder name or model weight inside the folder, edit the key corresponding to
rcnn_weight_dirinscripts/open_vocab_detection/evaluate_method/params.jsonfile to point to this folder.
:mag_right: Novel Object Detection on LVIS Val Dataset
| Method | Mask-RCNN | GDINO | VLM | Novel AP | Known AP | All AP |
|---|---|---|---|---|---|---|
| K-Means | - | - | - | 0.20 | 17.77 | 1.55 |
| Weng et al | - | - | - | 0.27 | 17.85 | 1.62 |
| ORCA | - | - | - | 0.49 | 20.57 | 2.03 |
| UNO | - | - | - | 0.61 | 21.09 | 2.18 |
| RNCDL | V1 | - | - | 5.42 | 25.00 | 6.92 |
| GDINO | - | ✔ | - | 13.47 | 37.13 | 15.30 |
| Ours | V2 | ✔ | SigLIP | 17.42 | 42.08 | 19.33 |
Table 1: Comparison of object detection performance using mAP on the lvis_val dataset.
To replicate our results from the above table (i.e. Table 1 from the main paper):
-
Modify
scripts/novel_object_detection/params.jsonfile:- Edit the key
detectron2_dirand set it following instructions in Datasets - Edit the key
sam_checkpointand set the path to the downloaded fileSAM_weights.pth - Edit the key
gdino_checkpointand set the path to the downloaded fileGDINO_weights.pth - Edit the key
rcnn_weight_dirand set the path to the downloaded foldermaskrcnn_v2[NOTE: DO NOT put a trailing slash]
- Edit the key
-
Run the following script from the main project directory as follows:
python scripts/novel_object_detection/main.pyThe above script periodically saves the predictions output in the
outputsdirectory which is automatically created in the project level folder (i.e.cooperative-foundational-models/outputs). After executing the above script, the results will be printed to the console. Further, the final combined predictions of all the 19809 images in LVIS val dataset is saved asinstances_predictions.pth, and can be used withscripts/novel_object_detection/evaluate_results_from_predictions.pyto compute the final results.
| NOTE: We were able to get slightly better overall result with our method using the code in this repository compared to the reported results in the paper: | Method | Known AP | Novel AP | ALL AP |
|---|---|---|---|---|
| Ours (Paper) | 42.08 | 17.42 | 19.33 | |
| Ours (GitHub) | 45.43 | 17.25 | 19.43 |
Inference on Custom Images
To detect LVIS class vocab (1203 classes) on your custom images:
- Please follow the previous instructions to properly setup the data,
params.json, and the environment. - Run
python scripts/novel_object_detection/inference_single_image.py --image_path custom_image.jpg, you can replace custom_image.jpg with your own image and change the path accordingly.
The above script by default generates bounding box visualization of top-5 high scoring boxes. You may change the top-k visualization parameter by modifying the script. Alternatively, you may also choose to visualize the outputs based on confidence score threshold.
:medal_military: Open Vocabulary Detection on COCO OVD Dataset
| Method | Backbone | Use Extra Training Set | Novel AP50 |
|---|---|---|---|
| OVR-CNN | RN50 | ✔ | 22.8 |
| ViLD | ViT-B/32 | ✘ | 27.6 |
| Detic | RN50 | ✔ | 27.8 |
| OV-DETR | ViT-B/32 | ✘ | 29.4 |
| BARON | RN50 | ✘ | 34 |
| Rasheed et al | RN50 | ✔ | 36.6 |
| CORA | RN50x4 | ✘ | 41.7 |
| BARON | RN50 | ✔ | 42.7 |
| CORA+ | RN50x4 | ✔ | 43.1 |
| **Ours*** | RN101 + SwinT | ✘ | 50.3 |
Table 2: Results on COCO OVD benchmark. *Our approach with GDINO, SigLIP, and Mask-RCNN trained on COCO OVD split.
To replicate our results from the above table (i.e. Table 2 from the main paper):
-
Obtain the trained Mask-RCNN model weights on COCO OVD dataset split.
- Train the Mask-RCNN model from scratch:
- Edit the values of
DETECTRON2_DATASETS,CHECKPOINT_PATHinscripts/open_vocab_detection/train_mask_rcnn/train.batch - Start training by running:
bash scripts/open_vocab_detection/train_mask_rcnn/train.batch
- Edit the values of
- Alternatively, download the pre-trained weights of Mask-RCNN trained on COCO OVD from Model Weights, and edit
detectron2_dir,sam_checkpoint,gdino_checkpoint, andrcnn_weight_dirvalues inscripts/open_vocab_detection/evaluate_method/params.jsonaccordingly. Forrcnn_weight_dirset the path to the downloaded folderMaskRCNN_COCO_OVDwithout trailing slash.
- Train the Mask-RCNN model from scratch:
-
Run the following script from main project directory as follows:
python scripts/open_vocab_detection/evaluate_method/main.py
After executing the above script, the results will be displayed on the console. Ensure you follow the proper installation and setup steps mentioned in Datasets, and Model Weights.
:framed_picture: Qualitative Visualization
| RNCDL | GDINO | RCNN_CLIP | Ours |
|---|---|---|---|
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
To see additional and higher resolution visualizations, please visit the project website
:email: Contact
Should you have any questions, please create an issue in this repository or contact at rohit.bharadwaj@mbzuai.ac.ae
:pray: Acknowledgement
We thank the authors of GDINO, SAM, CLIP, and RNCDL for releasing their code.
:black_nib: Citation
If you found our work helpful, please consider starring the repository ⭐⭐⭐ and citing our work as follows:
@misc{bharadwaj2023enhancing,
title={Enhancing Novel Object Detection via Cooperative Foundational Models},
author={Rohit Bharadwaj and Muzammal Naseer and Salman Khan and Fahad Shahbaz Khan},
year={2023},
eprint={2311.12068},
archivePrefix={arXiv},
primaryClass={cs.CV}
}